【nodejs爬虫】使用async控制并发写一个小说爬虫
2021-07-03 18:03
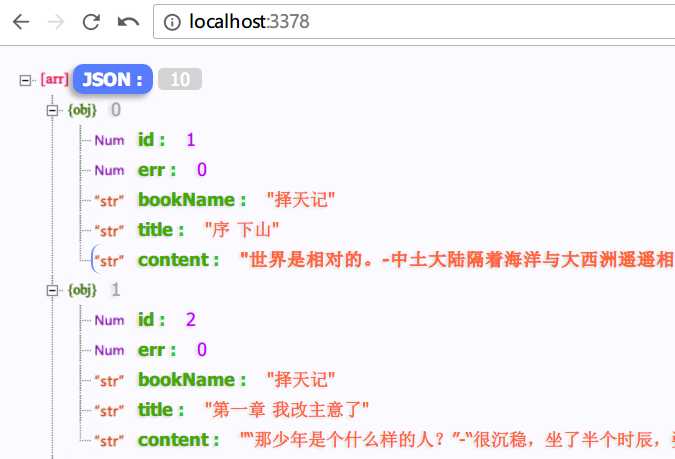
标签:.text attr lan length 内容 split sync 并发 style 最近在做一个书城项目,数据用爬虫爬取,百度了一下找到这个网站,以择天记这本小说为例。 爬虫用到了几个模块,cheerio,superagent,async。 superagent是一个http请求模块,详情可参考链接。 cheerio是一个有着jQuery类似语法的文档解析模块,你可以简单理解为nodejs中的jQuery。 async是一个异步流程控制模块,在这里我们主要用到async的mapLimit(coll, limit, iteratee, callback) 第一个参数coll是一个数组,保存了小说的章节url,第二个参数limit是控制并发数,第三个参数iteratee接受一个回调函数,该回调函数的第一个参数就是单独某一章的url,第二个参数也是一个回调函数,这个回调函数执行后会把结果(在这里就是每一章的内容)保存到第四个参数callback的results中,results是一个数组,保存了所有章节的内容。 我们在fetchUrl获取章节数据。 首先我们要根据小说的主页url获取所有章节的url保存到数组urls中: fetchUrl函数 完整代码: 结果如下: 【nodejs爬虫】使用async控制并发写一个小说爬虫 标签:.text attr lan length 内容 split sync 并发 style 原文地址:http://www.cnblogs.com/tgxh/p/7124202.htmlasync.mapLimit(urls, 10, function (url, callback) {
fetchUrl(url, callback, id)
}, function (err, results) {
//TODO
})
superagent.get(url)
.charset(‘gbk‘) //该网站编码为gbk,用到了superagent-charset
.end(function (err, res) {
var $ = cheerio.load(res.text); //res.text为获取的网页内容,通过cheerio的load方法处理后,之后就是jQuery的语法了
let urls = []
total = $(‘#list dd‘).length
console.log(`共${$(‘#list dd‘).length}章`)
$(‘#list dd‘).each(function (i, v) {
if (i chapters) {
urls.push(‘http://www.zwdu.com‘ + $(v).find(‘a‘).attr(‘href‘))
}
})
function fetchUrl(url, callback, id) {
superagent.get(url)
.charset(‘gbk‘)
.end(function (err, res) {
let $ = cheerio.load(res.text)
//obj为构建的包含章节信息的对象
callback(null, obj) //将obj传递给第四个参数中的results
})
}
/**
* Created by tgxh on 2017/7/4.
*/
const cheerio = require(‘cheerio‘)
const express = require(‘express‘)
const app = express()
const superagent = require(‘superagent‘)
require(‘superagent-charset‘)(superagent)
const async = require(‘async‘);
let total = 0 //总章节数
let id = 0 //计数器
const chapters = 10 //爬取多少章
const url = ‘http://www.zwdu.com/book/8634/‘
//去除前后空格和 转义字符
function trim(str) {
return str.replace(/(^\s*)|(\s*$)/g, ‘‘).replace(/ /g, ‘‘)
}
//将Unicode转汉字
function reconvert(str) {
str = str.replace(/()(\w{1,4});/gi, function ($0) {
return String.fromCharCode(parseInt(escape($0).replace(/(%26%23x)(\w{1,4})(%3B)/g, "$2"), 16));
});
return str
}
function fetchUrl(url, callback, id) {
superagent.get(url)
.charset(‘gbk‘)
.end(function (err, res) {
let $ = cheerio.load(res.text)
const arr = []
const content = reconvert($("#content").html())
//分析结构后分割html
const contentArr = content.split(‘
‘)
contentArr.forEach(elem => {
const data = trim(elem.toString())
arr.push(data)
})
const obj = {
id: id,
err: 0,
bookName: $(‘.footer_cont a‘).text(),
title: $(‘.bookname h1‘).text(),
content: arr.join(‘-‘) //由于需要保存至mysql中,不支持直接保存数组,所以将数组拼接成字符串,取出时再分割字符串即可
}
callback(null, obj)
})
}
app.get(‘/‘, function (req, response, next) {
superagent.get(url)
.charset(‘gbk‘)
.end(function (err, res) {
var $ = cheerio.load(res.text);
let urls = []
total = $(‘#list dd‘).length
console.log(`共${$(‘#list dd‘).length}章`)
$(‘#list dd‘).each(function (i, v) {
if (i chapters) {
urls.push(‘http://www.zwdu.com‘ + $(v).find(‘a‘).attr(‘href‘))
}
})
async.mapLimit(urls, 10, function (url, callback) {
id++
fetchUrl(url, callback, id) //需要对章节编号,所以通过变量id来计数
}, function (err, results) {
response.send(results)
})
})
})
app.listen(3378, function () {
console.log(‘server listening on 3378‘)
})
文章标题:【nodejs爬虫】使用async控制并发写一个小说爬虫
文章链接:http://soscw.com/essay/101368.html