python字符编码
2021-07-15 10:05
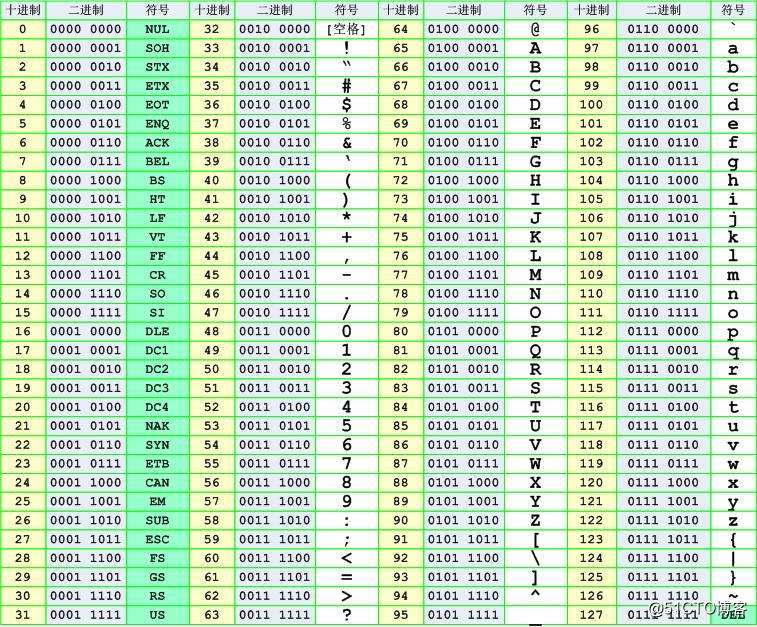
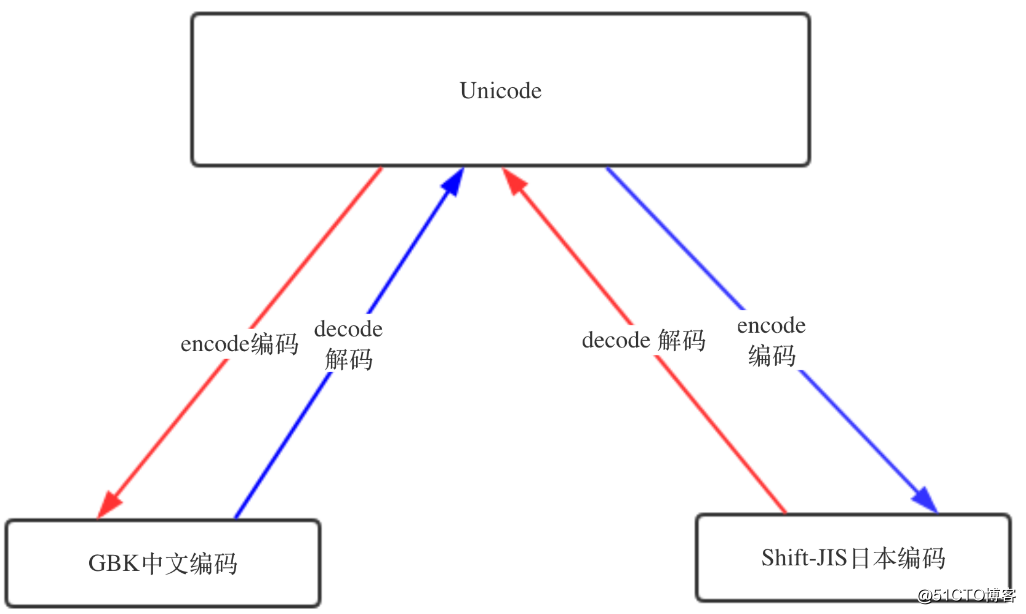
标签:获取 hello 显示 文件中 abc 种类型 ascii block 扩展 这里的字符指的是 人类能识别的字符,字符方便记忆。在计算机中,都是按照二进制存储,方便存储的是数字,所以,字符在计算机中的存储需要先转换为数字,然后再进行存储。 计算机出现之后,美国人搞出了一套ASCII,如下图。ASCII表中一个字符使用一个字节来表示,一个字节8位,最多只能表示256个字符(2**8 = 256)。表中的字符包括英文、字母、数字,还有一些特殊字符,这些字符和数字 之间存在一一对应关系,例如:97表示小写的a,65表示大写的A... 其实ASCII仅使用了一个字节中的7位来表示字符,一共127个字符(后128个称为扩展ASCII码)。ASCII是美国人发明的,所以除了英文,不能用于其他语言。于是中国人就指定了gb2312编码,其中包含了中文在内的字符 --> 数字的对应关系,日本人也制定了 Shift_JIS 编码,韩国人的 Euc-kr 编码等等,各国的人都有自己的一套标准。 这样在使用过程中,例如,一篇文档中仅有一种语言,那么 就不存在问题;但是如果这篇文档中存在多种语言,那么不管是用哪种编码标准,都会存在乱码问题,这时候 unicode 就应运而生,unicode 能够兼容万国字符,从而避免以上情况出现的乱码问题~ unicode 常用2个字节(16位二进制)代表一个字符,生僻字需要用4个字节。unicode 兼容 ascii,例如:小写字母x,用 ascii 表示是 0111 1000(二进制),使用 unicode 表示 为 0000 0000 0111 1000(二进制),可见 两者的值一致,只是使用 unicode 表示使用了2个字节,而是用 ascii 表示仅使用了一个字节,存储空间多了一倍~ unicode 中存放了与其他编码的映射关系,所以 unicode 可以兼容 万国字符。"unicode 中存放了与其他编码的映射关系" 这句话是不是不好理解,简单的说就是,unicode 编码 可以转为 其他编码,例如gbk、Shift_JIS等,其他的编码也可以通过 unicode 中存在的映射关系 转为 unicode 编码,转换的规则如下图: 通过如下示例来更进一步的解释,这张图表示 unicode 编码 和 gbk 等其他编码的映射关系(unicode映射表,截取而来),中文 ‘人‘ 字的 unicode 编码是 ‘4eba‘,对应的 gbk 编码是 ‘484b‘ python3环境 单引号或双引号中以 \u 开头的都是 unicode 码,unicode 码对每一个字符用4位16进制数表示。具体规则是:将一个字符(char)的高8位与低8位分别取出,转化为16进制数, 如果转化的16进制数的长度不足2位,则在其后补0,然后将高、低8位转成的16进制字符串拼接起来并在前面补上 "\u" 。 汉子 ‘中‘ 由 unicode 编码转为 gbk 编码后,显示的 gbk 编码为 ‘c8cb‘,和图中的 ‘484b‘ 便不符合,这是因为GBK 的编码为了兼容 ASCII,即如果是英文,就用一个字节表示,2个字节就是中文,如果1个字节的第一位(最左边一位)是0表示是 ASCII,如果连续的2个字节的第一位都是1,那么这2个字节表示为一个中文,所以这里的 ‘c8cb‘ 去掉首位的1后,就是 ‘484B‘ ~ ASCII 使用一个字节表示一个字符,而 unicode 需要2个字节,这样对于英文的文本而言,存储空间就多了一倍,于是就有了 UTF-8(可变长存储,Unicode Transformation Format),UTF-8 简称万国码,可以统一显示中文简体繁体及其它语言(如英文,日文,韩文)。UTF-8 编码中英文字符只使用1字节表示,中文字符用3字节,其他生僻字使用更多的字节存储~ 在内存中的字符统一使用 unicode 编码,这样可以避免乱码问题,当数据需要存储到硬盘或者在网络之间进行传递时,再将 unicode 编码转为 其他编码标准(现在大多数情况都是UTF-8,也推荐使用UTF-8),因为这样更节省空间,也可以减小网络的传输压力。 当数据需要重新读入内存,就需要通过解码转为 unicode,之前使用何种方式编码存放到磁盘,就需要使用同一种编码标准进行解码。大致过程如下(UTF-8): 这样也许有人会问,为什么内存中不直接使用 utf-8 编码标准,utf-8 中囊括了所有语言,那是因为现在很多软件还在使用各国的编码标准(例如Shift_JIS,GBK,Euc-kr的等),utf-8 编码标准中不存在 和这些编码的映射关系(简而言之就是 Shift_JIS,GBK,Euc-kr等这些编码无法转换为 utf-8编码,utf-8编码也不能转换为这些编码),而 unicode 中存在,所以内存中一律使用 unicode 编码标准可以避免乱码问题。utf-8 的出现主要是为了减小存储的空间,如果哪一天所有的软件都是使用 utf-8 编码标准,那数据读取到内存中也不需要再转为 unicode。 常见的编码问题一般有2种: --第一种情况 保存后重新打开: 出现如上情况的问题在于,在使用Euc-kr 编码存储时就已经发生了错误,韩文使用 Euc-kr 编码(unicode --> Euc-kr)没有问题,但是中文这个过程无法完成,导致编码失败,数据无法恢复~ --第二种情况 重新 使用其他编码标准 解码后打开 出现了乱码,文本编码后存储没有问题,但是在打开文件时使用了错误的解码方式。这里只要调整解码方式就可以,不会导致数据丢失! 总结: 3、推荐使用 utf-8 编码标准,多国的文字可以同时存在于一个文本中~ 执行python程序,首先会启动 python解释器,然后 python解释器会以 py文件 最前面2行指定的编码方式来将py文件的内容读入内存,定义编码常用的方式如下: 如上语句必须放在py文件的第一行或者第二行~ 若py文件中不指定编码方式,则 python2 默认使用 ASCII,python3 默认使用 UTF-8。这个可以通过sys.getdefaultencoding() 查看 python3环境 python解释器加载代码到内存后,代码在内存中都是以 unicode 的格式存放的,但是当解释器执行到存放字符串的语句时,例如:my_str = ‘hello kitty‘,python解释器会申请内存,然后将字符串编码成 py文件开头指定的编码格式进行编码,然后存放。python2中都是以上述过程存放字符串的;在python3中,字符串统一都是用 unicode 格式存放,python3中这样做 避免了很多不必要的麻烦~~ --str类型 Tip:查看字符串在内存中存放的真实格式,可以通过print元组或列表查看,直接print 会自动转换编码~ --unicode类型 Tip:字符串前面加个u,即字符串保存为 unicode 格式~ unicode字符串 可通过编码,转换为其他编码格式保存 在python3中,python解释器将字符串保存至新申请的内存上,默认使用的就是unicode。 Tip: 查看python2中的 bytes 源代码: python2中的bytes是为了兼容python3的写法,python2 中 bytes 类型直接使用了str类型,所以: 使用sys模块中的getdefaultencoding可获取python的默认编码方式: 可以看到python2中的默认编码是ascii,python3中的是utf-8。字符串在encode和decode时(转换为unicode或从unicode转为其他编码)默认使用getdefaultencoding输出的编码格式,这个在python2中应用较多,python3中由于字符串一律使用unicode存放,所以应用较少~ python3中,当str类型(unicode)和bytes类型合并时,会直接报错 但是在python2中,这个过程可以进行,Python解释器会把 str 转换成 unicode 再进行运算,运算结果也都是 unicode类型,但是使用默认编码(ascii)将str转成unicode,会出现如下错误: 调整一下默认编码,就可以正常输出: python2中字符串直接输出到终端 和 字符串的编码标准(以什么标准编码存放在内存上)即 终端编码有关(例如windows终端编码为gbk,pycharm终端编码为utf-8),两者一致,才能避免乱码 python3中有所区别,字符串默认使用unicode格式保存在内存中,这样无论输出到哪个终端都不会有乱码问题;若将字符串转为其他编码格式,则终端不会将其转为字符格式,而是原样输出 两者输出结果一致~ python字符编码 标签:获取 hello 显示 文件中 abc 种类型 ascii block 扩展 原文地址:http://blog.51cto.com/ljbaby/2164480什么是字符编码
存储过程:字符 --> 数字,读取过程:数字 --> 字符 ~
以上两个转换过程中,字符和数字之间存在一个一一对应的关系,一个字符对应一个特定的数字,这个一一对应的关系就是所谓的字符编码~字符编码问题
unicode介绍

>>> x = ‘\u4eba‘ # unicode 码
>>> x
‘人‘
>>> x.encode(‘gbk‘) # 转为 gbk 编码
b‘\xc8\xcb‘
>>> b‘\xc8\xcb‘.decode(‘gbk‘) # gbk 编码转为 unicode 码
‘人‘
unicode 和 UTF-8
unicode(内存) -----> encode 编码 -------->utf-8(磁盘)
utf-8(磁盘) --------> decode 解码 ---------->unicode(内存)常见的编码问题
在数据存储时,编码错误。示例如下,文本中既有中文又有韩语,但是在存储时使用 Euc-kr 编码标准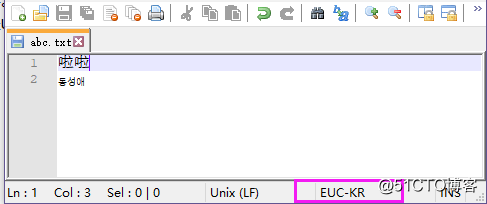
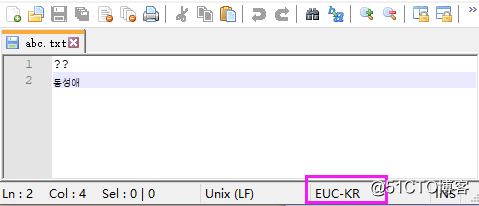
数据正确编码后存储,在读取时使用了错误的编码
文本中只有韩文,且使用 Euc-kr 编码后保存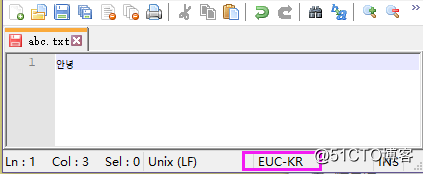
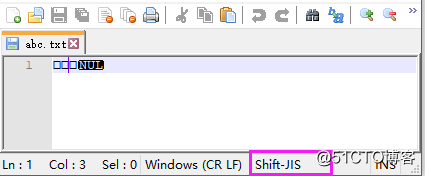
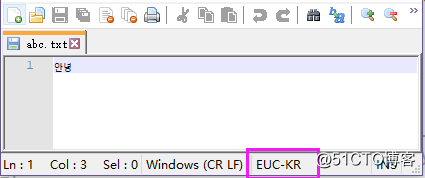
重新设置成 Euc-kr 就可以
1、内存中字符的存储都是使用 unicode 编码,在写入到磁盘或者进行网络传输时才会将 unicode 编码转换成其他编码标准
2、在写入到磁盘上或者进行网络传输时,使用什么编码标准 进行编码,之后就需要使用同样的编码标准进行解码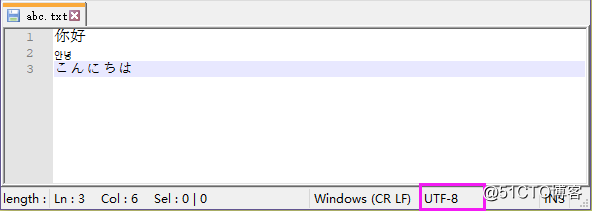
python中的编码
py文件的编码
1)# coding=
python2环境luyideMacBook-Pro:~ baby$ python
Python 2.7.10 (default, Oct 6 2017, 22:29:07) ...
>>> import sys
>>> sys.getdefaultencoding()
‘ascii‘C:\Users\Baby>python
Python 3.6.4 (v3.6.4:d48eceb, Dec 19 2017, 06:54:40)...
>>> import sys
>>> sys.getdefaultencoding()
‘utf-8‘python2中的str和unicode类型
如上所说,python2中的字符串都是以 py文件开头指定的编码格式进行编码后存放
python2环境# -*- coding: utf-8 -*-
my_str = ‘你好‘
print type(my_str)
print (my_str,)
输出结果:
python2环境# -*- coding: utf-8 -*-
my_str = u‘你好‘
print type(my_str)
print (my_str,)
输出结果:
# -*- coding: utf-8 -*-
my_str = u‘你好‘
print (my_str.encode(‘utf-8‘),)
输出结果:
(‘\xe4\xbd\xa0\xe5\xa5\xbd‘,)python3中的str和bytes类型
x = ‘你好‘ # 默认就使用unicode保存到内存中,前面无需加 u
print(type(x)) #
1)python3中的字符串默认就是以unicode形式保存,与python2中的 x = u‘你好‘ 语句类似
2)python3中的字符串 x = ‘你好‘ 使用 utf-8 编码后输出的结果是 b‘\xe4\xbd\xa0\xe5\xa5\xbd‘,这与python2中的 "my_str = ‘你好‘;print ((my_str,))" (# -- coding: utf-8 --)输出结果一致。.....python2中的 str 类型就是 python3 中的 bytes 类型~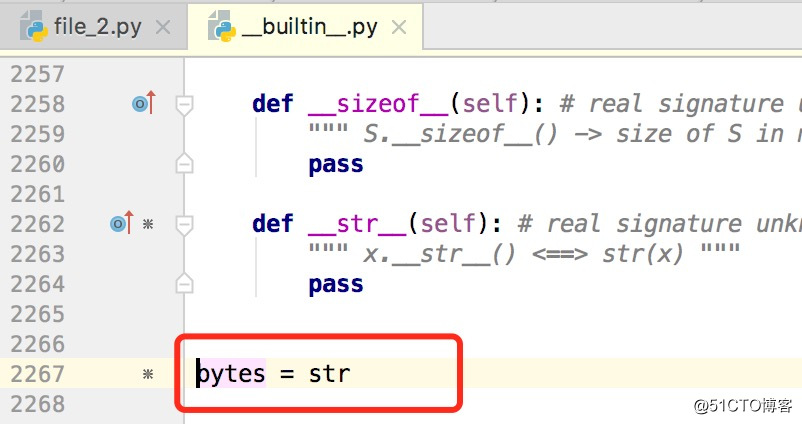
python2中的字符串有3种类型:unicode、str、bytes,其中bytes和str为同一个类型~
python3中的字符串有2种类型:str 和 bytes,str就是python2中的unicode,bytes就是python2中的str~sys模块中的getdefaultencoding和setdefaultencoding
# python2
import sys
print sys.getdefaultencoding()
输出结果:
ascii
# python3
import sys
print(sys.getdefaultencoding())
输出结果:
utf-8x = ‘你好,‘ # str类型
y = ‘贝贝‘.encode(‘utf-8‘) # bytes类型
print(x + y)
报错信息:
TypeError: must be str, not bytes# -*- coding: utf-8 -*-
x = u‘你好,‘
y = ‘贝贝‘
print(x + y)
错误信息:
UnicodeDecodeError: ‘ascii‘ codec can‘t decode byte 0xe8 in position 0: ordinal not in range(128)# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding(‘utf-8‘)
x = u‘你好,‘
y = ‘贝贝‘
print(x + y)
输出结果:
你好,贝贝字符串打印到终端
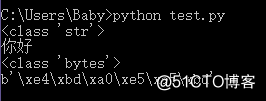
x = ‘你好‘
y = x.encode(‘utf-8‘)
print(type(x))
print(x)
print(type(y))
print(y)
pycharm 输出结果:
.................^_^