FlowNet: Learning Optical Flow with Convolutional Networks
2021-07-02 21:07
标签:http net 特征 引入 end ant 迭代 style 参数设置 学习了一篇用CNN做光流的paper,简称FlowNet。 1. 论文题目 FlowNet: Learning Optical Flow with Convolutional Networks 2.背景 3. 本文提出构建CNNs,以有监督的学习方式解决光流估计任务。提出两种架构,并做了对比实验: 4. 已有光流数据集太小,很多没有标注真实值,本文创建了一个新的光流数据集Flying Chairs,用来充分训练CNN。 5. 网络架构 给定足够的有标签数据,CNN 擅长学习输入-输出关系。所以我们采用end-to-end的学习方法预测光流:给定一个包含图像对真实流的数据集,我们训练一个网络直接从图像中预测x-y流场。但是需要设计合适的架构来实现这个目的。 一个简单的选择是把输入图像堆叠起来,把他们通过一个相当普通网络,让网络自己决定怎样处理图像对从而抽取出运动信息,如图2(top)所示,这个只有卷积组成的架构称为“FlowNetSimple” 原则上,如果这个网络足够大,就能学习预测光流,然而,我们无法保证像SGD那样的局部梯度优化能让网络达到全局最优点,因此,手工设计一个不那么通用、但能用给定数据和优化技巧得到好的性能的架构是有好处的。 一个直接的想法就是:针对两个图像,创建两个独立但相同的处理流,然后在后续进程中把他们结合到一起,如图2(bottom)。在这个架构中,网络需要要先分别产生两个图像的有意义的表达,然后在更高级别把他们结合,这类似于标准的匹配方法中一个先从两个图像的patches抽取特征,然后结合这些特征向量。然而,得到两个图像的特征表达后,网络怎么找二者的对应呢? 在匹配进程,我们在网络中引入了一个“correlation layer”(关联层),在两个特征图中做乘法patch比较,包含这个层的网络结构在图2(bottom)中。给定两个多通道的特征图f1、f2,w、h和c是他们的宽度、高度和通道数,我们的关联层就是让网络比较f1中的每个patch和f2中的每个patch。 现在我们只考虑两个patch的单独比较。第一个图的以x1为中心的patch和第二个图的以x2位中心的patch之间的关联就定义为: 方形patch的尺寸为K=2k+1 (k=0)。公式1等同于神经网络中的一个卷积,但不是用滤波器卷积数据,而是用数据卷积数据,所以,没有可训练的权重。 计算c(x1,x2)涉及到cKK次乘法,比较所有的patch组合涉及到wwhh次计算,所以很难处理前向后向过程。为了计算,我们限制最大位移d用于比较,而且在两个特征图中也引入了步长stride。这样通过限制x2的范围,只在D=2d+1 (d=20)的邻域中计算关联c(x1,x2)。我们用步长s1(1)和s2(2),来全局quantize x1,在以x1为中心的邻域内quantize x2。 理论上,关联的结果是4D的:对两个2D位置的每个组合,我们得到一个关联值,即两个分别包含截取patches值的向量的内积。实际上,我们把相对位置用通道表示,这就意味着我们得到了w*h*D*D大小的输出。在反向过程中,我们求关于每个对应底层blob的导数。 6. Refinement Pooling会导致分辨率减少,为了提供密集的像素预测,我们需要一种方法来refine pool后的coarse表达。我们refine的方法如图3所示,主要的是upconvolutional 上卷积层,由unpooling(与pooling相反,扩展特征图)和卷积组成。为了做refinement,我们在特征图上用上卷积,然后把它和网络的收缩部分’contractive’ 得到的对应特征图、以及一个上采样的coarses流预测连接起来。这样就能既保留coarser特征图的高层信息,又能保留低层特征图的好的局部信息。每个步骤两次增加分辨率,我们重复这个过程4次,得到预测的流,此时的特征图还是原图的四分之一。 我们发现,与对全图像分辨率做计算量更少的双线性上采样相比,从这个分辨率上做更多的refinement并不能显著提升结果,这个双线性上采样的结果就是网络的最终流预测。 我们替换双线性上采样,采用没有匹配项的变分方法:我们在4次下采样分辨率后开始,迭代20次做coarse-to-fine,把流场变为全分辨率。最后,在全图像分辨率上又做了5次迭代。然后把平滑系数换为 7. 训练的参数设置 FlowNet: Learning Optical Flow with Convolutional Networks 标签:http net 特征 引入 end ant 迭代 style 参数设置 原文地址:http://www.cnblogs.com/nenya33/p/7122701.html
出处:http://www.cnblogs.com/nenya33/p/7122701.html
转载:欢迎转载,但未经作者同意,必须保留此段声明;必须在文章中给出原文连接;否则必究法律责任

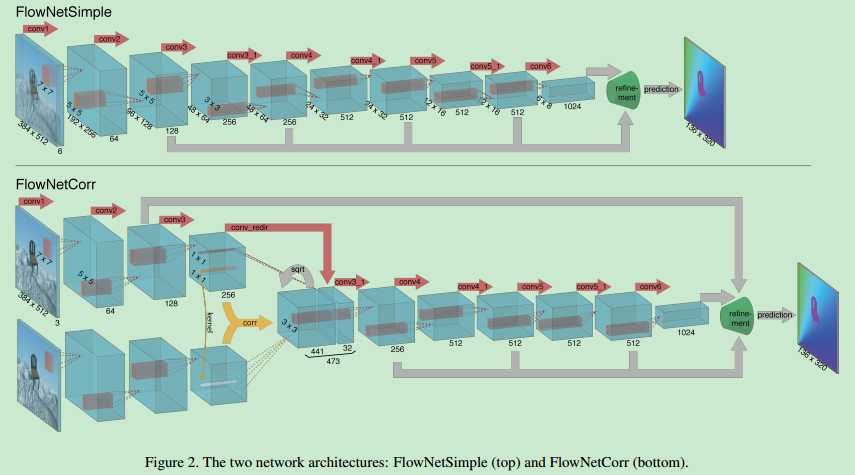
![]()
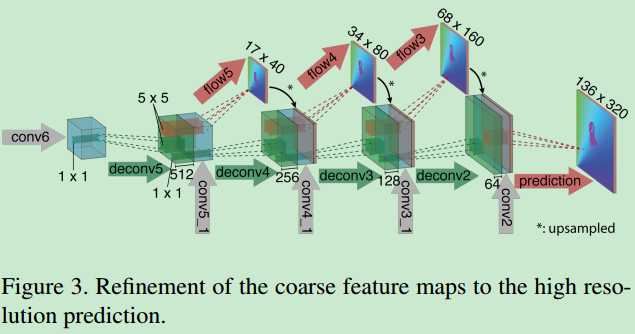
![]() ,用文献【26】的方法计算图像边界和对应的检测边界,b(x,y)是各自尺度和像素之间的重采样的thin边界的strength。这种放大方法比简单的双线性上采样计算量大,但是增加了变分方法的优点,得到平滑和亚像素准确的流场。在下文中,用变分法refine的结果加后缀+v。变分结果见图4
,用文献【26】的方法计算图像边界和对应的检测边界,b(x,y)是各自尺度和像素之间的重采样的thin边界的strength。这种放大方法比简单的双线性上采样计算量大,但是增加了变分方法的优点,得到平滑和亚像素准确的流场。在下文中,用变分法refine的结果加后缀+v。变分结果见图4
![]()
达到 λ = 1e-4 ,然后再按照刚刚说的减少。
文章标题:FlowNet: Learning Optical Flow with Convolutional Networks
文章链接:http://soscw.com/essay/100968.html