Adaboost算法详解(haar人脸检测)
2021-07-02 05:06
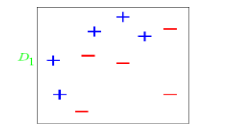
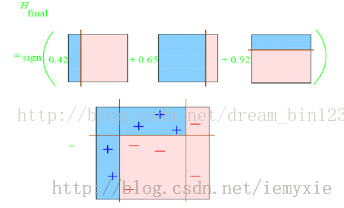
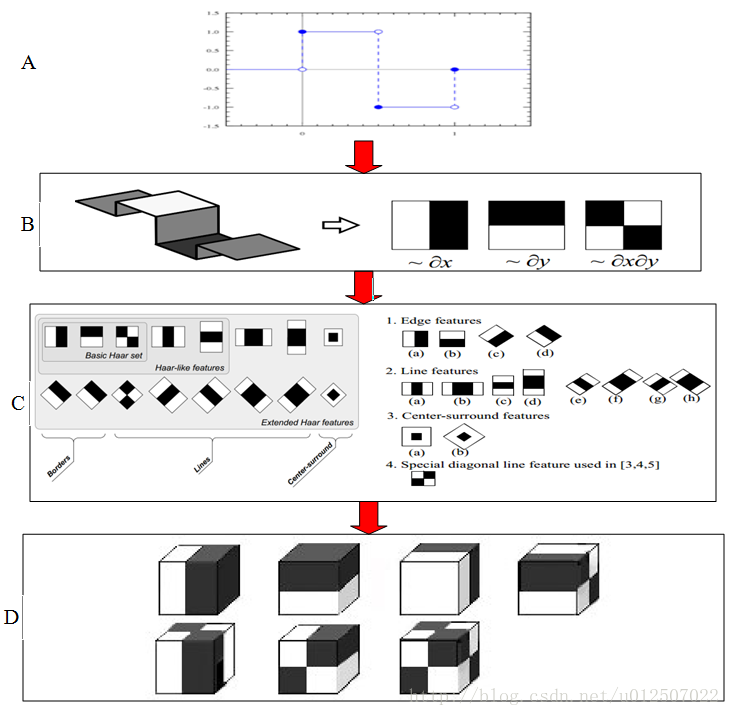
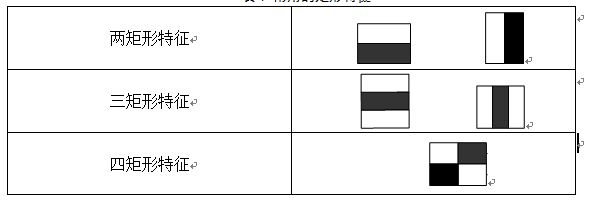
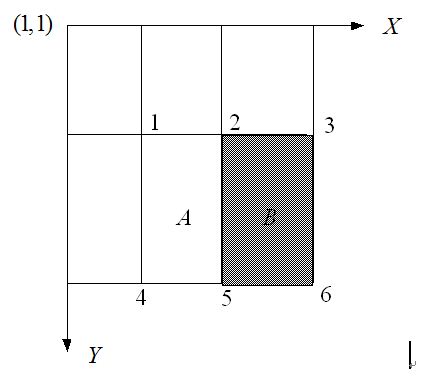
标签:属性 金字塔 范围 其他 upload 固定 发展历程 hit 目标 Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。Adaboost算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每次得到的分类器最后融合起来,作为最后的决策分类器。 算法概述 1、先通过对N个训练样本的学习得到第一个弱分类器; 2、将分错的样本和其他的新数据一起构成一个新的N个的训练样本,通过对这个样本的学习得到第二个弱分类器; 3、将1和2都分错了的样本加上其他的新样本构成另一个新的N个的训练样本,通过对这个样本的学习得到第三个弱分类器 4、最终经过提升的强分类器。即某个数据被分为哪一类要由各分类器权值决定。 与boosting算法比较 1. 使用加权后选取的训练数据代替随机选取的训练样本,这样将训练的焦点集中在比较难分的训练数据样本上; 2. 将弱分类器联合起来,使用加权的投票机制代替平均投票机制。让分类效果好的弱分类器具有较大的权重,而分类效果差的分类器具有较小的权重。 与Boosting算法不同的是,AdaBoost算法不需要预先知道弱学习算法学习正确率的下限即弱分类器的误差,并且最后得到的强分类器的分类精度依赖于所有弱分类器的分类精度,这样可以深入挖掘弱分类器算法的能力。 算法步骤 1. 给定训练样本集S,其中X和Y分别对应于正例样本和负例样本;T为训练的最大循环次数; 2. 初始化样本权重为1/n ,即为训练样本的初始概率分布; 3. 第一次迭代:(1)训练样本的概率分布相当,训练弱分类器;(2)计算弱分类器的错误率;(3)选取合适阈值,使得误差最小;(4)更新样本权重; 经T次循环后,得到T个弱分类器,按更新的权重叠加,最终得到的强分类器。 具体步骤如下: 一.样本 二.初始化训练样本 if(e>=0.5) stop;因为这个弱分类器将一半以上的样本都分错了;所以该特征不可作为弱分类器的特征使用; 实例详解(例子好,必看) 图中“+”和“-”表示两种类别。我们用水平或者垂直的直线作为分类器进行分类。 算法开始前默认均匀分布D,共10个样本,故每个样本权值为0.1. 第一次分类: 第一次划分有3个点划分错误,根据误差表达式 分类器权重: a1=(1/2).*(log((1-e1)./e1))=0.42; 然后根据算法把错分点的权值变大。对于正确分类的7个点,权值不变,仍为0.1,对于错分的3个点,权值为: 第二次分类: 如图所示,有3个"-"分类错误。上轮分类后权值之和为:0.17+0.23333=1.3990 分类误差: 分类器权重 错分的3个点权值为: 第三次分类: 同上步骤可求得: 最终的强分类器即为三个弱分类器的叠加,如下图所示: 每个区域是属于哪个属性,由这个区域所在分类器的权值综合决定。比如左下角的区域,属于蓝色分类区的权重为h1 中的0.42和h2 中的0.65,其和为1.07;属于淡红色分类区域的权重为h3 中的0.92;属于淡红色分类区的权重小于属于蓝色分类区的权值,因此左下角属于蓝色分类区。因此可以得到整合的结果如上图所示,从结果图中看,即使是简单的分类器,组合起来也能获得很好的分类效果。 分类器权值调整的原因 由公式可以看到,权值是关于误差的表达式。每次迭代都会提高错分点的权值,当下一次分类器再次错分这些点之后,会提高整体的错误率,这样就导致分类器权值变小,进而导致这个分类器在最终的混合分类器中的权值变小,也就是说,Adaboost算法让正确率高的分类器占整体的权值更高,让正确率低的分类器权值更低,从而提高最终分类器的正确率。 算法优缺点 优点 1)Adaboost是一种有很高精度的分类器 2)可以使用各种方法构建子分类器,Adaboost算法提供的是框架 3)当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单 4)简单,不用做特征筛选 5)不用担心overfitting(过度拟合) 缺点 1)容易受到噪声干扰,这也是大部分算法的缺点 2)训练时间过长 3)执行效果依赖于弱分类器的选择 y=y=(1-x)./x; (D1=D0*(1-e1)/e1=0.1*(1-0.3)/0.3=0.2333)某点的权值的变化: y=(1/2).*(log((1-x)./x));a1=(1/2).*(log((1-e1)./e1))=0.42;弱分类器权重: 这篇文章讲解haar+adaboost检测人脸将的好:https://www.cnblogs.com/dylantsou/archive/2012/08/11/2633483.html(主要看haar特征个数的计算;如何从haar特征中选取弱分类器需要的特征) 摘要: 基于haar特征的Adaboost人脸检测技术 本文主要是对使用haar+Adabbost进行人脸检测的一些原理进行说明,主要是快找工作了,督促自己复习下~~ 一、AdaBoost算法原理 AdaBoost算法是一种迭代的算法,对于一组训练集,通过改变其中每个样本的分布概率,而得到不同的训练集Si,对于每一个Si进行训练从而得到一个弱分类器Hi,再将这些若分类器根据不同的权值组合起来,就得到了强分类器。 第一次的时候,每个样本都是均匀分布,通过训练得到分类器H0,在该训练集中,分类正确的,就降低其分布概率;分类错误的,就提高其分布概率,这样得到的新的训练集S1就主要是针对不太好分类的样本了。再使用S1进行训练,得到分类器H1,依次迭代下去……,设迭代此外为T,则得到T个分类器。 对于每个分类器的权值,其分类准确性越高,权值越高。 二、Haar特征 Haar-like特征是计算机视觉领域一种常用的特征描述算子(也称为Haar特征,这是因为Haar-like是受到一维haar小波的启示而发明的,所以称为类Haar特征),后来又将Haar-like扩展到三维空间(称为3DHaar-Like)用来描述视频中的动态特征。关于Haar的发展历程如图1所示。 2.1 特征样子 就是一些矩形特征的模板,在viola&Jones的论文中,有下面这五种 在opencv中的方法中,有下面这14种, 2.2 特种的个数 对于一个给定的24X24的窗口,根据不同的位置,以及不同的缩放,可以产生超过160,000个特征。 特征个数的计算方法: 2.3 特征计算方法——积分图 有点类似于动态规划的思想,一次计算,多次使用 对应于两矩形特征2,矩阵A的值可以用i(5)+ii(1)-ii(4)-ii(2)表示,矩阵B的值用ii(6)+ii(2)-ii(3)-ii(5)表示 根据定义,haar特征的值为白色矩形减去黑色矩形的值。 三、选取弱分类器 一个弱分类器,实际上就是在这160,000+的特征中选取一个特征,用这个特征能够区分出人脸or非人脸,且错误率最低。 现在有人脸样本2000张,非人脸样本4000张,这些样本都经过了归一化,大小都是24X24的图像。那么,对于160,000+中的任一特征fi,我们计算该特征在这2000人脸样本、4000非人脸样本上的值,这样就得到6000个特征值。将这些特征值排序,然后选取一个最佳的特征值,在该特征值下,对于特征fi来说,样本的加权错误率最低。选择160,000+个特征中,错误率最低的特征,用来判断人脸,这就是一个弱分类器,同时用此分类器对样本进行分类,并更新样本的权重。 转自:http://blog.csdn.net/watkinsong/article/details/7631241(主要看弱分类器、强分类器的关系排布) 首先,Adaboost是一种基于级联分类模型的分类器。级联分类模型可以用下图表示: 级联分类器介绍:级联分类器就是将多个强分类器连接在一起进行操作。每一个强分类器都由若干个弱分类器加权组成,例如,有些强分类器可能包含10个弱分类器,有些则包含20个弱分类器,一般情况下一个级联用的强分类器包含20个左右的弱分类器,然后在将10个强分类器级联起来,就构成了一个级联强分类器,这个级联强分类器中总共包括200若分类器。因为每一个强分类器对负样本的判别准确度非常高,所以一旦发现检测到的目标位负样本,就不在继续调用下面的强分类器,减少了很多的检测时间。因为一幅图像中待检测的区域很多都是负样本,这样由级联分类器在分类器的初期就抛弃了很多负样本的复杂检测,所以级联分类器的速度是非常快的;只有正样本才会送到下一个强分类器进行再次检验,这样就保证了最后输出的正样本的伪正(false positive)的可能性非常低。
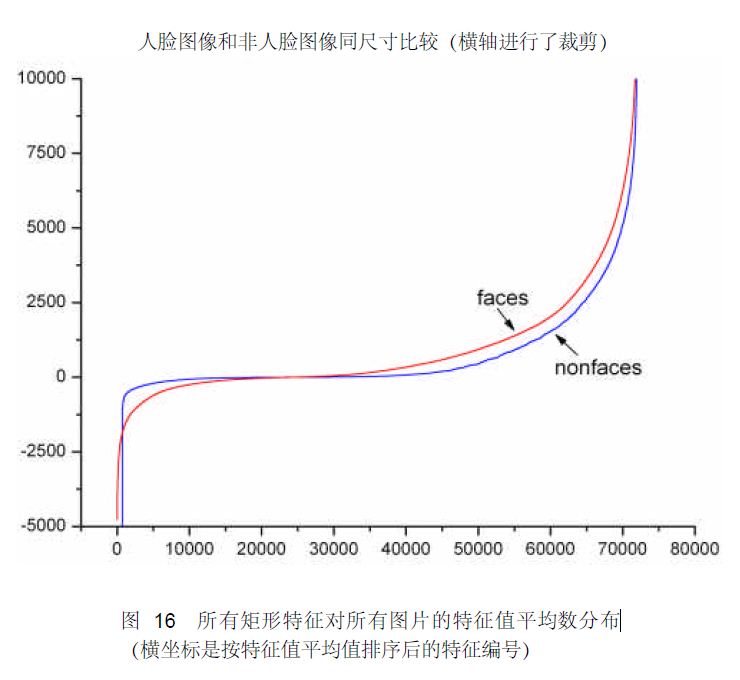
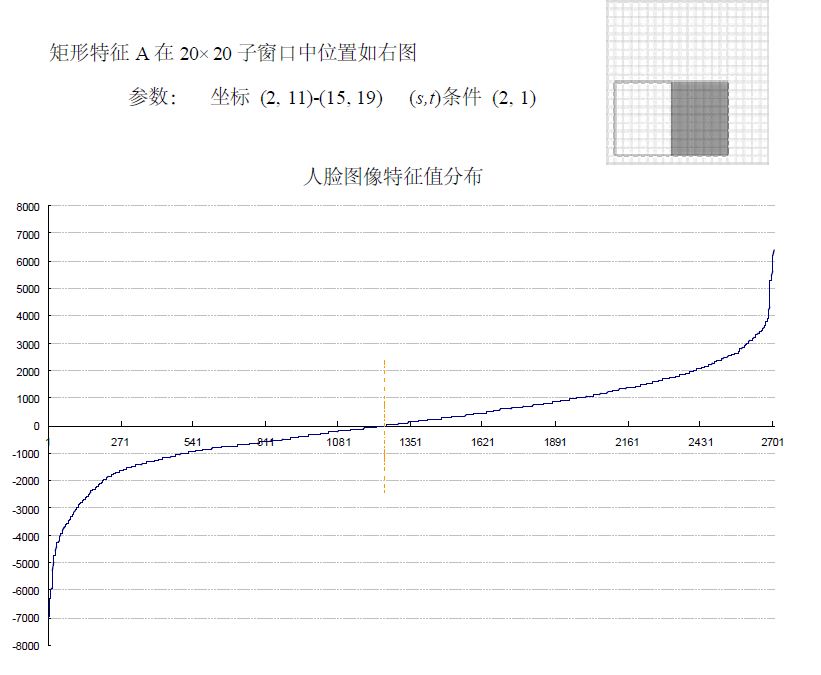
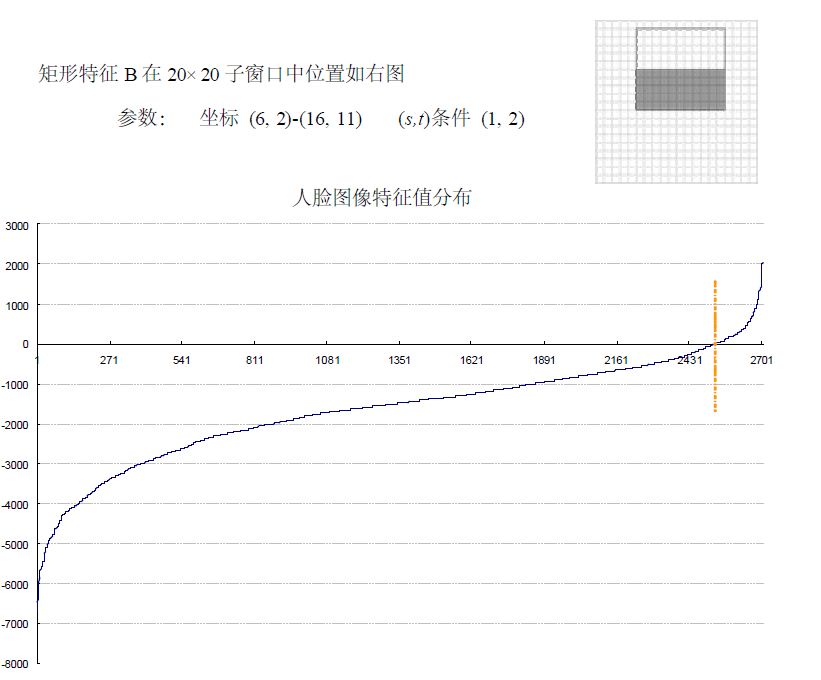
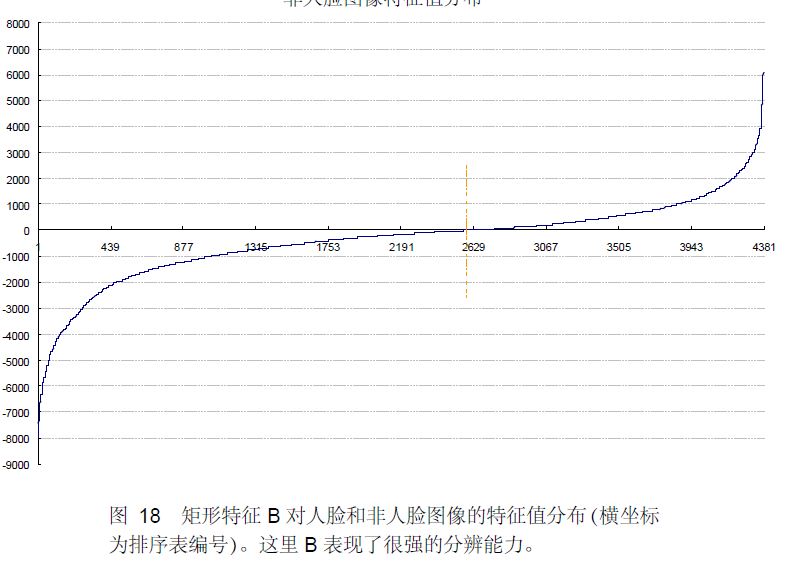
也有一些情况下不适用级联分类器,就简单的使用一个强分类器的情况,这种情况下一般强分类器都包含200个左右的弱分类器可以达到最佳效果。不过级联分类器的效果和单独的一个强分类器差不多,但是速度上却有很大的提升。 转自:http://blog.csdn.net/watkinsong/article/details/7631949(主要看:分析为什么haar可以用于检测人脸;和弱分类器的训练) 在确定了训练子窗口中的矩形特征数量和特征值后,需要对每一个特征f ,训练一个弱分类器h(x,f,p,O) 。 在CSDN里编辑公式太困难了,所以这里和公式有关的都用截图了。 特别说明:在前期准备训练样本的时候,需要将样本归一化和灰度化到20*20的大小,这样每个样本的都是灰度图像并且样本的大小一致,保证了每一个Haar特征(描述的是特征的位置)都在每一个样本中出现。 对于本算法中的矩形特征来说,弱分类器的特征值f(x)就是矩形特征的特征值。由于在训练的时候,选择的训练样本集的尺寸等于检测子窗口的尺寸,检测子窗口的尺寸决定了矩形特征的数量,所以训练样本集中的每个样本的特征相同且数量相同,而且一个特征对一个样本有一个固定的特征值。 对于理想的像素值随机分布的图像来说,同一个矩形特征对不同图像的特征值的平均值应该趋于一个定值k。 对每一个特征,计算其对所有的一类样本(人脸或者非人脸)的特征值的平均值,最后得到所有特征对所有一类样本的平均值分布。 下图显示了20×20 子窗口里面的全部78,460 个矩形特征对全部2,706个人脸样本和4,381 个非人脸样本6的特征值平均数的分布图。由分布看出,特征的绝大部分的特征值平均值都是分布在0 前后的范围内。出乎意料的是,人脸样本与非人脸样本的分布曲线差别并不大,不过注意到特征值大于或者小于某个值后,分布曲线出现了一致性差别,这说明了绝大部分特征对于识别人脸和非人脸的能力是很微小的,但是存在一些特征及相应的阈值,可以有效地区分人脸样本与非人脸样本。 为了更好地说明问题,我们从78,460 个矩形特征中随机抽取了两个特征A和B,这两个特征遍历了2,706 个人脸样本和4,381 个非人脸样本,计算了每张图像对应的特征值,最后将特征值进行了从小到大的排序,并按照这个新的顺序表绘制了分布图如下所示: 可以看出,矩形特征A在人脸样本和非人脸样本中的特征值的分布很相似,所以区分人脸和非人脸的能力很差。 下面看矩形特征B在人脸样本和非人脸样本中特征值的分布: 可以看出,矩形特征B的特征值分布,尤其是0点的位置,在人脸样本和非人脸样本中差别比较大,所以可以更好的实现对人脸分类。 由上述的分析,阈值q 的含义就清晰可见了。而方向指示符p 用以改变不等号的方向。 一个弱学习器(一个特征)的要求仅仅是:它能够以稍低于50%的错误率来区分人脸和非人脸图像,因此上面提到只能在某个概率范围内准确地进行区分就 训练一个弱分类器(特征f)就是在当前权重分布的情况下,确定f 的最优阈值,使得这个弱分类器(特征f)对所有训练样本的分类误差最低。 对于每个特征 f,计算所有训练样本的特征值,并将其排序。通过扫描一遍排好序的特征值,可以为这个特征确定一个最优的阈值,从而训练成一个弱分类器。具体来说,对排好序的表中的每个元素,计算下面四个值: 在对输入图像进行检测的时候,一般输入图像都会比20*20的训练样本大很多。在Adaboost 算法中采用了扩大检测窗口的方法,而不是缩小图片。 为什么扩大检测窗口而不是缩小图片呢,在以前的图像检测中,一般都是将图片连续缩小十一级,然后对每一级的图像进行检测,最后在对检测出的每一级结果进行汇总。然而,有个问题就是,使用级联分类器的AdaBoost的人脸检测算法的速度非常的快,不可能采用图像缩放的方法,因为仅仅是把图像缩放11级的处理,就要消耗一秒钟至少,已经不能达到Adaboost 的实时处理的要求了。 因为Haar特征具有与检测窗口大小无关的特性(想要了解细节还要读一下原作者的文献),所以可以将检测窗口进行级别方法。 在检测的最初,检测窗口和样本大小一致,然后按照一定的尺度参数(即每次移动的像素个数,向左然后向下,一开始一次检测20×20的区域)进行移动,遍历整个图像,标出可能的人脸区域。遍历完以后按照指定的放大的倍数参数放大检测窗口,然后在进行一次图像遍历;这样不停的放大检测窗口对检测图像进行遍历,直到检测窗口超过原图像的一半以后停止遍历。因为 整个算法的过程非常快,即使是遍历了这么多次,根据不同电脑的配置大概处理一幅图像也就是几十毫秒到一百毫秒左右。 在检测窗口遍历完一次图像后,处理重叠的检测到的人脸区域,进行合并等操作。 我的理解是:在检测时:一开始用24×24的子窗口扫描原图,子窗口分别用训练好的Adaboost检测,在第一级的时候就可以抛掉大部分的非人脸样本了;然后将子窗口和特征窗口(haar窗口)放大相同的倍数再扫描原图查找; 用Cascade Adaboost 检测为什么快:先用第一层检测图像标记可能是人脸的区域,用第二层检测第一层标记的区域,再用第三层检测第二层标记的区域,依次执行;被最后一层标记的区域即为人脸区域; 摘自:论文“Robust Real-Time Face Detection”: 这里面的阈值(θ )应该是一个比值,表示的是前百分之多少判为正,(1-θ )×num判为正; 当判断一个新值时也可以比较新特征在特征表中按大小排序的位置,看是不是百分之θ内的; Adaboost算法: Adaboost 和boosting 算法的区别:http://blog.csdn.net/whiteinblue/article/details/14518773 在最后显然 a 表示的就是弱分类器的权值;当某个弱分类器认为是真样本时使 h = 1; 假设 a 被归一化了,那么右边必然等于0.5,左边的 h 等于 0 或 1 ,意思岂不是判对的弱判决器的比重占到一半以上的话,就是正的话,你们强判决器就判为正; 误检率 F;检测率 D ; 减小误检率的同时,也减小的检测率; Cascade Adaboost算法: false positive rate:假正率、检测为0的样本中正样本的概率:(检测为1,实际为0的样本)/(所有检测为1的样本); TPR(True positive rate):召回率:(检测为1实际也为1的样本)/(所有检测为1的样本); detection rate:(检测到的正样本)/(所有的正样本); 反思:haar检测中的特征个数为什么那么多,因为一个坐标的某个特征窗口的,某个尺寸就是一个特征;也就是说特征是由在归一化后的训练集(24×24图片)的某个坐标上、某个特征窗、某个窗尺寸,,三个一起决定的,所以说训练的时候,有所谓的是不是眼睛对齐、人脸在正中间等; 名词解释: 1 false positive rate(假阳率) :false positive rate,FPR.,误诊率或第Ⅰ类错误的。即实际无病或阴性,但被判为有病或阳性的百分比。 Adaboost算法详解(haar人脸检测) 标签:属性 金字塔 范围 其他 upload 固定 发展历程 hit 目标 原文地址:https://www.cnblogs.com/blisme/p/9634162.html



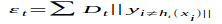 计算可得
计算可得e1=(0.1+0.1+0.1)/1.0=0.3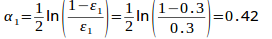
D1=D0*(1-e1)/e1=0.1*(1-0.3)/0.3=0.2333
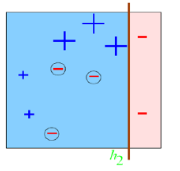
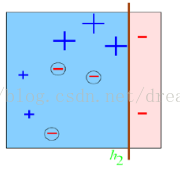
e2=0.1*3/1.3990=0.2144a2=0.6493D2=0.1*(1-0.2144)/0.2144=0.3664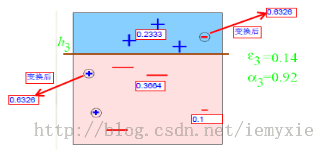
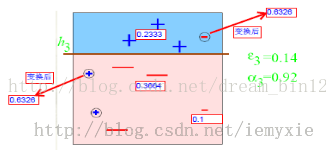
e3=0.1365 ;a3=0.9223;D3=0.6326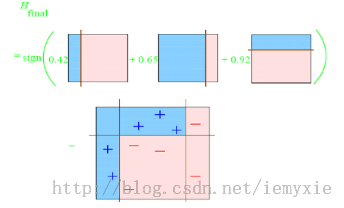
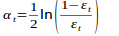



1. 弱分类器


3. 再次介绍弱分类器以及为什么可以使用Haar特征进行分类
这个情况,也应该发生在非人脸样本上,但是由于非人脸样本不一定是像素随机的图像,因此上述判断会有一个较大的偏差。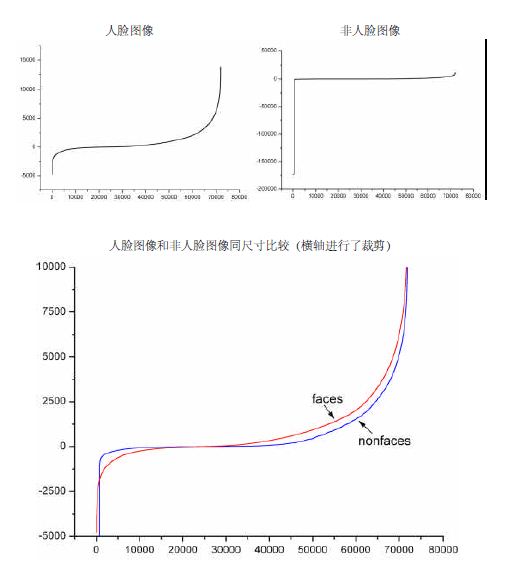

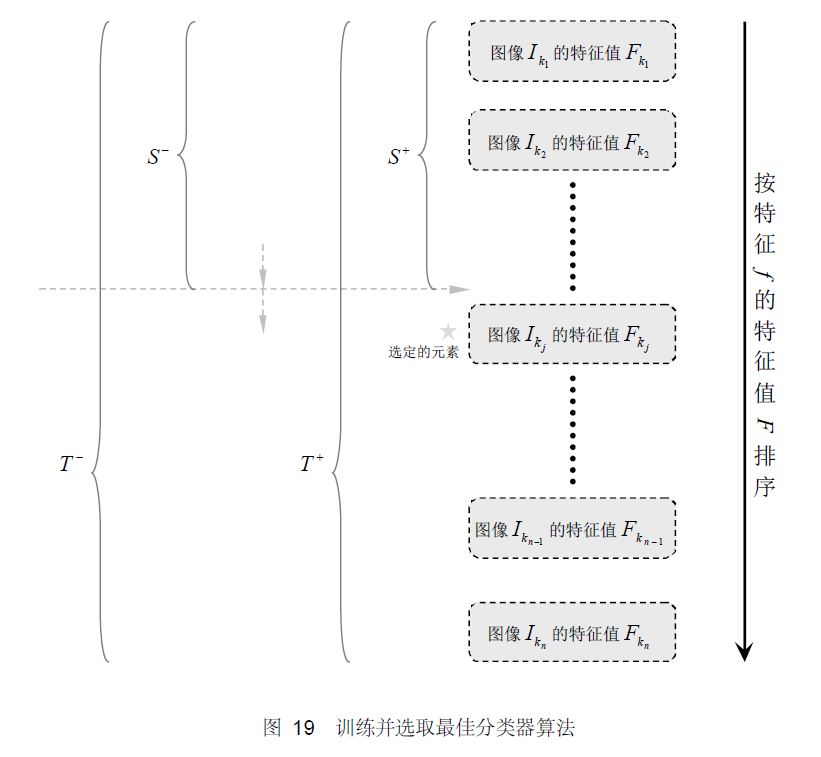
已经完全足够。按照这个要求,可以把所有错误率低于50%的矩形特征都找到(适当地选择阈值,对于固定的训练集,几乎所有的矩形特征都可以满足上述要求)。每轮训练,将选取当轮中的最佳弱分类器(在算法中,迭代T 次即是选择T 个最佳弱分类器),最后将每轮得到的最佳弱分类器按照一定方法提升(Boosting)为强分类器4 弱分类器的训练及选取
选取一个最佳弱分类器就是选择那个对所有训练样本的分类误差在所有弱分类器中最低的那个弱分类器(特征)。

6. 图像检测过程
在检测的最初,检测窗口和样本大小一致,然后按照一定的尺度参数(即每次移动的像素个数,向左然后向下,一开始一次检测20×20的区域)进行移动,遍历整个图像,标出可能的人脸区域。



