Java并发编程原理与实战四十五:问题定位总结
2021-07-09 08:04
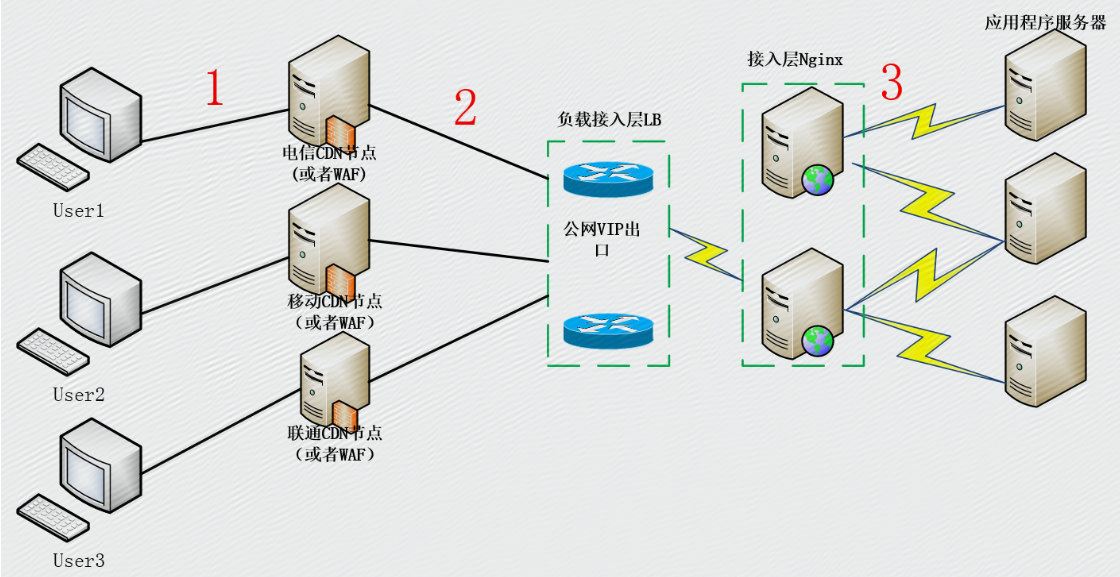
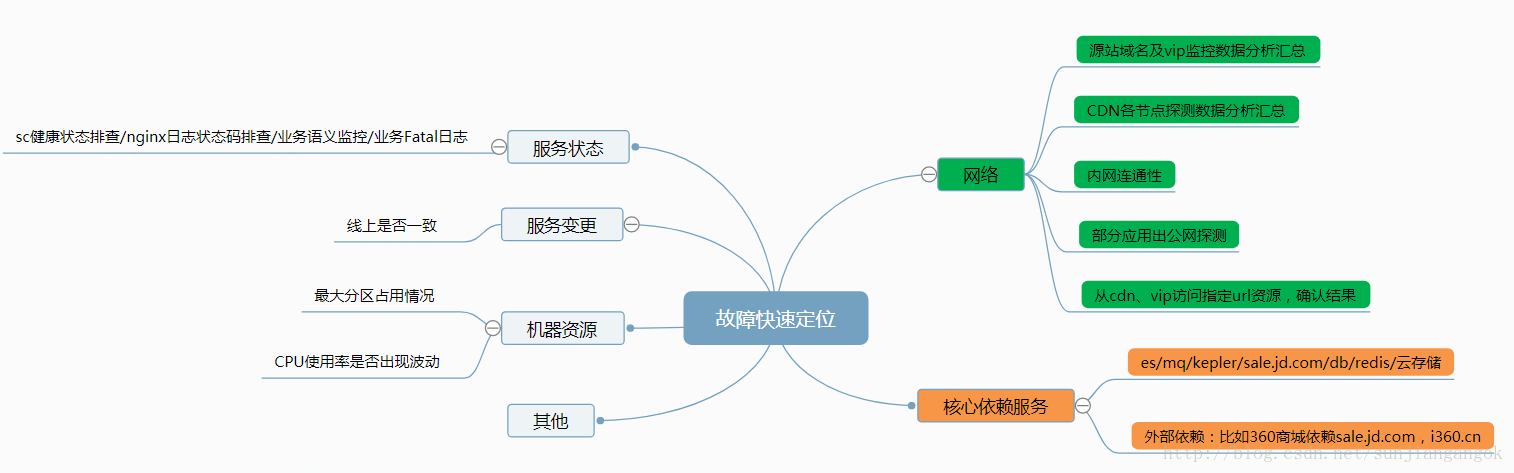
标签:磁盘io 暂停 对象 red iostat sso eth try lap 背景 1. 常见问题 sar:查看CPU 网络IO IO,开启参数可以查看历史数据 b) top c) vmstat d) tcpdump 2.2 java工具 b) jmap c) jstack or kill -3 inboud/outbound thread overview 配置项 thread dump 查找线程执行的代码 3.2 io高 b) log concurrent fail b) 连续Full GC 5.从运维角度谈谈故障定位 面试时,经常会被问到:在线业务出现故障,该如何定位? 一般刚毕业不久的会回答:我们有监控;看日志等之类的答案。 工作几年的人会回答:从网络,机器,资源等方面排查有没有问题,如果没有问题,再看看日志,找开发核对。 也有人回答这个是开发的问题,我们运维还没有精确到业务层面。 故障定位,这个话题可能很大,不同角色认识是不一样的。对于开发,故障定位往往会根据问题现象,从代码角度去分析,尝试从代码或架构方面进行解决。对于运维而言,故障定位,一般理解为:在线业务的核心功能受到影响,应该如何快速定位到原因。 本文要讨论的范围,也仅限于运维角度进行在线问题故障定位。 运维人员进行故障定位时,遇到主要问题: 1)业务掌握深入程度有限。不像某个应用的开发那样,能很清楚一个小问题的处理逻辑。 2)要对在线业务的稳定性负责。 3)造成故障的原因很多。除了代码bug可能导致问题外,IDC,机器,流量波动等外在条件都会有影响。 4)不同运维人员对于业务理解或运维能力不同。不同的业务运维人员由于经验等不同,遇到故障时的心态、决策等区别很大。 “核心功能告警,执行预案”是运维处理在线故障的思路。但是,当预案执行后,故障仍然存在,该如何做呢? 这时候,就要快速、准确定位出故障原因,至少要知道造成这次故障的一个范围是什么,以便采取相应措施。 网络方面 网络无疑是造成服务故障的第一杀手。 用户->CDN->源站IDC->业务接入层->后端服务 用户->源站IDC->业务接入层->后端服务 服务健康 资源使用 核心依赖 上线变更 容量方面 文章参考资料来源: https://blog.csdn.net/sunjiangangok/article/details/79266238 http://blog.51cto.com/yingtju/1908197 Java并发编程原理与实战四十五:问题定位总结 标签:磁盘io 暂停 对象 red iostat sso eth try lap 原文地址:https://www.cnblogs.com/pony1223/p/9567518.html
“线下没问题的”、 “代码不可能有问题 是系统原因”、“能在线上远程debug么”
线上问题不同于开发期间的bug,与运行时环境、压力、并发情况、具体的业务相关。对于线上的问题利用线上环境可用的工具,收集必要信息 对定位问题十分重要。
对于导致问题的bug、资源瓶颈很难直观取得数据,需要根据资源使用数据、日志等信息推测问题根源。并且疑难问题的定位通常需要使用不同的方法追根溯源。
这篇wiki我对自己使用过的工具做了整理,并分享一些案例。
1.1 可用性
这里举几种常见导致服务可用性的情况:
a) 502 Bad Gateway
对应用系统特别是基于http的应用最严重的莫过于"502 Bad Gateway",这表示后端服务已经完全不可用,可能原因
资源不足1:垃圾回收导致,在CMS在应用内存泄漏或内存不足情况下会导致严重的应用暂停。
资源不足2:服务器线程数不足,常见web server如tomcat jetty都是有最大工作线程配置的
资源不足3:数据库资源不足,数据库通常使用连接池配置,maxConnection配置低加上过多慢查询会block住web server的工作线程
资源不足4:IO资源瓶颈,线上环境IO是共享的,尤其对于混布环境(CRM还好 没有这种情况,但是有很多agent),我们常用的log4j日志工具对于每个记录的日志文件也是一种独占资源,线程先要获得锁才能向日志记录数据。
... ...
各种OOM
b) Socket异常
常见Connection reset by peer,Broken Pipe,EOFException
网络问题:在跨运营商、机房访问情况下可能遇到
程序bug:socket异常关闭
1.2 平均响应时间
系统发生问题时最直观的表象,这个参数在情况恶化传染其他服务 导致整个系统不可用前,可以提前预警,可能原因:
资源竞争1:CPU
资源竞争2:IO
资源竞争3:network IO
资源竞争4:数据库
资源竞争5:solr、medis
下游接口:异常导致响应延时
1.3 机器报警
与应用服务不可用相比,这类错误不会直接导致服务不可用,而且如果存在混不,机器部署多个服务可能相互干扰:
CPU
磁盘
fd
IO(网络 磁盘)
1.4 小结
写了半天,很多情况是重复提到,通常线上问题的原因不外乎系统资源、应用程序,掌握监控查看这些资源、数据的工具就更容易定位线上的问题。
2常用工具
2.1 Linux工具
a) sysstat:
iostat:查看读写压力 [sankuai@cos-mop01 logs]$ iostat
Linux 2.6.32-20131120.mt (cos-mop01.lf.sankuai.com) 2015年10月21日 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
1.88 0.00 0.87 0.12 0.05 97.07
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
vda 1.88 57.90 12.11 2451731906 512911328
vdb 0.01 0.40 1.41 17023940 59522616
vdc 1.14 28.88 36.63 1223046988 1551394969 /etc/sysconfig/sysstat
HISTORY=7
/etc/cron.d/sysstat
*/10 * * * * root /usr/lib/sa/sa1 1 1
sar -u/-r/-B/-b/-q/-P/-n -f /var/log/sa/sa09
关注load、cpu、mem、swap
可按照线程查看资源信息(版本大于3.2.7)top - 19:33:00 up 490 days, 4:33, 2 users, load average: 0.13, 0.39, 0.42
Tasks: 157 total, 1 running, 156 sleeping, 0 stopped, 0 zombie
Cpu(s): 4.9%us, 2.7%sy, 0.0%ni, 92.2%id, 0.0%wa, 0.0%hi, 0.0%si, 0.3%st
Mem: 5991140k total, 5788884k used, 202256k free, 4040k buffers
Swap: 2096440k total, 447332k used, 1649108k free, 232884k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ SWAP CODE DATA COMMAND
18720 sankuai 20 0 8955m 4.3g 6744 S 22.6 74.5 174:30.73 0 4 8.6g java
27794 sankuai 20 0 5715m 489m 2116 S 11.6 8.4 3922:43 121m 4 3.9g java
13233 root 20 0 420m 205m 2528 S 0.0 3.5 1885:15 91m 4 304m puppetd
21526 sankuai 20 0 2513m 69m 4484 S 0.0 1.2 45:56.28 37m 4 2.4g java[sankuai@cos-mop01 logs]$ vmstat
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 447332 200456 4160 234512 0 0 11 6 0 0 2 1 97 0 0
定位网络问题神器,可以看到TCPIP报文的细节,需要同时熟悉TCPIP协议,可以和wireshark结合使用。
常见场景分析网络延迟、网络丢包,复杂环境的网络问题分析。#!/bin/bash
tcpdump -i eth0 -s 0 -l -w - dst port 3306 | strings | perl -e ‘
while() { chomp; next if /^[^ ]+[ ]*$/;
if(/^(SELECT|UPDATE|DELETE|INSERT|SET|COMMIT|ROLLBACK|CREATE|DROP|ALTER|CALL)/i)
{
if (defined $q) { print "$q\n"; }
$q=$_;
} else {
$_ =~ s/^[ \t]+//; $q.=" $_";
}
}‘
a) jstat[sankuai@cos-mop01 logs]$ jstat -gc 18704
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
3584.0 3584.0 0.0 0.0 24064.0 13779.7 62976.0 0.0 4480.0 677.9 384.0 66.6 0 0.000 0 0.000 0.000jmap -dump:format=b,file=heap.bin $pid
查看死锁、线程等待。
线程状态:
Running
TIMED_WAITING(on object monitor)
TIMED_WAITING(sleeping)
TIMED_WAITING(parking)
WAINTING(on object monitor)
d) jhat jconsole
jhat很难用 jconsole通过jmx取信息对性能有影响
e) gc日志
-XX:+UseParallelOld
-XX:+ConcurrentMultiSweep
2.3 第三方工具
a) mat
对象详细
./MemoryAnalyzer -keep_unreachable_objects heap_file
3. 案例分析
3.1 cpu高
现象:CPU报警
定位问题:
查看CPU占用高的线程sankuai@sin2:~$ ps H -eo user,pid,ppid,tid,time,%cpu|sort -rnk6 |head -10
sankuai 13808 13807 13808 00:00:00 8.4
sankuai 29153 1 29211 00:21:13 0.9
sankuai 29153 1 29213 00:20:01 0.8
sankuai 29153 1 29205 00:17:35 0.7
sankuai 29153 1 29210 00:11:50 0.5
sankuai 29153 1 1323 00:08:37 0.5
sankuai 29153 1 29207 00:10:02 0.4
sankuai 29153 1 29206 00:07:10 0.3
sankuai 29153 1 29208 00:06:44 0.2 jstack $pid > a.txt
printf %x $tid
$xTID"main-SendThread(cos-zk13.lf.sankuai.com:9331)" #25 daemon prio=5 os_prio=0 tid=0x00007f78fc350000 nid=$TIDx runnable [0x00007f79c4d09000]
java.lang.Thread.State: RUNNABLE
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1035)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
现象:磁盘IO报警
环境:需要安装sysstat工具
定位问题:
a) 查看CPU占用高的线程pidstat -d -t -p $pid
b) 其他同4.1
3.3 资源
a) 数据库"DB-Processor-13" daemon prio=5 tid=0x003edf98 nid=0xca waiting for monitor entry [0x000000000825f000]
java.lang.Thread.State: BLOCKED (on object monitor)
at ConnectionPool.getConnection(ConnectionPool.java:102)
- waiting to lock > (a beans.ConnectionPool)
at Service.getCount(ServiceCnt.java:111)
at Service.insert(ServiceCnt.java:43)
"DB-Processor-14" daemon prio=5 tid=0x003edf98 nid=0xca waiting for monitor entry [0x000000000825f020]
java.lang.Thread.State: BLOCKED (on object monitor)
at ConnectionPool.getConnection(ConnectionPool.java:102)
- waiting to lock > (a beans.ConnectionPool)
at Service.getCount(ServiceCnt.java:111)
at Service.insertCount(ServiceCnt.java:43)"RMI TCP Connection(267865)-172.16.5.25" daemon prio=10
tid=0x00007fd508371000 nid=0x55ae waiting for monitor entry
[0x00007fd4f8684000] java.lang.Thread.State: BLOCKED (on object monitor)
at org.apache.log4j.Category.callAppenders(Category.java:201)
- waiting to lock > (a org.apache.log4j.Logger)
at org.apache.log4j.Category.forcedLog(Category.java:388)
at org.apache.log4j.Category.log(Category.java:853)
at org.apache.commons.logging.impl.Log4JLogger.warn(Log4JLogger.java:234)
at com.xxx.core.common.lang.cache.remote.MemcachedClient.get(MemcachedClient.java:110)
c) web server
有两个非常重要的系统参数:
maxThread: 工作线程数
backlog:TCP连接缓存数,Jetty(ServerConnector.acceptQueueSize) Tomcat(Connector.acceptCount),高并发下设置过小会有502
3.4 gc
a) CMS fail
promotion failed 172966 2015-09-18T03:47:33.108+0800: 627188.183: [GC 627188.183: [ParNew (promotion failed)
172967 Desired survivor size 17432576 bytes, new threshold 1 (max 6)
172968 - age 1: 34865032 bytes, 34865032 total
172969 : 306688K->306688K(306688K), 161.1284530 secs]627349.311: [CMS CMS: abort preclean due to time 2015-09-18T03:50:14.743+0800: 627349.818:
[CMS-concurrent-abortable-preclean: 1.597/162.729 secs] [Times: user=174.58 sys=84.57, real=162.71 secs]
172970 (concurrent mode failure): 1550703K->592286K(1756416K), 2.9879760 secs]
1755158K->592286K(2063104K), [CMS Perm : 67701K->67695K(112900K)], 164.1167250 secs] [Times: user=175.61 sys=84.57, real=164.09 secs] [CMS2015-09-18T07:07:27.132+0800: 639182.207: [CMS-concurrent-sweep: 1.704/13.116 secs] [Times: user=17.16 sys=5.20,real=13.12 secs]
443222 (concurrent mode failure): 1546078K->682301K(1756416K), 4.0745320 secs] 1630977K->682301K(2063104K), [CMS Perm :67700K->67693K(112900K)], 15.4860730 secs] [Times: user=19.40 sys=5.20, real=15.48 secs]
应用存在内存泄漏,垃圾收集会占用系统大量cpu时间,极端情况下可能发生90%以上时间在做GC的情况。
在系统使用http访问check alive或者使用了Zookeeper这种通过心跳保证存活性的应用中,会可用性异常或者被zk的master剔除。
4. 注意
保留现场:threaddump top heapdump
注意日志记录:文件 数据库