config.json 预训练模型调参
2020-12-27 11:27
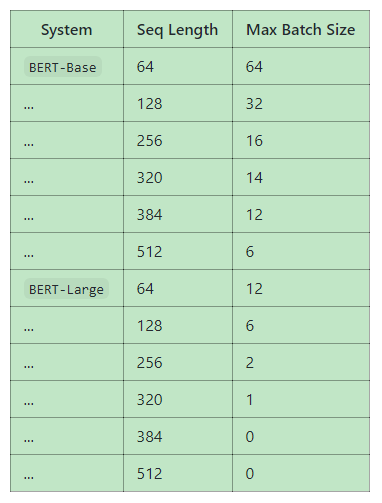
标签:论文 seq check iba 迭代 poi ram upd normal (来自BERT论文) config文件定义了模型的超参数。 但是,由于此模型在64GB内存上训练,所以如果个人使用的话,需要调整超参数。 内存大小影响因子包括: 用默认训练脚本 (run_classifier.py 和 run_squad.py), 获得基准后的maximum batch size 在一个单独的 Titan X GPU (12GB RAM) 和 TensorFlow 1.11.0: BERT-large 的 max batch size相当小,以至于确实损害模型精度。我们正在努力增大batch size值。我们通过以下方法增加batch size值。 (后面与普通人无关) Gradient accumulation: The samples in a minibatch are typically independent with respect to gradient computation (excluding batch normalization, which is not used here). This means that the gradients of multiple smaller minibatches can be accumulated before performing the weight update, and this will be exactly equivalent to a single larger update. Gradient checkpointing: The major use of GPU/TPU memory during DNN training is caching the intermediate activations in the forward pass that are necessary for efficient computation in the backward pass. "Gradient checkpointing" trades memory for compute time by re-computing the activations in an intelligent way. config.json 预训练模型调参 标签:论文 seq check iba 迭代 poi ram upd normal 原文地址:https://www.cnblogs.com/Neteraxe/p/13874861.html