我也要谈谈大型网站架构之系列(2)——纵观历史演变(下)
2020-11-16 18:59
标签:style blog http color os 数据 这篇文章本来准备前几天就得写的,谁也没想到这段时间公司的RC太多了,含酸苦逼的加班,加班。。。所以在大一点的公司上班, 写代码的责任心一定要强,或许就因为你的一些小bug,给公司带来不少损失。。。这在以前公司真的没多大体会的。 好了,继续说说架构的演变,从第四代架构中可以看到,我们通过做应用程序层的负载均衡可以比较完美的解决了在整个架构中让应 用程序层不再成为瓶颈,通过A10,我们可以让用户的访问请求分发到集群中的任何一台服务器上,当访问量继续膨胀的时候,我们就可 以继续在集群中增加服务器来解决负载的压力,达到系统的可伸缩性,现在我们的业务规模像滚雪球一样越来越大,用户数暴增。。。这 时候我们缓存中的数据也越来越多,虽然我们用了缓存,但是大量的“缓存过期重新读取”和“缓存不命中",导致数据库压力非常大,这时候 数据库的压力成为了我们架构中的瓶颈。 五: 第五代架构 既然数据库成为了我们第四代架构的瓶颈,这时候必须解决数据库的压力问题,最常见的做法也就是“读写分离”,将写和读的库进行拆 分来缓解数据库的压力。 现在我们做了多个库,写的时候进主库,然后数据库分发到从库中,然后应用程序在从库中读取,这里为了让数据库对应用程序更加 透明,我们通常加一个“数据访问层”,在携程里面就是在企业库上进行了一层封装以及安全性采用了all in one 模式,可以看到第五代 架构对数据库的压力有了很大的缓解。 经过几个月业务喷井式的发展之后,我们会发现数据库检索越来越慢,单表数据量已经差不多爆炸了。。。已经严重影响到系统性能, 用户抱怨不断,这时候“数据检索”成为了我们系统的严重瓶颈。 六:第六代架构 既然检索成了瓶颈,我们必须对数据库进行拆分,尽可能的减少检索中的数据量规模以及尽可能的优化算法。 1:业务分库
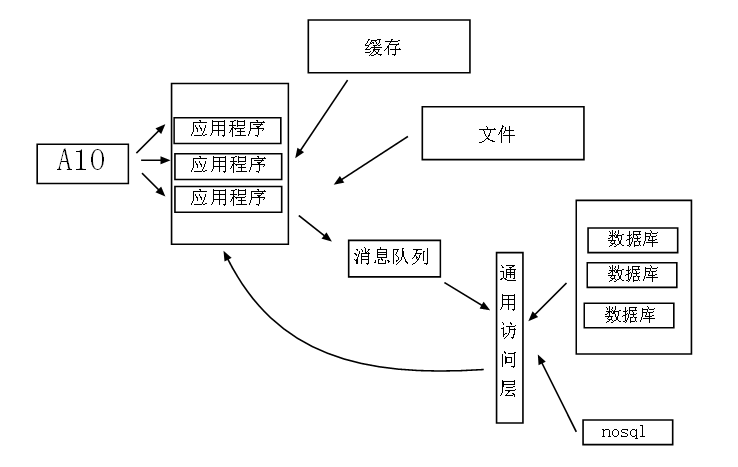
我们将不同的业务分摊到不同的业务服务器上,而不是将其耦合在一个数据库里面,从而建立起数据库集群,分流应用层对数 据库的压力。 2:分表 可以采用时间划分,将三个月之后的数据放入到历史表里面,当前表只保存三个月之内的数据,而从极大提供单表的检索能力。 3:采用nosql nosql就是为了web而生,分词,系统日志等等,一样都让不少nosql,而且nosql有其天生的负载均衡。 4:优化算法 栈,队列,二叉树,哈希 等等变换和非变换的数据结构在这种大数据的场景下可以得到灵活运用,这也是区分高级程序员和低等 码农的一条参考标准。
当你的架构到这个程度的时候,差不到公司的人数也过千了,这时候我们的业务会分成很多产品线的,比如:机票事业部,酒店 事业部,旅游度假事业部,攻略社区事业部,每个事业部只会负责自己的产品架构,从而将我们的架构再次细分,从技术角度看,这些 事业部又可以提炼出公共的部门,比如登录模块,订单处理等等这些可复用的模块,可以相应的成立公共平台事业部和框架架构部,当 这个架构继续往下发展的话,就有了现在的各种云,也就成了各种变钱的工具了,就比如现在的博客园托管在阿里云之上。。。 终于在今天,结束了高层重视的IVR项目的所有事情,最后祭奠一下,自从猪猪侠拿到那些所谓的数据,导致我们连续加班的日日夜夜。 我也要谈谈大型网站架构之系列(2)——纵观历史演变(下),搜素材,soscw.com 我也要谈谈大型网站架构之系列(2)——纵观历史演变(下) 标签:style blog http color os 数据 原文地址:http://www.cnblogs.com/huangxincheng/p/3700470.html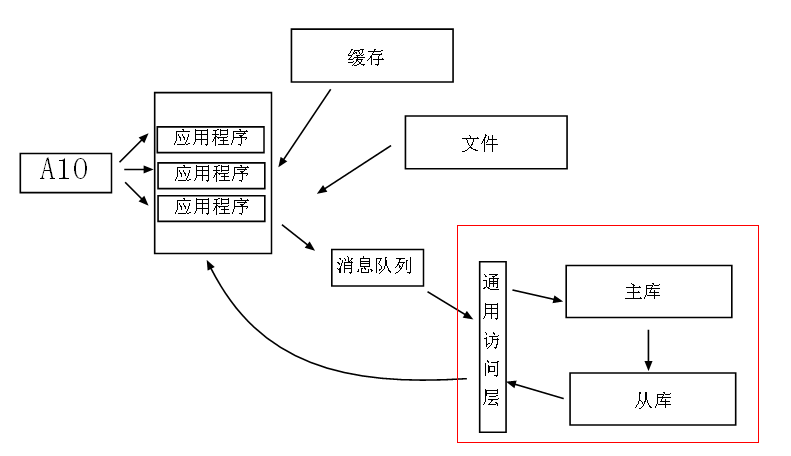
上一篇:mvc架构模式概念
文章标题:我也要谈谈大型网站架构之系列(2)——纵观历史演变(下)
文章链接:http://soscw.com/essay/21680.html