kubernetes(八) kubernetes的使用
2021-01-22 04:14
标签:场景 busybox manifest lin scribe 指定 dea sch targe 参考命令: 1、[preflight] 检查环境是否满足条件 官方文档:https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/ Pod和Container的资源请求和限制: 没有涉及到控制器,所以就没有涉及到kube-controller-manager schedulerName: default-secheduler nodeAffinity:节点亲和类似于nodeSelector,可以根据节点上的标签来约束Pod可以调度到哪些节点。 Taints:避免Pod调度到特定Node上 kubectl taint node [node] key=value:effect 其中effect可取值: ? NoSchedule :一定不能被调度。 ? PreferNoSchedule:尽量不要调度。 ? NoExecute:不仅不会调度,还会驱逐Node上已有的Pod。 kubernetes(八) kubernetes的使用 标签:场景 busybox manifest lin scribe 指定 dea sch targe 原文地址:https://blog.51cto.com/13812615/2510166kubectl命令行管理工具
kubectl常用的命令行管理命令
kubectl create deployment web --image=nginx:1.14
kubectl get deploy,pods
kubectl expose deployment web --port=80 --type=NodePort --targer-port=80 --name=web
kubectl get service
kubectl set image deployment/web nginx=nginx:1.16
kubectl rollout status deployment/web
kubectl rollout undo deployment/web #回滚到上一个版本
kubectl rollout history deploy/web #查看版本(版本号递增,最新的也就是版本号最大的)
kubectl rollout undo deploy/web --to-revision=1 #指定版本回滚
kubectl scale deployment web --replicas=4 #扩容至4个pod
kubectl scale deployment web --replicas=1 #缩容至1个pod资源编排
kubeadm init工作:
2、[kubelet-start] 启动kubelet
3、[certs] /etc/kubernetes/pki 生成apiserver和etcd两套证书
4、[kubeconfig] 连接apiserver的配置文件
5、[control-plane] 静态Pod /etc/kubernetes/manifests
6、[etcd] 静态pod启动etcd
7、[upload-config] 将kubeadm配置存放到kube-system configmap
8、[kubelet] 将kkubelet配置存放到kube-system configmap
9、[mark-control-plane] node-role.kubernetes.io/master=‘‘ 说明master节点不调度pod
10、[bootstrap-token] 为kubelet自动颁发证书机制
11、安装插件 CoreDNS kube-proxyk8s组成回顾
yaml文件格式说明
# dry-run获取
kubectl create deployment nginx --image=nginx:1.14 -o yaml --dry-run=client > my-deploy.yml
# 命令行导出
kubectl get deploy/web -o yaml --export > my-deploy.yml
# 忘记字段
kubectl explain pod.spec深入理解POD资源对象
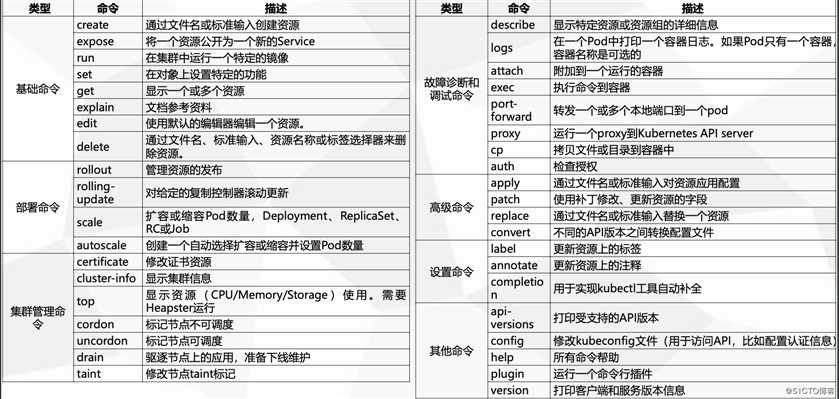
kubectl的命令可分为三类
POD基本概念
创建pod的方式
pod存在的意义
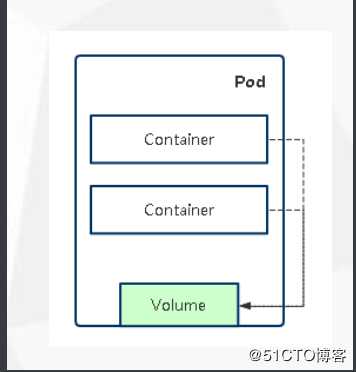
pod实现机制与设计模式
$ vim demo1.yml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
namespace: prod
spec:
containers:
- name: write
image: centos:7
command: ["bash","-c","for i in {1..100};do echo $i >> /data/hello;sleep 1;done"]
volumeMounts:
- name: data
mountPath: /data
- name: read
image: centos:7
command: ["bash","-c","tail -f /data/hello"]
volumeMounts:
- name: data
mountPath: /data
volumes:
- name: data
emptyDir: {}
$ kubectl create ns prod
$ kubectl apply -f demo1.yml
$ kubectl get pod -n prod
$ kubectl exec -it my-pod -n prod bash镜像拉取策略
$ vim demo2.yml
apiVersion: v1
kind: Pod
metadata:
name: foo
namespace: prod
spec:
containers:
- name: foo
image: janedoe/awesomeapp:v1
imagePullPolicy: IfNotPresent
$ kubectl apply -f demo2.yml
$ kubectl describe pod foo -n prod
$ kubectl get pod foo -n prod资源限制
? spec.containers[].resources.limits.cpu
? spec.containers[].resources.limits.memory
? spec.containers[].resources.requests.cpu
? spec.containers[].resources.requests.memory
$ vim demo3.yml
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: db
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "password"
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: wp
image: wordpress
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
$ kubectl apply -f demo3.yml重启策略
kubectl explain pod.spec.restartPolicy
$ vim demo4.yml
apiVersion: v1
kind: Pod
metadata:
name: demo
namespace: prod
spec:
containers:
- name: demo1
image: janedoe/awesomeapp:v1
restartPolicy: Always
$ kubectl get pod -n prod -w #查看重启状态健康检查(probe)
$ vim pod_healthy.yml
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: healthy-check
namespace: prod
spec:
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy;sleep 30;rm -fr /tmp/healthy;sleep 60
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5资源调度
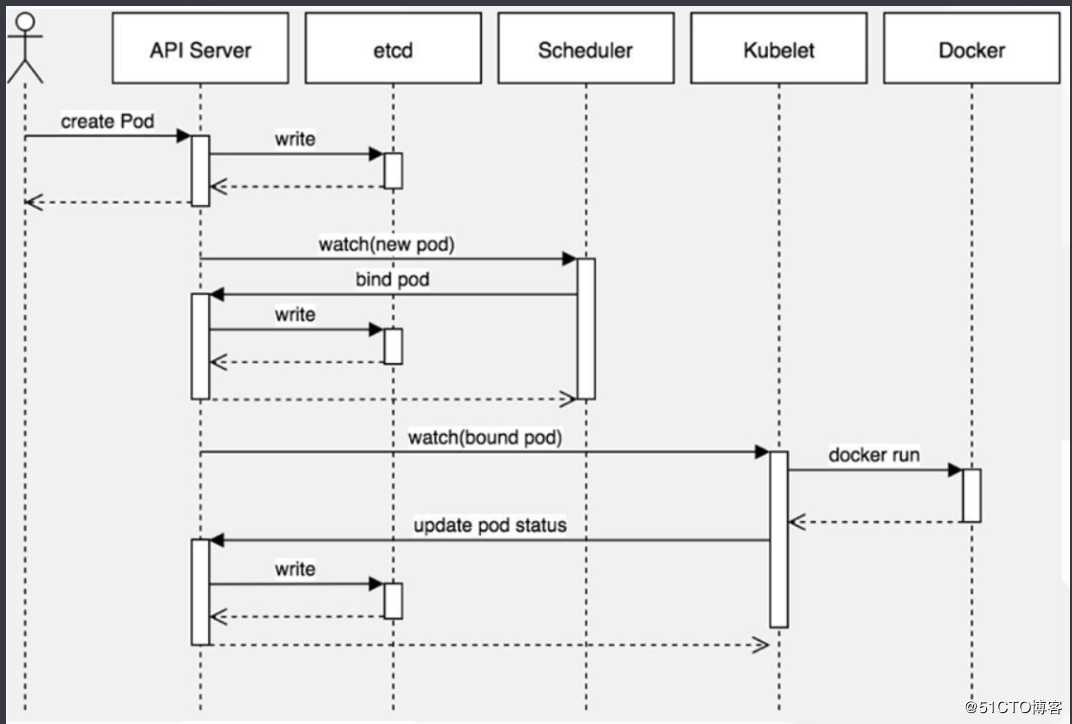
调度策略-影响Pod调度的重要属性
nodeName: "k8s-node1"
nodeSelector: {}
affinity: {}
tolerations: {}$ vim pod_sheduler.yml
apiVersion: v1
kind: Pod
metadata:
name: web
namespace: prod
spec:
containers:
- name: java-demo
image: lizhenliang/java-demo
imagePullPolicy: IfNotPresent
livenessProbe:
initialDelaySeconds: 30
periodSeconds: 20
tcpSocket:
port: 8080
resources: {}
restartPolicy: Always
schedulerName: default-secheduler
nodeName: "k8s-node1"
nodeSelector: {}
affinity: {}
tolerations: {}
$ kubectl apply -f pod_sheduler.yml
$ kubectl get pod -n prod -o wide #可以发现pod被调度到k8s-node1资源限制对Pod调度的影响
$ vim pod_schedule_resource.yml
apiVersion: v1
kind: Pod
metadata:
name: mysql
namespace: prod
spec:
containers:
- name: mysql
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
resources:
requests:
cpu: "250m"
memory: "64Mi"
limits:
cpu: "500m"
memory: "128Mi"
$ kubectl apply -f pod_schedule_resource.ymlnodeSelector & nodeAffinity
# 给节点打标签
$ kubectl label nodes k8s-node2 disktype=ssd
# 让pod调度到ssd节点
$ vim pod_ssd.yml
apiVersion: v1
kind: Pod
metadata:
name: pod-example
namespace: prod
spec:
nodeSelector:
disktype: ssd
containers:
- name: nginx
image: nginx:1.14-alpine
$ kubectl apply -f pod_ssd.yml
$ kubectl get pod -n prod -o wide #pod被调度到k8s-node2
$ vim pod_affinity.yml
apiVersion: v1
kind: Pod
metadata:
name: node-affinity
namespace: prod
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: gpu
operator: In
values:
- nvida-telsla
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: group
operator: In
values:
- ai
containers:
- name: web
image: nginx:1.14-alpine
$ kubectl apply -f pod_affinity.yml
taint(污点)
# 节点污点的设置
$ kubectl taint node k8s-master item-names=aard:NoSchedule
# 查看node污点
$ kubectl describe node k8s-master
#去掉污点
$kubectl taint node k8s-master item-name:NoSchedule-污点容忍
# 首先选一个节点设置污点
$ kubectl taint node k8s-node2 DiskType=nossd:NoSchedule
$ vim pod_tolerate.yml
apiVersion: v1
kind: Pod
metadata:
name: tolerate
namespace: prod
spec:
containers:
- name: pod-taint
image: busybox:latest
tolerations:
- key: "DiskType"
operator: "Equal"
value: "nossd"
effect: "NoSchedule"
schedulerName: default-secheduler
nodeName: "k8s-node2"
$ kubectl apply -f pod_tolerate.yml
$ kubectl get pod -n prod -o wide #发现会被调度到k8s-node2故障排查
kubectl describe TYPE/NAME
kubectl logs TYPE/NAME [-c CONTAINER]
kubectl exec POD [-c CONTAINER] -- COMMAND [args...]
上一篇:WEB面试
下一篇:PHP中使用redis哨兵