Neural Networks Learning----- Stanford Machine Learning(by Andrew NG)Course Notes
2020-11-16 07:42
标签:style blog http color 使用 os 本栏目内容来自Andrew NG老师的公开课:https://class.coursera.org/ml/class/index 一般而言,
人工神经网络与经典计算方法相比并非优越,
只有当常规方法解决不了或效果不佳时人工神经网络方法才能显示出其优越性。尤其对问题的机理不甚了解或不能用数学模型表示的系统,如故障诊断、特征提取和预测等问题,人工神经网络往往是最有利的工具。另一方面,
人工神经网络对处理大量原始数据而不能用规则或公式描述的问题,
表现出极大的灵活性和自适应性。 神经网络模型解决问题的一般步骤 1.
模型选择
要确定一个神经网络的结构(神经元的连接模式),需要包括以下几个方面: — 输入单元的个数:特征 x(i) 的维数; — 输出单元的格式:类的个数
— 隐藏层的设计:比较合适的是1个隐藏层,如果隐藏层数大于1,确保每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数越多越好。 2.
模型训练 — 参数的随机初始化 — 前向算出每个节点(神经元)的输出(激励函数值) — 反向传播算法用于计算偏导数即每个参数的梯度; — 利用数值检验方法检验这些偏导数,因为模型比较复杂,看看模型对不对 — 在反向传播的基础上使用梯度下降或其他优化算法来最小化损失函数 Cost
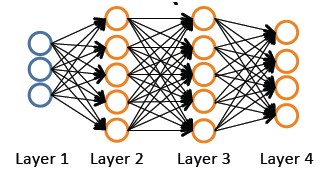
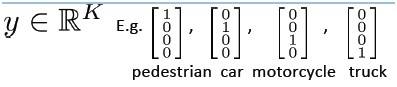
Function 神经网络的结构 模型表示: 训练集:(x(1),y(1)),...,(x(m),y(m)) L:一个神经网络中的层数 Sl:第l层的处理单元的个数 SL:最后一层中处理单元的个数。 K:分类的个数,与SL相等。 对于一个分类问题: 如果是一个二类分类(Binary
classification),那么y = 0 或1,在神经网络的输出层上只有一个输出单元;如果是一个多类分类(Multi-class
classification), 那么在神经网络的输出层上有K个输出单元。 在logistc
regression问题中,我们的costfunction为: PS:我们只有一个输出变量y,但在神经网络中,我们可以有很多输出变量,hθ(x)是一个维度为K的向量,训练集中的y也是同样维度的向量,因此我们的cost
function会比逻辑回归更加复杂一些:
其中J(θ)的第一部分是对所有的结果的一个输出节点的损失函数和,第二部分是所有的权值的正则化。 其实这个看起来复杂很多的cost
function背后的思想还是一样的,我们希望通过损失函数来观察算法预测的结果与真实情况的误差有多大,唯一不同的是,对于每一行特征,我们都会给出K个预测,然后在K个预测中选择可能性最高的一个,将其与y中的实际数据进行比较。而归一化的那一项只是排除了每一层的偏置θ0后,对每一层的矩阵求和。j为行号(由+1层的激活单元数决定),i为列号,由该层(层)的激活单元数所决定。 反向传播算法 和linear
regression或logistic
regression相似,求取神经网络的参数也可以采用梯度下降算法,但是神经网络相对复杂,怎样计算它的梯度呢? Cost
Function: Goal: 我们需要通过如下两个式子来计算梯度: 在“Neural Networks:
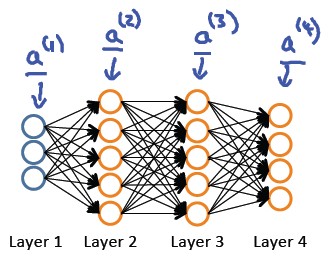
Representation”一课中,给出了前馈网络计算方法(feedforword
network),即在计算神经网络预测结果时采用的一种正向传播方法,我们从第一层开始正向一层一层进行计算,直到最后一层(输出层)的hθ(x)。例如对于如下4层神经网络: 有了神经网络的“表示”,如何计算梯度?这个时候,我们引入反向传播算法,简称BP算法。 BP算法思路: 给定一个样例(x,y),我们首先进行“feedforword”运算,计算出网络中所有的激活值,包括hw,b(x)的输出值。之后,针对第 l 层的每一个节点 i,计算出其“残差”:δi(l)(第 l 层第 i 个节点的残差),该残差表明了该节点对最终输出值的残差产生了多少影响。对于最终的输出节点,我们可以直接算出网络产生的激活值与实际值之间的差距,我们将这个差距定义为δi(nl)
(第nl层表示输出层)。对于隐藏单元我们如何处理呢?我们将基于节点(第
l+1 层节点)残差的加权平均值计算 δi(l),这些节点以ai(l)作为输入。下面以四层神经网络为例,说明BP算法: 假设我们的训练集只有一个实例(x(1),y(1)),我们的神经网络是一个四层的神经网络,其中K=4,SL=4,L=4: 对于神经网络输出层的单元来说,误差的计算比较直观:δj(4) = aj(4) -
yj 我们利用这个误差值来计算前一层的误差:δ(3) = (θ(3))Tδ(4).*g‘(z(3))
PS:其中g‘(z(3))是Sigmoid函数的导数,g‘(z(3))
= a(3).*(1-a(3) ) (推导方法见附录), 而(θ(3))Tδ(4)则是权重导致的误差的和。 同理,第二层的误差: δ(2) = (θ(2))Tδ(3).*g‘(z(2)) 由于第一层是输入变量,不存在误差。这样我们有了所有误差的表达式后,便可以计算代价函数的偏导数了,假设 λ=0 ,即我们不做任何归一化处理时有: 一个完整的BP算法:
我们需要为整个训练集计算误差单元,此时的误差单元也是一个矩阵,用Δij(l)来表示这个误差矩阵元素。第l层的第i个激活单元受到第j个参数影响而导致的误差。 前馈网络和BP神经网络的关系
前馈是从网络结构上来说的,是前一层神经元单向馈入后一层神经元,而后面的神经元没有反馈到之前的神经元;而BP网络是从网络的训练方法上来说的,是指该网络的训练算法是反向传播算法,即神经元的链接权重的训练是从最后一层(输出层)开始,然后反向依次更新前一层的链接权重。 随便提一下BP网络的强大威力(参考52opencourse):
— 任何的布尔函数都可以由两层单元的网络准确表示,但是所需的隐藏层神经元的数量随网络输入数量呈指数级增长;
— 任意连续函数都可由一个两层的网络以任意精度逼近。这里的两层网络是指隐藏层使用sigmoid单元、输出层使用非阈值的线性单元;
— 任意函数都可由一个三层的网络以任意精度逼近。其两层隐藏层使用sigmoid单元、输出层使用非阈值的线性单元。
利用octave实现神经网络算法的一个小技巧:在Octave中,如果我们要使用fminuc这样的优化算法来求解求出权重矩阵,我们需要将矩阵首先展开成为向量,在利用算法求出最优解后再重新转换回矩阵。具体可以参考课程视频。 梯度检验
神经网络算法是一个很复杂的算法,使用梯度下降算法时,可能会存在一些不容易察觉的错误,意味着,虽然代价看上去在不断减小,但最终的结果可能并不是最优解。为了避免这样的问题,我们采取一种叫做梯度的数值检验(Numerical Gradient
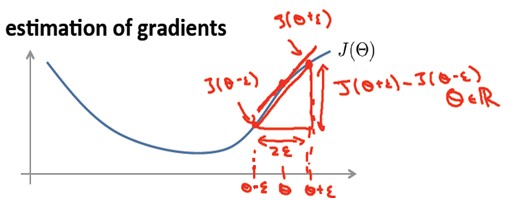
Checking)方法。这种方法的思想是通过估计梯度值来检验我们计算的导数值是否真的是我们要求的。 例如,对于一元参数: 对梯度的估计采用的方法是:在cost
function上沿着切线的方向选择离两个非常近的点然后计算两个点的平均值用以估计梯度。即对于某个特定的θ,我们计算出在 θ-ε 处和 θ+ε 的代价值(ε是一个非常小的值,通常选取0.001),然后求两个代价的平均,用以估计在θ处的代价值。 同理对于多元参数或参数向量来说,上述方法同样适用: 这样针对每一个θ计算一个近似的梯度值,将计算出来的偏导数与该近似值进行比较。目标是检查这个梯度的近似向量与反向传播算法得到的梯度向量是否近似相等: 注意:
—首先实现反向传播算法来计算梯度向量DVec; —其次实现梯度的近似gradApprox; —确保以上两步计算的值是近似相等的;
—在实际的神经网络学习时使用反向传播算法,并且关掉梯度检查,否则在梯度下降的每轮迭代中都运行数值化的梯度计算,程序将会非常慢。 随机初始化 关于如何学习一个神经网络基本说完了,不过还有一点需要注意,就是如何初始化参数向量or矩阵。通常情况下,我们会将参数全部初始化为0,这对于很多问题是足够的,但是对于神经网络算法,会存在一些问题。 对于梯度下降和其他优化算法,对于参数Θ向量的初始化是必不可少的。能不能将初始化的参数全部设置为0? 在神经网络中,如果将参数全部初始化为0,即θij(l)
=
0
,会导致一个问题:在每轮参数更新的时候,与输入单元相关的两个隐藏单元的结果将是相同的,即:a1(2)
= a2(2)
简单来说,如果我们令所有的初始参数都为0,这将意味着第二层的所有激活单元都会有相同的值。同理,如果我们初始所有的参数都为一个非0的数,结果也是一样的,这个很容易理解。
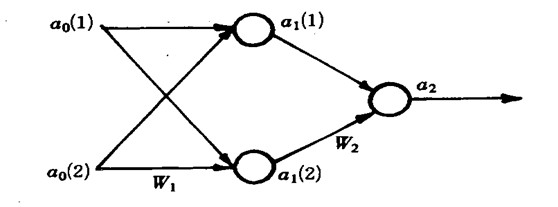
这个问题又称之为对称的权重问题,因此我们需要打破这种对称,这里提供一种随机初始化参数向量的方法: 初始化 Θij(l)为一个落在 [??,?]区间内的随机数, ? 可以很小,但是与梯度检验中的 ? 没有任何关系。 例子-蚊子的分类 下面我们从一个具体的问题来看神经网络是怎样使用的,已知的两类蚊子的数据如表1: 输入数据有15个,即 p=1,…,15; j=1, 2;
对应15个输出。 建立神经网络: 规定目标为: 当t=0.9
时表示属于Apf类,t=0.1表示属于Af类。 设两个权重系数矩阵为: 其中wi(j,3)
= θi(j) 是阈值 第二层激励值计算: 第二层激励函数值: 同理第三层的计算结果: 具体流程: 1. 随机给出两个权矩阵的初值;
W1(0) =
rand(2,3); W2(0) =
rand(1,3);
2. 根据输入数据利用前向算出网络的输出 取 a0(3) = -1,
a1(3) = -1
3. 根据后向计算误差和偏导数
4. 利用数值检验方法检验这些偏导 略 5.
最小化代价函数训练 略 HOMEWORK 好了,既然看完了视频课程,就来做一下作业吧,下面是Neural
Networks Learning部分作业的核心代码: 1.
nnCostFunction.m 2. sigmoidGradient.m 附录 1.误差公式推导 2. g‘(z(3))公式推导 Neural Networks Learning----- Stanford Machine Learning(by
Andrew NG)Course Notes,搜素材,soscw.com Neural Networks Learning----- Stanford Machine Learning(by
Andrew NG)Course Notes 标签:style blog http color 使用 os 原文地址:http://www.cnblogs.com/tec-vegetables/p/3699438.html
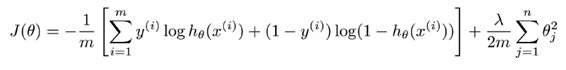
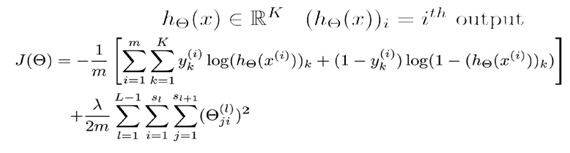
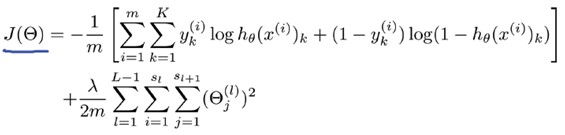
![]()
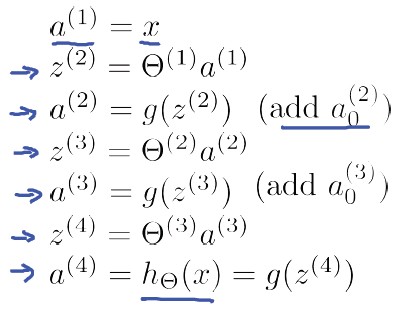
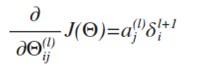

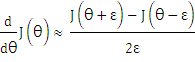


翼长
触角长
类别
目标值
1.78
1.14
Apf
0.9
1.96
1.18
Apf
0.9
1.86
1.20
Apf
0.9
1.72
1.24
Af
0.1
2.00
1.26
Apf
0.9
1.96
1.30
Apf
0.9
1.74
1.36
Af
0.1
1.64
1.38
Af
0.1
1.82
1.38
Af
0.1
1.90
1.38
Af
0.1
1.70
1.40
Af
0.1
1.82
1.48
Af
0.1
1.82
1.54
Af
0.1
2.08
1.56
Af
0.1
2.00
1.28
Apf
0.9
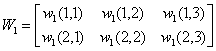
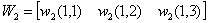
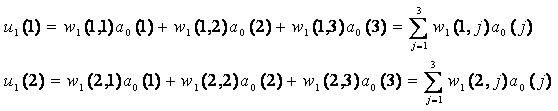
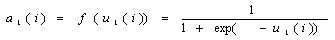 i=1,2
i=1,2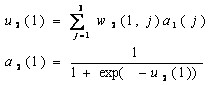
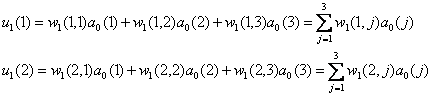 i=1,2
i=1,2
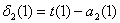
![]() ..........
..........


1 a1 = [ones(m,1) X]; %5000*401
2 z2 = a1 * Theta1‘; %5000*25
3 a2 = sigmoid(z2); %
4 a2 = [ones(size(z2,1),1) a2]; %5000*26
5 z3 = a2 * Theta2‘; %5000*10
6 a3 = sigmoid(z3);
7 h = a3;
8
9 %cal J
10 yk = zeros(m, num_labels);
11 for k = 1:m
12 yk(k,y(k)) = 1;
13 end
14 J = sum(sum(((-yk).*log(h) - (1-yk).*log(1 - h))));
15 J = J/m;
16 reg = (lambda/(2*m))*(sum(sum(Theta1(:,2:end).^2)) + sum(sum(Theta2(:,2:end).^ 2)));
17 J = J + reg;
18 % -------------------------------------------------------------
19 for k = 1:m
20 a1 = [1 X(k,:)]‘; %401*1
21 z2 = Theta1 * a1; %25*1
22 a2 = [1;sigmoid(z2)]; %26*1
23 z3 = Theta2 *a2; %10*1
24 a3 = sigmoid(z3);
25
26 z2 = [1;z2]; %26*1
27 delta3 = a3 - yk‘(:,k); %10*1
28 delta2 = (Theta2‘*delta3).*sigmoidGradient(z2);
29 delta2 = delta2(2:end);
30
31 Theta1_grad = Theta1_grad + delta2*a1‘;
32 Theta2_grad = Theta2_grad + delta3*a2‘;
33 end
34
35 Theta1_grad = Theta1_grad / m;
36 Theta2_grad = Theta2_grad / m;
37 reg_theta1 = lambda/m*Theta1;
38 reg_theta2 = lambda/m*Theta2;
39 reg_theta1(:,1) = 0;
40 reg_theta2(:,1) = 0;
41 Theta1_grad = Theta1_grad + reg_theta1;
42 Theta2_grad = Theta2_grad + reg_theta2;
gz = sigmoid(z);g = gz.*(1-gz);

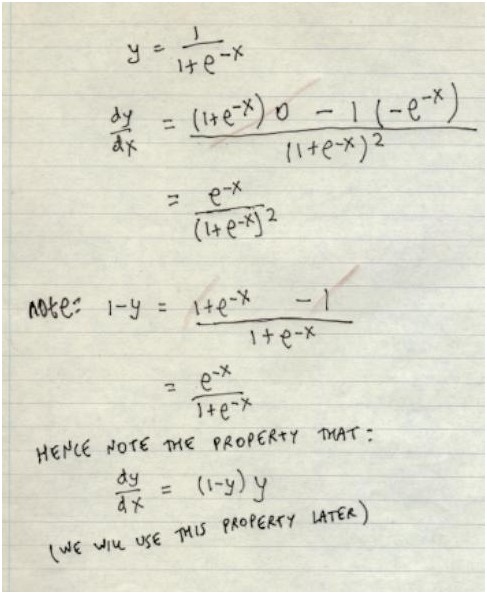
文章标题:Neural Networks Learning----- Stanford Machine Learning(by Andrew NG)Course Notes
文章链接:http://soscw.com/essay/21615.html