在PYTHON中使用TMTOOLKIT进行主题模型LDA评估
2021-07-11 22:08
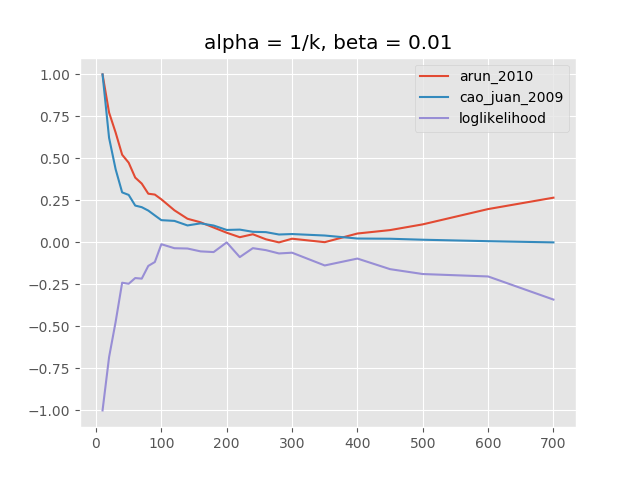
标签:意义 默认 不可 数值 配置 解释 eval 因此 top 主题建模的英文一种在大量文档中查找抽象艺术主题艺术的方法。有了它,就有可能发现隐藏或“潜在”主题的混合,这些主题因给定语料库中的文档而异。一种作为监督无的机器学习方法,主题模型不容易评估,因为没有标记的“基础事实”数据可供比较。然而,由于主题建模通常需要预先定义一些参数(首先是要发现的主题?的数量),因此模型评估对于找到给定数据的“最佳”参数集是至关重要的。 使用未标记的数据时,模型评估很难。这里描述的指标都试图用理论方法评估模型的质量,以便找到“最佳”模型。仍然重要的是要检查这个模型是否有意义。实际上评估模型质量的好一种方法的英文人在环路方法,人类必须手动插入随机“入侵者”字样或“主题入侵者”。不过,最好先选择理论方法最好的模型。 有些指标仅用于评估后验分布(主题 - 单词和文档 - 主题分布),而无需以某种方式将模型与观察到的数据进行比较。胡安等人。描述一种方法,该方法依赖于模型的主题 - 单词分布中所有主题之间的成对距离。他们声称主题之间的成对距离越高,模型捕获的信息密度越高。度量标准归结为计算每对分布的余弦相似度 主题建模的主要功能位于 接下来,我们加载由文档标签,词汇表(唯一单词)列表和文档 - 术语 - 矩阵组成的数据 现在我们定义应该评估的参数集我们设置了一个常量参数字典。 在这里,我们想要从一系列主题中计算不同的主题模型 我们现在可以使用模块中的 默认情况下,这将使用所有CPU内核来计算模型并并行评估它们。如果我们要评估4个CPU内核和26个模型,tmtoolkit将启动4个子进程并将前4个模型计算分配给它们,我们剩下22个。当在任何子过程上完成第一个模型计算时,第五个模型计算任务由该子过程启动,依此类推。这可确保所有子进程(以及所有CPU核心)始终处于忙碌状态。 函数评估将报道查看 该 主题模型评估,alpha = 1 / k,beta = 0.01 该图显示了各个度量的归一化值,即阿伦和涓的[0,1]之间的缩放值,以及对数似然的[-1,0]。我们可以看到对数似然最大值为k值在100和350之间.Arun度量指向200到400之间的值.Duan度量开始在k = 100附近最小化但在另一个范围内不会再次上升?。这可能是因为此方法仅评估主题词分布。由于语料库非常大(超过40万个单词),即使对于大K,计算的度量也可能非常低,因为主题词分布中的“密度”(即单词之间的成对距离)每个主题的分布)仍将非常高。 请注意,对于“loglikelihood”度量,仅报告最终模型的对数似然估计,这与Griffiths和Steyvers使用的调和均值方法不同。无法使用Griffiths和Steyvers方法,因为它需要一个特殊的Python包(gmpy2) ,这在我运行评估的CPU集群机器上是不可用的。但是,“对数似然”将报告非常相似的结果。 除了主题数量之外,还有alpha和beta(有时是文献中的eta)参数。两者都用于定义Dirichlet先验,用于计算各自的后验分布.Alpha是针对特定于文档的主题分布的先验的“浓度参数”,并且是针对主题特定的单词分布的先前的β 。两者都指出了关于主体和语料库中单词的稀疏性/同质性的先验信念。 阿尔法在文档中的主题稀疏性中起作用。高阿尔法值意味着主题稀疏性的影响较小,即预期文档包含大多数主题的混合,而低的α值意味着我们希望文档仅涵盖少数主题。这也是为什么alpha经常被设置为主题数量的一小部分(比如我们的评估中的1 / k):随着要发现的主题越来越多,我们希望每个文档都包含更少但更具体的主题。作为极端的例子:如果我们只想发现两个主题(k = 2),那么很可能所有文档都包含两个主题(不同的数量),因此我们有一个很大的alpha = 1/2值。如果我们想发现k = 1000主题,很可能大多数文档不会覆盖所有1000个主题,但只有一小部分(即稀疏性很高),因此我们采用alpha = 1/1000的低值来解释这个问题预期的稀疏性。 同样,β在主题中的单词稀疏性中起作用。高贝塔值意味着词稀疏性的影响较小,即我们期望每个主题将包含语料库的大部分词。这些主题将更“一般”,他们的单词概率将更加统一。低β值意味着主题应该更具体,即它们的单词概率将更不均匀,从而在更少的单词上放置更高的概率。当然,这也与要发现的主题数量。有关高的β意味着很少但更常见的主题被发现,低贝塔应该用于更具体的更多主题.Griffiths和Steyvers解释说,测试版“会影响模型的粒度:文档语料库可以合理地分解为不同规模的一组主题[...]。 主题模型,alpha = 1 / k,beta = 0.1 当我们使用与上述相同的alpha参数和相同的k范围运行评估时,但是当β= 0.1而不是β= 0.01时,我们看到对数似然在k的较低范围内最大化,即大约70到300(见上图)随着阿伦等人度量,它指向?在70和240之间的值因此,这证实了我们对测试的假设:。在尝试查找较少数量的主题时应使用较高的测试阶段。有趣的是,这次胡安度量也在给定?值范围内的曲线中显示了一个谷。这意味着,当使用具有许多主题的模型时,更高的测试值也会导致主题词分布中的信息密度降低。 组合这些参数有很多种可能性,但是解释这些参数通常并不容易。下图显示了不同情景的评估结果:(1)α和β的固定值取决于k,(2)α和β都固定, (3)α和β均取决于k。 (1)主题模型,alpha = 0.1,beta = 1 /(10k) (2)主题模型,alpha = 0.1,beta = 0.01 (3)主题模型,alpha = 1 / k,beta = 1 /(10k) LDA超参数α,β和主题数量都相互关联,相互作用非常复杂。认为对于给定的一组文档存在某种“正确”的参数配置是错误的。首先,重要的是要弄清楚模型应该是多么精细。如果它应该只涵盖一些但非常一般的主题,或者应该捕获更多更具体的主题。可以相应地设置阿尔法和测试阶段,并且可以计算一些示例模型(例如,通过使用 主题模型也可以在保留数据上进行验证。遗憾的是,所提到的用于主题建模的Python的软件包都没有正确计算保持数据的困惑,而tmtoolkit目前也没有提供这一点。此外,这甚至更加计算密集,特别是在进行交叉验证时。不过,将这些结果与交叉验证的结果进行比较会很有意思,这可以在将来的工作中完成。 ▍需要帮助?联系我们 在PYTHON中使用TMTOOLKIT进行主题模型LDA评估 标签:意义 默认 不可 数值 配置 解释 eval 因此 top 原文地址:https://www.cnblogs.com/tecdat/p/9550241.html概率LDA主题模型的评估方法
评估后部分布的密度或发散度
u*v/(|u|*|v|)(其中|u|和|v|是各个向量的L2范数)u和v在主题模型的后验主题 - 词分布中,然后取这些相似性的均值。平均值越低,主题越不相似,模型越好(至少通过此度量标准) 。使用美联社数据查找最佳主题模型
使用tmtoolkit计算和评估主题模型
tmtoolkit.lda_utils。模块中由于我们将使用LDA。包,因此我们需要先安装它才能使用特定于该包的评估函数我们可以从导入我们需要的功能开始:
dtm。我们确保dtm尺寸合适:
const_params,它将用于每个主题模型计算并保持不变我们还设置了。varying_params包含具有不同参数值的字典的不同参数列表: ks = [10, 20, .. 100, 120, .. 300, 350, .. 500, 600, 700]。由于我们有26个不同的值ks,我们将创建和比较26个主题模型。请注意,还我们alpha为每个模型定义了一个参数1/k(有关LDA中的α和测试超参数的讨论,请参见下文)。参数名称必须与所使用的相应主题建模包的参数匹配。在这里,我们将使用lda,因此我们通过参数,如n_iter或n_topics(例如,而与其他包的参数名称也会有所不同num_topics,不是而n_topics在gensim)。evaluate_topic_models函数开始评估我们的模型tm_lda,并将不同参数列表和带有常量参数的字典传递给它: eval_results所有游戏2元组的列表。这些元组中的每一个都包含一个字典,其中包含用于计算模型的参数以及各个度量返回的评估结果字典。随着results_by_parameter我们重组对于我们感兴趣的,我们要在X轴上绘制的参数结果: plot_eval_results函数使用在评估期间计算的所有度量创建33绘图。之后,如果需要,我们可以使用matplotlib方法调整绘图(例如添加绘图标题),最后我们显示和/或保存绘图。结果
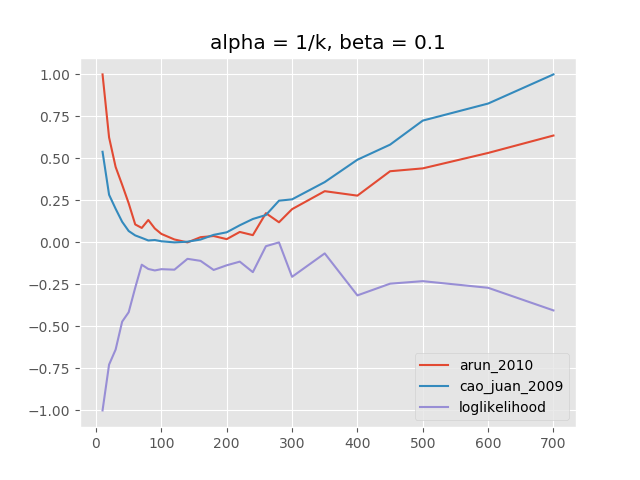
阿尔法和贝塔参数
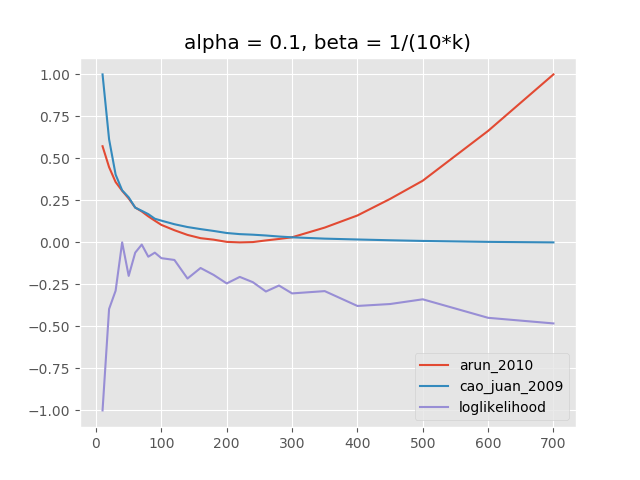
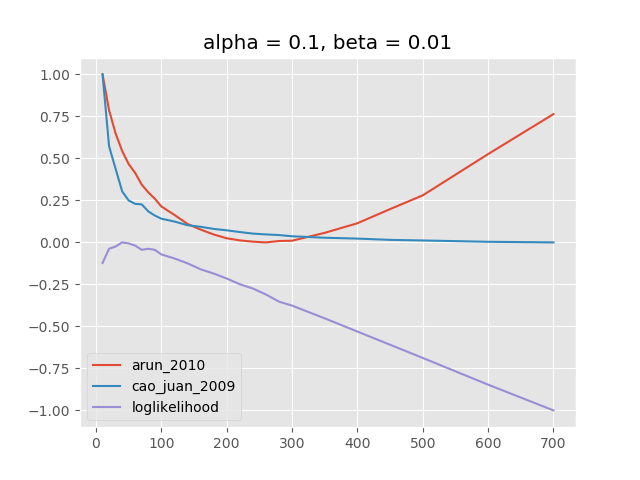
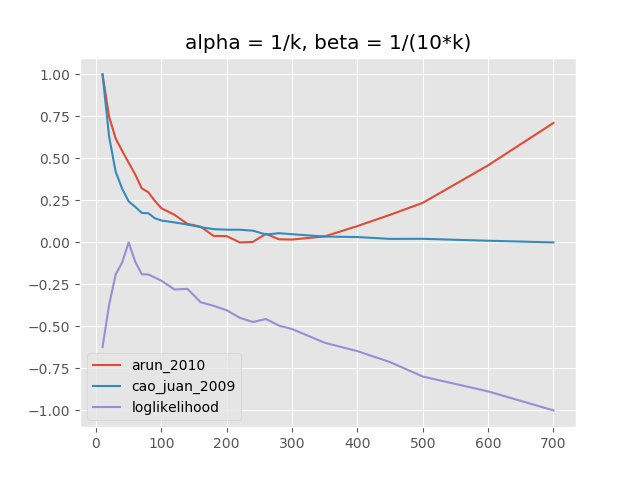
compute_models_paralleltmtoolkit中的函数)。在大多数情况下,用于定义模型“粒度”的beta的固定值似乎是合理的,这也是Griffiths和Steyvers所推荐的。一个更精细的模型评估,具有不同的alpha参数(取决于k)使用解释的指标可以完成很多主题。对保留数据的验证
文章标题:在PYTHON中使用TMTOOLKIT进行主题模型LDA评估
文章链接:http://soscw.com/essay/103883.html