C# 提取PDF文本和图片
2021-07-12 09:10
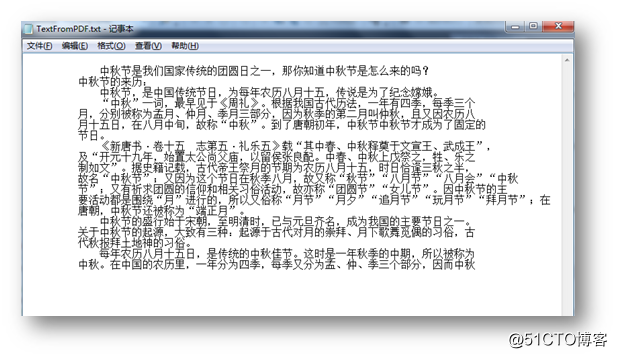
标签:doc ring ice end pre app href builder sys 【示例 1 】提取文本 文本提取效果: 图片提取效果: C# 提取PDF文本和图片 标签:doc ring ice end pre app href builder sys 原文地址:http://blog.51cto.com/eiceblue/2171752
所需工具:
实现代码:
using Spire.Pdf;
using System;
using System.IO;
using System.Text;
namespace ExtractText
{
class Program
{
static void Main(string[] args)
{
//加载文档
PdfDocument document = new PdfDocument();
document.LoadFromFile("测试文档.pdf");
//实例化StringBuilder类,获取文本
StringBuilder content = new StringBuilder();
content.Append(document.Pages[0].ExtractText());
//保存提取后的文本内容到.txt文档
String fileName = "TextFromPDF.txt";
File.WriteAllText(fileName, content.ToString());
System.Diagnostics.Process.Start("TextFromPDF.txt");
}
}
}
【示例 2 】提取图片using System;
using System.Collections.Generic;
using System.Text;
using System.Drawing;
using Spire.Pdf;
namespace ExtractImagesFromPDF
{
class Program
{
static void Main(string[] args)
{
//实例化PdfDocument类,并加载测试文档
PdfDocument doc = new PdfDocument();
doc.LoadFromFile("测试文档.pdf");
//实例化List类
List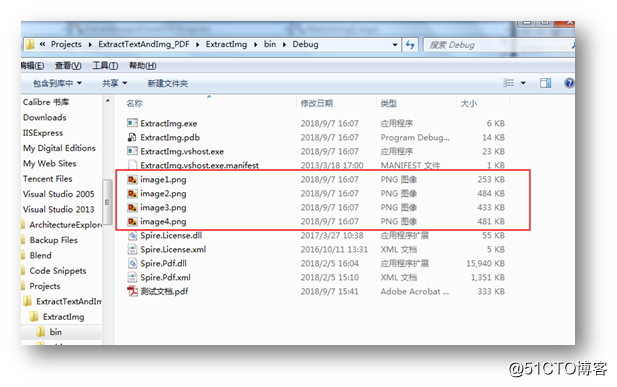
上一篇:windows 安装进化