Python爬虫教程-28-Selenium 操纵 Chrome
2021-07-04 20:11
标签:elements 代码 ons hot scree pycharm 取消 页面 搜索 我觉得本篇是很有意思的,闲着没事来看看! PhantomJS 幽灵浏览器,无界面浏览器,不渲染页面。Selenium + PhantomJS 在之前是很完美的搭配。后来在 2017 年 Google 宣布 Chrome 也宣布支持不渲染。所以 PhantomJS 使用的人就越来越少了,挺可惜,本篇介绍 Selenium + Chrome 可以通过 ActionsChains类来做到 1.控制台:打印出来了我们想要的能看到的文本 运行代码,会自动打开浏览器,自动输入大熊猫,自动截屏并保存,然后选中输入框内容,然后拷贝 Python爬虫教程-28-Selenium 操纵 Chrome 标签:elements 代码 ons hot scree pycharm 取消 页面 搜索 原文地址:https://www.cnblogs.com/xpwi/p/9601015.htmlPython爬虫教程-28-Selenium 操纵 Chrome
安装Chrome浏览器和 Chromedriver
安装 Chromedriver-binary 包
安装好就可以尽情使用了Selenium 操作
案例 29chromedriver
https://xpwi.github.io/py/py%E7%88%AC%E8%99%AB/py29chromedriver.py# Selenium + Chrome 案例1
from selenium import webdriver
# 路径是自己解压安装 Chromedriver 的路径
driver = webdriver.Chrome()
url = "http://www.baidu.com"
driver.get(url)
# 根据id查找,后面加.text 表示拿看到的文本数据
text = driver.find_element_by_id(‘wrapper‘).text
print(text)运行结果
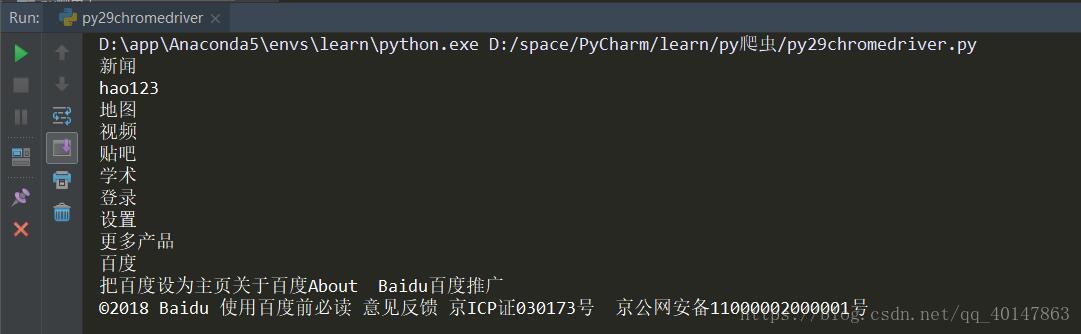
2.我们可以看到:执行程序自动打开了一个 Chrome 浏览器的窗口,并提示 Chrome 正受到自动检测软件的控制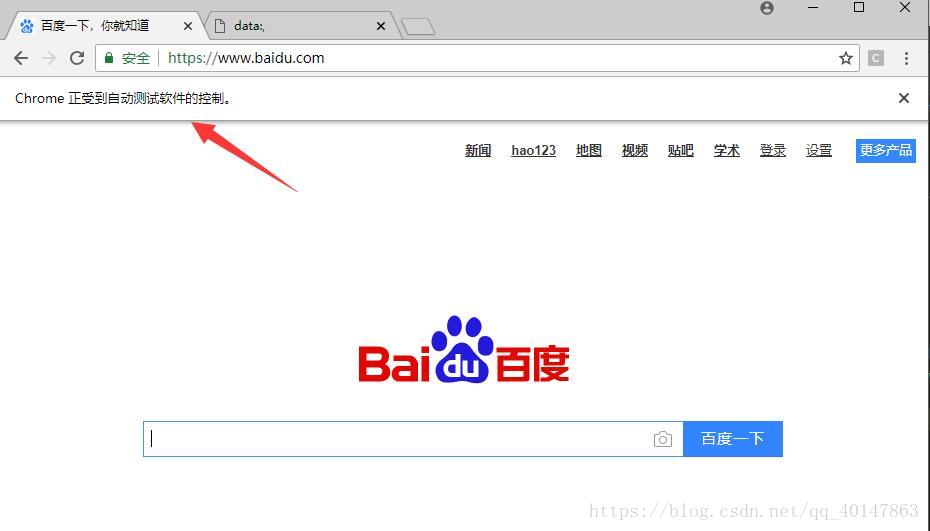
此时,既然已经控制了浏览器,我们就可以进行更多操作了重要案例 29chromedriver2.py
https://xpwi.github.io/py/py%E7%88%AC%E8%99%AB/py29chromedriver2.py# Selenium + Chrome 案例2
# 打开的浏览器可能会弹窗,点击【取消】或者【不管它】都行
from selenium import webdriver
import time
from selenium.webdriver.common.keys import Keys
# 默认不需要路径,如果没有环境变量就需要加上
driver = webdriver.Chrome()
url = "http://www.baidu.com"
driver.get(url)
# 根据id查找,后面加.text 表示拿看到的文本数据
text = driver.find_element_by_id(‘wrapper‘).text
print(driver.title)
# 对页面截屏,保存为 baidu.png
driver.save_screenshot(‘py29baidu.png‘)
# 控制 Chrome 在输入框输入大熊猫
driver.find_element_by_id(‘kw‘).send_keys(u"大熊猫")
# 单击搜索按钮,id = ‘su‘
driver.find_element_by_id(‘su‘).click()
# 缓冲5秒,让页面加载图片等
time.sleep(5)
# 截屏,保存
driver.save_screenshot("py29daxiongmao.png")
# 获取当前页面的 cookie 常用在需要登录的页面
print(driver.get_cookie(‘cookie‘))
# 模拟 按下两个按键 Ctrl + a
driver.find_element_by_id(‘kw‘).send_keys(Keys.CONTROL, ‘a‘)
# 模拟 按下两个按键 Ctrl + c
driver.find_element_by_id(‘kw‘).send_keys(Keys.CONTROL, ‘c‘)运行结果
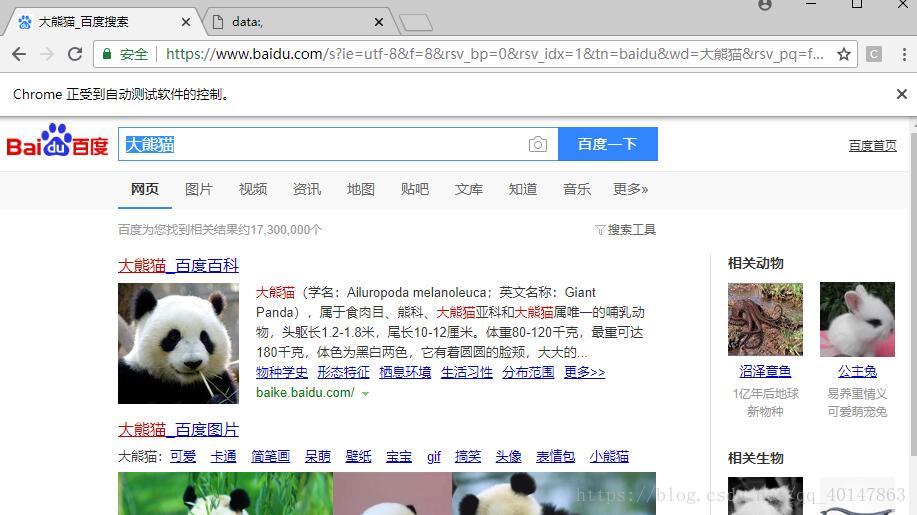
是不是很神奇,保存的截屏和代码同级目录
拜拜
- 本笔记不允许任何个人和组织转载
上一篇:Python 生产者消费者模式
下一篇:Hash(哈希)算法科普
文章标题:Python爬虫教程-28-Selenium 操纵 Chrome
文章链接:http://soscw.com/essay/101862.html