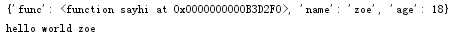Json & pickle 数据序列化
2021-07-09 22:05
标签:asc log ges 方式 列表 bsp erro 写法 closed 前提: 文本文件中只能写入字符串或ascii码格式的内容。 变通方式将 f.write(info) 改为 f.write(str(info))。 但是这种写法比较低端。 同时,将文件通过open()读取到环境中,读取进来的还是字符串格式的。上面的操作是序列化,读取文件后的操作时反序列化。 返回: 但是上面的序列化和反序列化的方式不是常规的用法。只是在我们不了解序列化模块json,pickle的时候的用法。接下来我们介绍用于序列化的两个模块。 用于序列化的两个模块 Json模块提供了四个功能:dumps、dump、loads、load pickle模块提供了四个功能:dumps、dump、loads、load json 实例1: 实例2: 所以,json只能支持简单的数据类型,如字典,列表,字符串等。—— json主要用于不同的语言之间进行数据交互。比方说java和python之间的字典的交互,类,函数等复杂的json是无法进行处理,在不同语言之间进行交互。 xml主要在不同的语言和程序之间进行数据交互,是一种标记式的语言,正在逐渐被json给取代。因为json更简洁,更清晰。json是目前主流的在不同语言之间进行数据交互的模块。 json只能处理简单的,而pickle是用来处理复杂的数据类型。 json和pickle的操作和json一模一样。 pickle 实例1: 反序列化: 小知识: json和pickle在文件写入过程中dumps两次,会写入两次; json和pickle在文件中loads,在3.x中只能loads一次。 在2.x中第一次dump的,可以第一次loads。但是这个不好。 所以对于同一个文件的写入和读取记住只dump一次,load一次。如果想要每个都要dump一次,则dump成不同的文件。 Json & pickle 数据序列化 标签:asc log ges 方式 列表 bsp erro 写法 closed 原文地址:http://www.cnblogs.com/zoe233/p/7091119.htmlinfo={‘name‘:‘zoe‘,‘age‘:18}
f=open(‘test.txt‘,‘w‘)
f.write(info) #在文本文件中写入字典格式的内容,执行会报错。
f.closed()

f=open(‘test.txt‘,‘r‘)
data=f.read()
print(type(data)) #返回class ‘str‘
#想要保留数据的原本的格式,还需要将数据转化。
data_new=eval(data)
print(type(data_new))
print(data_new)
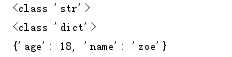
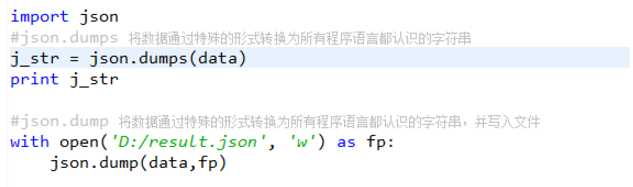
import json
info={‘name‘:‘zoe‘,‘age‘:18}
f=open(‘test.txt‘,‘w‘)
f.write(json.dumps(info)) #序列化。将info转换为字符串,写入文本文件中
f.close()
import json
f=open(‘test.txt‘,‘r‘)
data=json.loads(f.read()) #反序列化。用loads方法将字符串
print(data(type))
f.close()
>>> import json
>>> def sayhi(name):
print(‘hello,‘,name)
>>> info={‘name‘:‘zoe‘,‘age‘:18,‘func‘:sayhi}
>>> f=open(‘test.txt‘,‘w‘)
>>> f.write(json.dumps(info)) #函数sayhi的内存地址不是json可以序列化的参数。
Traceback (most recent call last):
File "

import pickle
def sayhi(name):
print(‘hello,‘,name)
info={‘name‘:‘zoe‘,‘age‘:18,‘func‘:sayhi}
f=open(‘test.txt‘,‘wb‘) #以二进制方式写入文件
f.write(pickle.dumps(info)) #pickle.dump(info,f)完全等价
f.close()

import pickle
def sayhi(name):
print(‘hello world‘,name)
f=open(‘test.txt‘,‘rb‘)
a=pickle.loads(f.read()) #完全等价于pickle.load(f)
print(a)
a[‘func‘](‘zoe‘)
‘‘‘如果反序列化中程序中没有sayhi()函数,则会报错。然而,在程序中有定义的同名的sayhi()函数即可读取并调用。
两个程序之间的内存地址是不能互相访问的,所以在函数序列化中,
pickle只能在python中使用。‘‘‘