爬虫学习——网页解释器简介
2021-07-01 09:06
阅读:803
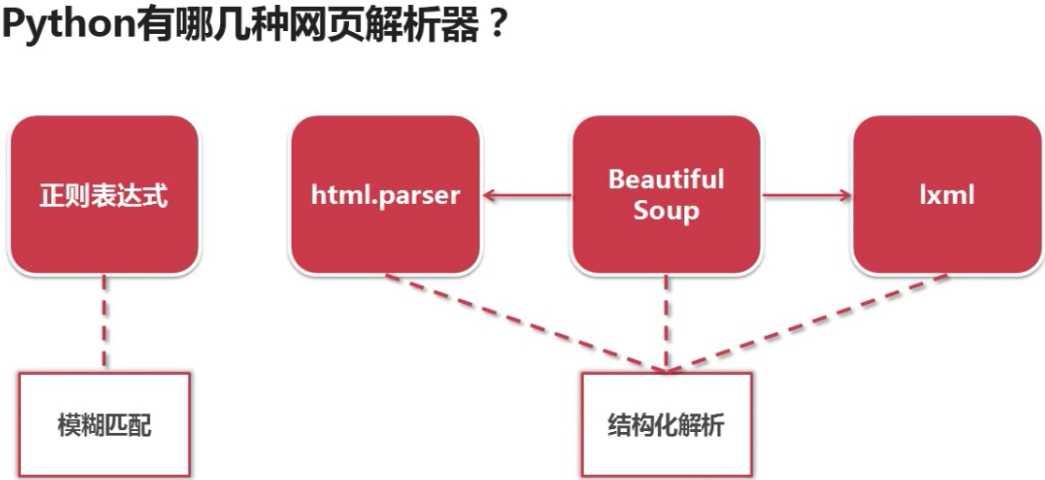
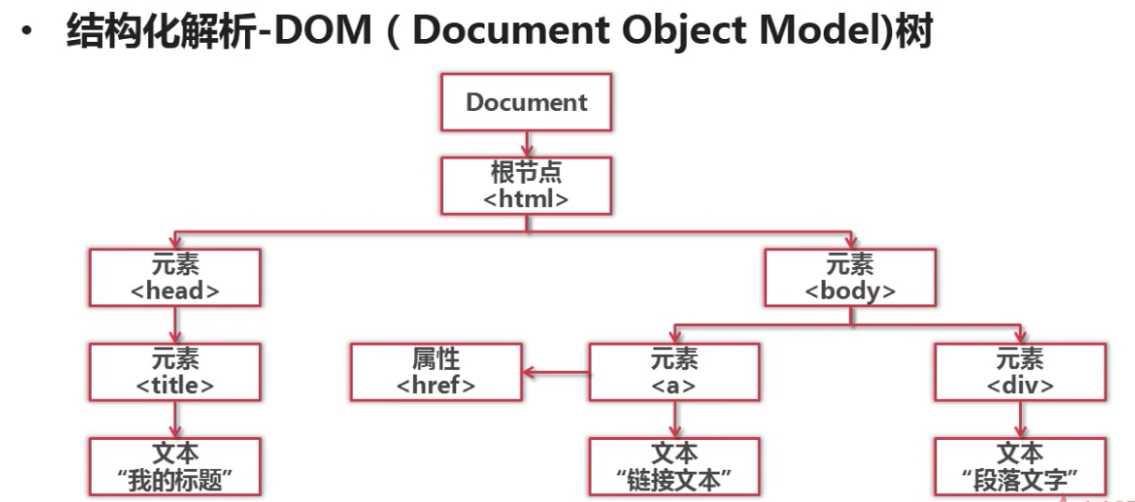
标签:XML 表达式 soup 上下 使用 python ima blog 优点 一、Python的网页解析器 优点:看起来比较直观 缺点:若文档比较复杂,这种解析方式会显得很麻烦 2.html.parser:此为python自带的解析器 3.lxml:第三方插件解析器,可解析html和xml网页 4.Beautiful Soup:强大的第三方插件解析器,可使用html.parser和lxml解析器 其中正则表达式采用模糊匹配的表达方式;html.parser、lxml、Beautiful Soup采用结构化解析的方式 二、什么是结构化解析 将整个网页文档加载成一个DOM树,就是将文档转化为DOM树模型,以树的方式进行上下级的遍历和访问。 爬虫学习——网页解释器简介 标签:XML 表达式 soup 上下 使用 python ima blog 优点 原文地址:http://www.cnblogs.com/ryuuku/p/7133432.html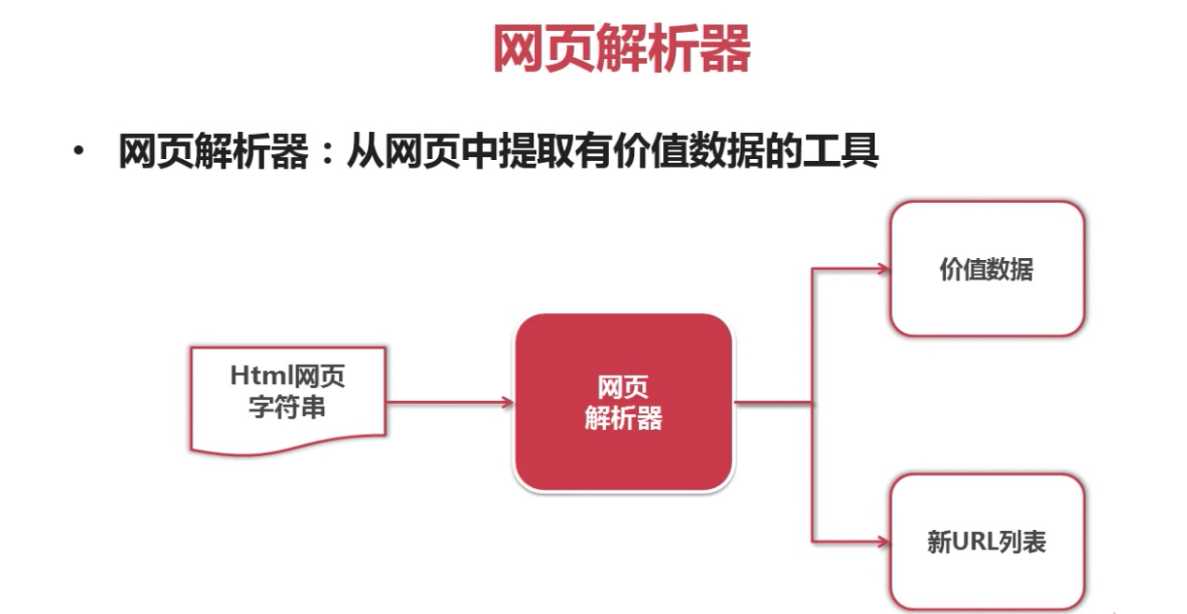
评论
亲,登录后才可以留言!