Kubernetes (一)K8S入门
2021-01-08 12:34
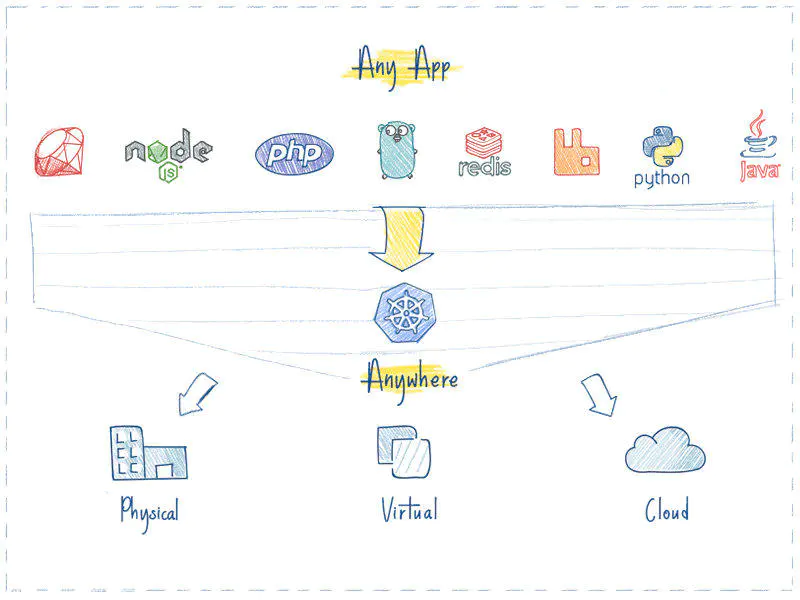
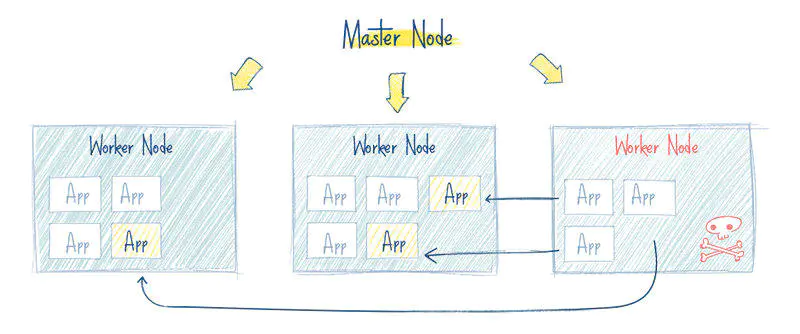
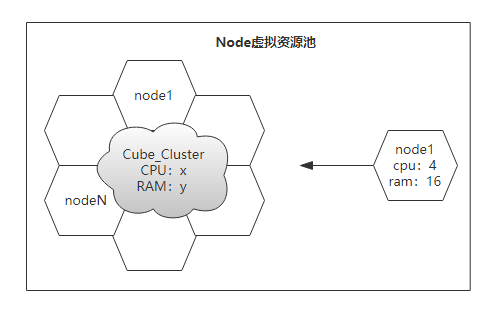
标签:新版 管控 master label 辅助 lse 响应 spl 扩容 1. K8S是一个全新的基于容器技术的分布式架构领先方案,用于管理云平台中多个主机上的容器化的应用。Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规划,更新,维护的一种机制,能够自主管理容器来保证云平台中的容器按照用户期望的状态运行。 2. K8S是一个开放的开发平台,它不局限于任何一种语言,没有限定任何编程接口,所以无论是JAVA,Go,Python还是C++编写的服务,都可以毫无困难地映射为Kubernetes的Service,并通过标准的TCP通信协议进行交互. 3. K8S是一个完备的分布式系统支撑平台,具有完备的集群管理能力,包括多层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和服务发现机制、内建智能负载均衡,强大的故障发现和自我修复能力、以及多粒度的资源配额管理能力。 1、故障迁移:当某一个node节点关机或挂掉后,node节点上的服务会自动转移到另一个node节点上,这个过程所有服务不中断。这是docker或普通云主机是不能做到的 2、资源调度:当node节点上的cpu、内存不够用的时候,可以扩充node节点,新建的pod就会被kube-schedule调度到新扩充的node节点上 3、资源隔离:创建开发、运维、测试三个命名空间,切换上下文后,开发人员就只能看到开发命名空间的所有pod,看不到运维命名空间的pod,这样就不会造成影响,互不干扰 传统的主机或只有docker环境中,登录进去就会看到所有的服务或者容器 4、因为采用docker容器,进程之间互不影响, 5、安全:不同角色有不同的权限,查看pod、删除pod等操作;RBAC认证增加了k8s的安全 6、快速精准地部署应用程序 7、限制硬件用量仅为所需资源 转载至:https://www.jianshu.com/p/0d1dbd24d635 1. k8s可以更快的更新新版本:打包应用,更新的时候可以做到不用中断服务,服务器故障不用停机,从开发环境到测试环境到生产环境的迁移极其方便,一个配置文件搞定,一次生成image,到处运行。。。 2. 一个平台搞定所有:使用K8S,部署任何应用都是小菜一碟,只要应用可以打包到容器,K8S就可以启动它。不管什么语言什么框架写的应用(Java, Python, Node.js),Kubernetes 都可以在任何环境中安全的启动它,物 理服务器、虚拟机、云环境。 3. 云环境无缝迁移: 如果你有换云的需求,例如从GCP到AWS,使用K8SD的话,你就不用有任何担心,K8S完全兼容各种云服务提供商,例如 Google Cloud、Amazon、Microsoft Azure,还可以工作在 CloudStack, OpenStack, OVirt, Photon, VSphere。 4. 高效的利用资源:Kubernetes 如果发现有节点工作不饱和,便会重新分配 pod,帮助我们节省开销,高效的利用内存、处理器等资源。如果一个节点宕机了,Kubernetes 会自动重新创建之前运行在此节点上的 pod,在其他节点上运行。如下图: 左边,是4个虚拟机,黄色和蓝色部分是运行的应用,白色部分是未使用的内存和处理器资源。 右边,同样的应用打包运行在容器中。 5. 开箱即用的自动缩放能力: 网络、负载均衡、复制等特性,对于 Kubernetes 都是开箱即用的。pod 是无状态运行的,任何时候有 pod 宕了,立马会有其他 pod 接替它的工作,用户完全感觉不到。如果用户量突然暴增,现有的 pod 规模不足了,那么会自动创建出一批新的 pod,以适应当前的需求。反之亦然,当负载降下来的时候,Kubernetes 也会自动缩减 pod 的数量。 7. 可靠性:Kubernetes 如此流行的一个重要原因是:应用会一直顺利运行,不会被 pod 或 节点的故障所中断。如果出现故障,Kubernetes 会创建必要数量的应用镜像,并分配到健康的 pod 或节点中,直到系统恢复。而且用户不会感到任何不适。一个容器化的基础设施是有自愈能力的,可以提供应用程序的不间断操作,即使一部分基础设施出现故障。 Kubernetes使用共享网络将多个物理机或虚拟机汇集到一个集群中,在各服务器之间进行通信,该集群是配置Kubernetes的所有组件、功能和工作负载的物理平台。集群中一台服务器(或高可用部署中的一组服务器)用作Master,负责管理整个集群,余下的其他机器用作Worker Node,它们是使用本地和外部资源接收和运行工作负载的服务器。集群中的这些主机可以是物理服务器,也可以是虚拟机(包括IaaS云端的VPS) Master指的是集群的控制节点,是集群的网关和中枢,负责诸如为用户和客户端暴露API、跟踪其它服务器的健康状态、以最优方式调度工作负载,以及编排其他组件之间的通信等任务,它是用户或客户端与集群之间的核心联络点,基本上K8S所有的控制命令都是发给它,它来复制具体的执行过程,并负责Kubernetes系统的大多数集中式管控逻辑。单个Master节点即可完成其所有的功能,但出于冗余及负载均衡等目的,生产环境中通常需要协同部署多个此类主机。Master节点类似于蜂群中的蜂王。如下图: Kubernetes的集群控制平面由多个组件组成,这些组件可统一运行于单一Master节点,也可以以多副本的方式同时运行于多个节点,以为Master提供高可用功能,甚至还可以运行于Kubernetes集群自身之上。Master主要包括以下几个组件。 Api Server负责输出RESTful风格的Kubernetes API,它是发往集群的所有REST操作命令的接入点,并负责接收、校验并响应所有的REST请求,结果状态被持久存储于etcd中。因此,API Server是整个集群的网关。 Kubernetes集群的所有状态信息都需要持久存储于存储系统etcd中,不过,etcd是由CoreOS基于Raft协议开发的分布式键值存储,可用于服务发现、共享配置以及一致性保障(例如数据库主节点选择、分布式锁等)。因此,etcd是独立的服务组件,并不隶属于Kubernetes集群自身。生产环境中应该以etcd集群的方式运行以确保其服务可用性。 etcd不仅能够提供键值数据存储,而且还为其提供了监听(watch)机制,用于监听和推送变更。Kubernetes集群系统中,etcd中的键值发生变化时会通知到API Server,并由其通过watch API向客户端输出。基于watch机制,Kubernetes集群的各组件实现了高效协同。 Kubernetes中,集群级别的大多数功能都是由几个被称为控制器的进程执行实现的,这几个进程被集成与kube-controller-manager守护进程中。由控制器完成的功能主要包括生命周期功能和API业务逻辑,具体如下 生命周期功能:包括Namespace创建和生命周期、Event垃圾回收、Pod终止相关的垃圾回收、级联垃圾回收及Node垃圾回收等。 API业务逻辑:例如,由ReplicaSet执行的Pod扩展等。 Kubernetes是用于部署和管理大规模容器应用的平台,根据集群规模的不同,其托管运行的容器很可能会数以千计甚至更多。API Server确认Pod对象的创建请求之后,便需要由Scheduler根据集群内各节点的可用资源状态,以及要运行的容器的资源需求做出调度决策,如下图所示。另外,Kubernetes还支持用户自定义调度器。 Node是Kubernetes集群的工作节点,负责接收来自Master的工作指令并根据指令相应的创建或删除Pod对象,以及调整网络规则以合理地路由和转发流量等。理论上讲,Node可以是任何形式的计算设备无论是物理机还是虚拟机,在K8S中Master会统一将其抽象为Node对象进行管理。Node类似于蜂群中的工蜂,生产环境中,它们通常数量众多。 Kubernetes将所有Node的资源集结于一处形成一台更强大的“服务器”,如下图,在用户将应用部署于其上时,Master会使用调度算法将其自动指派某个特定的Node运行,在Node加入集群或从集群中移除时,又或者当某个Node宕机时,Master也会按需重行编排影响到的Pod(容器)至新的Node里面。于是,用户无需关心其应用究竟运行于何处,不用担心某个Node宕机了,影响应用的运行,除非你只有一个Node节点,在生产环境这是不现实的。 从抽象的角度来讲,Kubernetes还有着众多的组件来支撑其内部的业务逻辑,包括运行应用、应用编排、服务暴露、应用恢复等,它们在Kubernetes中被抽象为Pod、Service、Controller等资源类型。 Node负责提供运行容器的各种依赖环境,并接收Master的管理。每个Node主要由以下几个组件构成。 kubelet是运行于工作节点之上的守护进程,它从API Server接收关于Pod对象的配置信息并确保它们处于期望的状态(desired state,也可以说目标状态)kubelet会在API Server上注册当前工作节点,定期向Master汇报节点资源使用情况,并通过cAdvisor监控容器和节点的资源占用情况。 每个工作节点都需要运行一个kube-proxy守护进程,它能够按需为Service资源对象生成iptables或ipvs规则,从而捕获访问当前Service的ClusterIP的流量并将其转发至正确的后端Pod对象。 docker用于运行容器 Kubernetes并不直接运行容器,而是使用一个抽象的资源对象来封装一个或者多个容器,这个抽象即为Pod,它是Kubernetes的最小调度单元。同一Pod中的容器共享网络名称空间和存储资源,这些容器可经由本地回环接口lo直接通信,但彼此之间又在Mount、User及PID等名称空间上保持了隔离。尽管Pod中可以包含多个容器,但是作为最小调度单元,它应该尽可能地保持“小”,即通常只应该包含一个主容器,以及必要的辅助型容器(Pause)。通常情况下一个Node可以有一个或多个Pod,这取决于业务的架构。 Selector即标签选择器,全名"Label Selector", 他是一种根据Label来过滤复合条件的资源对象的机制, 类似与CSS的标签选择器. 例如,将附有标签”role:backend“的所有Pod对象挑选出来归为一组就是标签选择器的一种应用,如下图所示,通常使用标签对资源对象进行分类,而后使用标签选择器挑选出它们,例如将其创建未某Service的端点。 尽管Pod是kubernetes的最小调度单元.生产中,很少会跑一个自主式pod,一般由控制器去创建pod,其配置文件中内嵌了pod的创建方式.——控制器(Controller)对其进行管理。用于工作负载的控制器是一种管理Pod生命周期的资源抽象,它们是kubernetes上的一类对象,而非单个资源对象,包括ReplicationController,ReplicaSet、Deployment、StatefulSet、Job等。已下图所示的Deployment控制器为例,它负责确保指定的Pod对象的副本数量精确符合定义,否则“多退少补”。使用控制器之后就不再需要手动管理Pod对象了,只需要声明应用的期望状态,控制器就会自动对其进行进程管理。 代用户创建指定数量的pod副本数量,确保pod副本数量符合预期状态,并且支持滚动式自动扩容和缩容功能. 组成: 工作在ReplicaSet之上,用于管理无状态应用,目前来说最好的控制器.支持滚动更新和回滚功能,还提供声明式配置; 用于确保集群中的每一个节点只运行特定的pod副本,通常用于实现系统级后台任务,比如ELK中负责收集日志filebeat,特性:服务是无状态的,服务必须是守护进程; 只要完成就立即退出,不需要重启或重建; 周期性任务控制,不需要持续后台运行; 管理有状态应用. Service是建立在一组Pod对象之上的资源抽象,它通过标签选择器选定一组Pod对象,并为这组Pod对象定义一个统一的固定访问入口(通常是一个IP地址),若Kubernetes集群存在DNS附件,它就会在Service创建时为其自动配置一个DNS名称以便客户端进行服务发现。到达Service IP的请求将被负载均衡至其后的端点——各个Pod对象之上,因此Service从本质上来讲是一个四层代理服务。另外,service还可以将集群外部流量引入到集群中来。 存储卷(Volume)是独立于容器文件系统之外的存储空间,常用于扩展容器的存储空间并为它提供持久存储能力。Kubernetes集群上的存储卷大体可以分为临时卷、本地卷和网络卷。临时卷和本地卷都位于Node本地,一旦Pod被调度至其他Node,此种类型的存储卷将无法访问到,因此临时卷和本地卷通常用于数据缓存,持久化的数据则需要放置于持久卷(persistent volume)之上。 名称(Name)是Kubernetes集群中资源对象的标识符,它们的作用域通常是名称空间(Namespace),因此名称空间是名称的额外的限定机制。在同一名称空间中,同一类型资源对象的名称必须具有唯一性。名称空间通常用于实现租户或项目的资源隔离,从而形成逻辑分组,如下图所示,创建的Pod和Service等资源对象都属于名称空间级别,未指定时,他们都属于默认的名称空间“default”。 Annotation(注释)是另一种附加在对象之上的键值类型的数据,但它拥有更大的数据容量。Annotation常用于将各种非标识型元数据(metadata)附加到对象上,但它不能用于标识和选择对象,通常也不会被Kubernetes直接使用,其主要目的是方便工具或用户的阅读和查找等。 Kubernetes将Pod对象和外部网络环境进行了隔离,Pod和Service等对象间的通信都使用其内部专用地址进行,如若需要开放某些Pod对象提供给外部用户访问,则需要为其请求流量打开一个通往Kubernetes集群内部的通道,除了Service之外,Ingress也是这类通道的实现方式之一。 是kubernetes(以下简称k8s)的一种资源对象,能够根据某些指标对在statefulSet、replicaController、replicaSet等集合中的pod数量进行动态伸缩,使运行在上面的服务对指标的变化有一定的自适应能力。 HPA目前支持四种类型的指标,分别是Resource、Object、External、Pods。其中在稳定版本autoscaling/v1中只支持对CPU指标的动态伸缩,在测试版本autoscaling/v2beta2中支持memory和自定义指标的动态伸缩,并以annotation的方式工作在autoscaling/v1版本中。 Kubernetes集群还依赖于一组称为"附件"(add-ons)的组件以提供完整的功能,它们通常是由第三方提供的特定应用程序,且托管运行于Kubernetes集群之上,如上图所示。 在Kubernetes集群中调度运行提供DNS服务的Pod,同一集群中的其他pod可使用此DNS服务解决主机名。Kubernetes从1.11版本开始默认使用CoreDNS项目为集群提供服务注册和服务发现的动态名称解析服务,之前的版本中用到的是kube-dns项目,而SKyDNS则是更早一代的项目。 Kubernetes集群的全部功能都要基于Web的UI,来管理集群中应用甚至是集群自身。 容器和节点的性能监控与分析系统,它收集并解析多种指标数据,如资源利用率、生命周期事件等。新版本的Kubernetes中,其功能会逐渐由Prometheus结合其他组件所取代。 Service是一种工作于传输层的负载均衡器,而Ingress是在应用层实现的HTTP(s)负载均衡机制。不过,Ingress资源自身不能进行“流量穿透”,它仅是一组路由规则的集合,这些规则需要通过Ingress控制器(Ingress Controller)发挥作用。目前,此类的可用项目有Nginx、Traefik、Envoy及HAProxy等。 Kubernetes (一)K8S入门 标签:新版 管控 master label 辅助 lse 响应 spl 扩容 原文地址:https://www.cnblogs.com/tashanzhishi/p/13527751.htmlKubernetes是什么
Kubernetes的初识
例如:比如用户想让apache一直运行,用户不需要关心怎么去做,Kubernetes会自动去监控,然后去重启,新建,总之,让apache一直提供服务.Kubernetes的特点
为什么要用Kubernetes

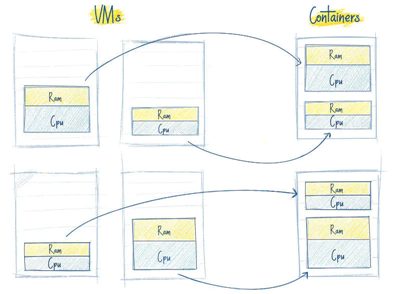
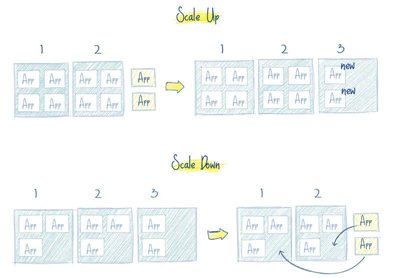
6. 使用CI/CD更加简单:你不必精通于 Chef 和 Ansible 这类工具,只需要对 CI 服务写个简单的脚本然后运行它,就会使用你的代码创建一个新的 pod,并部署到 Kubernetes 集群里面。应用打包在容器中使其可以安全的运行在任何地方,例如你的 PC、一个云服务器,使得测试极其简单。
总之:Kubernetes 使得应用的启动、迁移、部署变得即简单又安全。不必担心应用迁移后工作出现问题,也不用担心一台服务器无法应付突发的用户量。需要注意的是,你的应用最好使用微服务架构进行开发,因为微服务应用比单体应用更适合做容器化。Kubernetes的基本概念和术语
Master
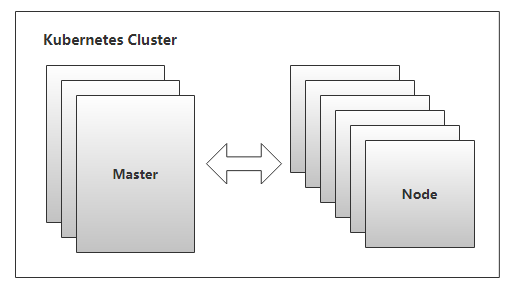
API Server
ETCD
Controller Manager
Scheduler
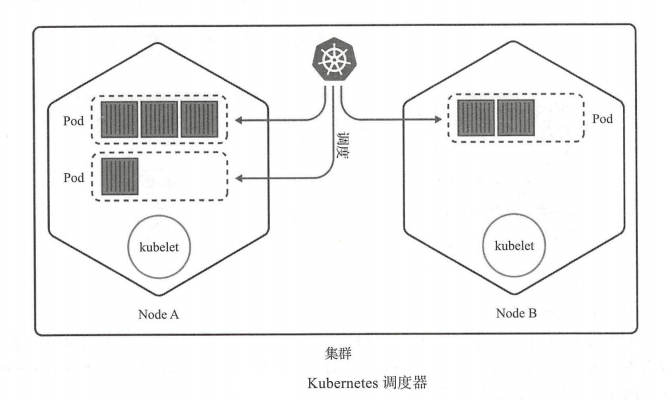
Node
kubelet
kube-proxy
docker
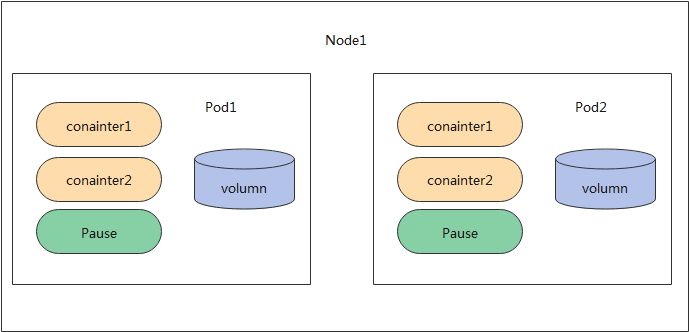
Pod
Label
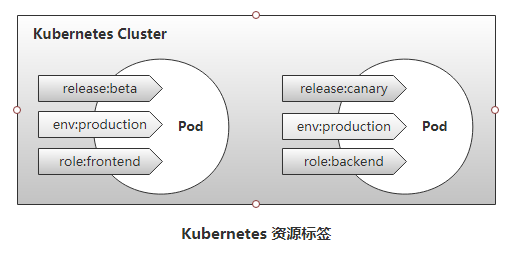
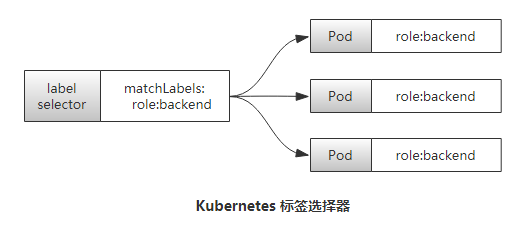
Selector
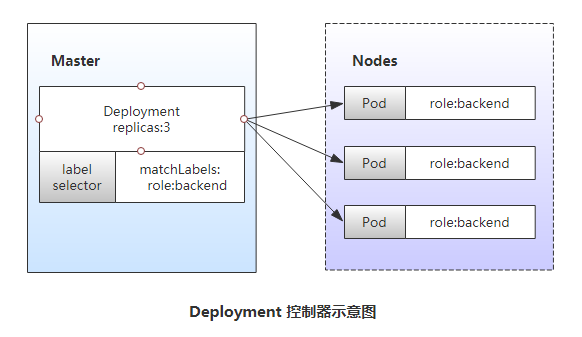
Pod控制器
ReplicaSet
a.用户期望的pod副本数量;b.标签选择器,判断哪个pod归自己管理;c.pod资源模板,当现存的pod数量不足,会根据pod资源模板进行新建.Deployment
DaemonSet
Job
Cronjob
StatefulSet
Serveice(服务)
Volume(存储卷)
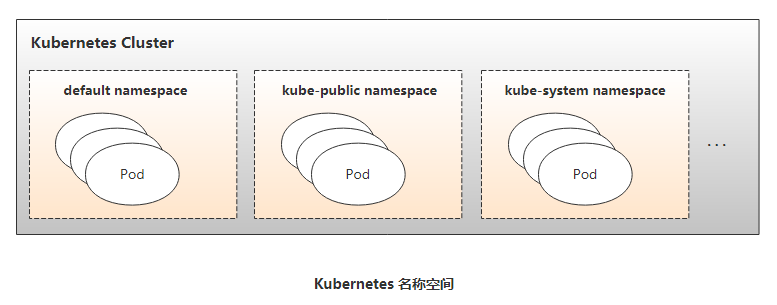
Name和Namespace
Annotation
Ingress
Horizontal Pod Autoscaler(HPA)
K8S核心附件
KubeDNS
Kubernetes Dashboard
Heapster
Ingress Controller
上一篇:Vue.js框架:基本用法(一)