Python爬虫丨大众点评数据爬虫教程(2)
2021-01-28 04:14
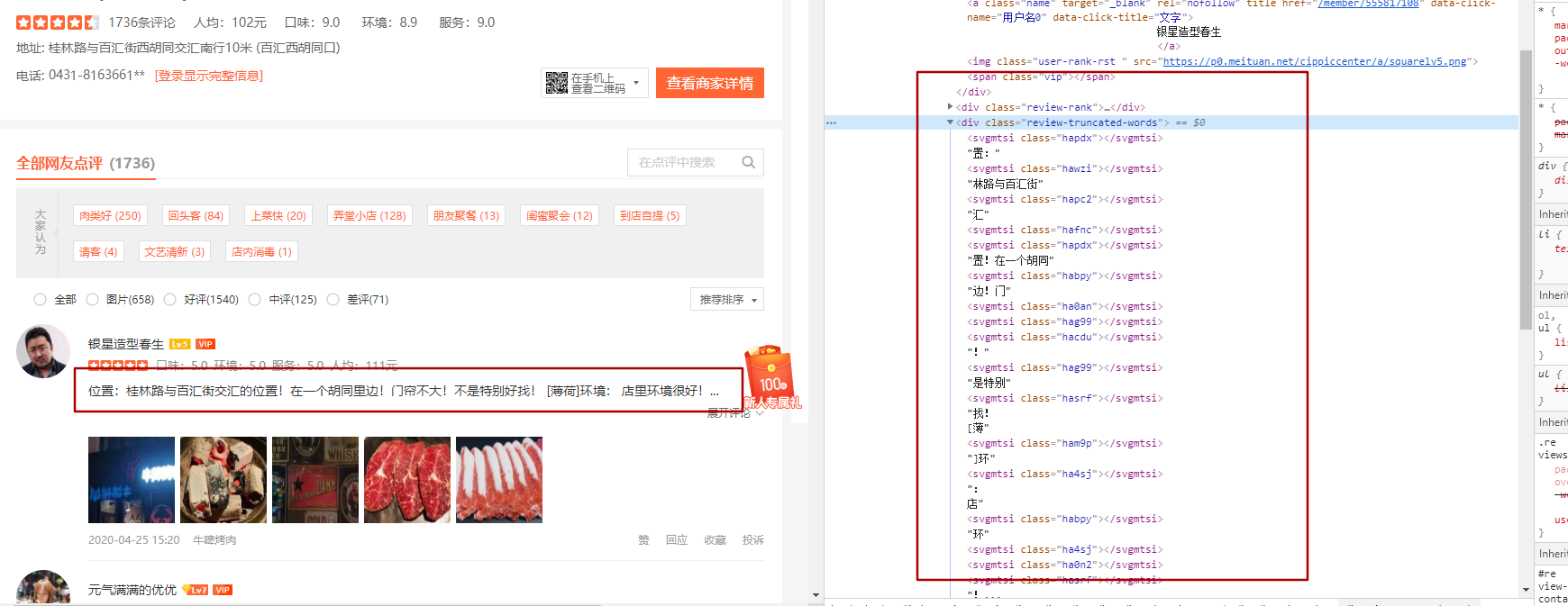
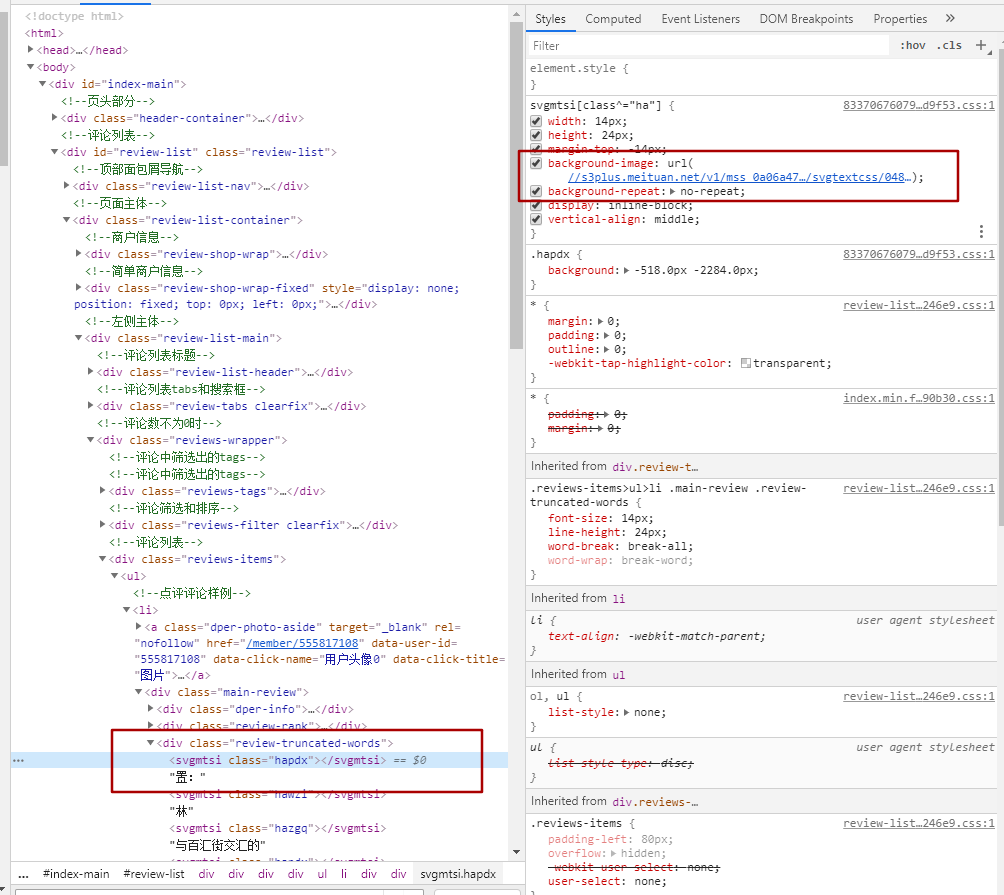
标签:数据 trunc font ide 一个 sel 修改 sorted length 前言: 大众点评是一款非常受大众喜爱的一个第三方的美食相关的点评网站。从网站内可以推荐吃喝玩乐优惠信息,提供美食餐厅、酒店旅游、电影票、家居装修、美容美发、运动健身等各类生活服务,通过海量真实消费评论的聚合,帮助大家选到服务满意商家。 因此,该网站的数据也就非常有价值。优惠,评价数量,好评度等数据也就非常受数据公司的欢迎。 接上文,本篇是SVG映射版本 希望对看到这篇文章的朋友有所帮助。 下面就让我看开启探索之旅 这次我们以“http://www.dianping.com/shop/16790071/review_all”为例子。 既然读者能看到这个,那么就一定自己有过一定了解了。 从图中的红框对比,可以看到左右内容的对比。可见并不是看到的结果就是页面返回的结果。 也就是这个链接:“https://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/048cf3c5718ff9fca0a56e2d9cf019fe.svg” 打开这个链接后看到的是如下的内容: 请注意上面的对比图,右侧的洪宽下的。hapdx属性,这个属性就是对应知道svg文字位置的背景图。可以自己动手修改参数值,相对应的位置就变了。 因此我们只需要做三步走。 一。找到对应页面的css路径,加载解析内容。处理。 二。替换页面内容,将需要替换的文字从通过属性,找到在css中对应的位置。 三。解析页面,获取对应的页面的值。 代码如下: 运行结果对比图如下: 具体的流程就是代码中显示的,细节还需要完善,但内容相对应的都是可以展示出来了。 本次两篇大众点评的采集教程到这里就结束了,详细交流欢迎与我联系。 本文章旨在用于交流分享,【未经允许,谢绝转载】 Python爬虫丨大众点评数据爬虫教程(2) 标签:数据 trunc font ide 一个 sel 修改 sorted length 原文地址:https://blog.51cto.com/14662342/2492695


import re
import requests
def svg_parser(url):
r = requests.get(url, headers=headers)
font = re.findall(‘" y="(\d+)">(\w+)‘, r.text, re.M)
if not font:
font = []
z = re.findall(‘" textLength.*?(\w+)‘, r.text, re.M)
y = re.findall(‘id="\d+" d="\w+\s(\d+)\s\w+"‘, r.text, re.M)
for a, b in zip(y, z):
font.append((a, b))
width = re.findall("font-size:(\d+)px", r.text)[0]
new_font = []
for i in font:
new_font.append((int(i[0]), i[1]))
return new_font, int(width)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36",
"Cookie": "_lxsdk_cuid=171c55eb43ac8-07f006bde8dc41-5313f6f-1fa400-171c55eb43ac8; _lxsdk=171c55eb43ac8-07f006bde8dc41-5313f6f-1fa400-171c55eb43ac8; _hc.v=970ed851-cbab-8871-10cf-06251d4e64a0.1588154251; t_lxid=17186f9fa02c8-02b79fa94db2c8-5313f6f-1fa400-17186f9fa03c8-tid; _lxsdk_s=171c55ea204-971-8a9-eae%7C%7C368"}
r = requests.get("http://www.dianping.com/shop/73408241/review_all", headers=headers)
print(r.status_code)
# print(r.text)
css_url = "http:" + re.findall(‘href="http://www.soscw.com/(//s3plus.meituan.net.*?svgtextcss.*?.css)‘, r.text)[0]
print(css_url)
css_cont = requests.get(css_url, headers=headers)
print(css_cont.text)
svg_url = re.findall(‘class\^="(\w+)".*?(//s3plus.*?\.svg)‘, css_cont.text)
print(svg_url)
s_parser = []
for c, u in svg_url:
f, w = svg_parser("http:" + u)
s_parser.append({"code": c, "font": f, "fw": w})
print(s_parser)
css_list = re.findall(‘(\w+){background:.*?(\d+).*?px.*?(\d+).*?px;‘, ‘\n‘.join(css_cont.text.split(‘}‘)))
css_list = [(i[0], int(i[1]), int(i[2])) for i in css_list]
def font_parser(ft):
for i in s_parser:
if i["code"] in ft[0]:
font = sorted(i["font"])
if ft[2] = int(font[j][0]) and ft[2] ‘, rep)[0]
rep = rep.replace(a, replace_dic[i]["word"])
except Exception as e:
print(e)
# print(rep)
from parsel import Selector
response = Selector(text=rep)
li_list = response.xpath(‘//div[@class="reviews-items"]/ul/li‘)
for li in li_list:
infof = li.xpath(‘.//div[@class="review-truncated-words"]/text()‘).extract()
print(infof[0].strip().replace("\n",""))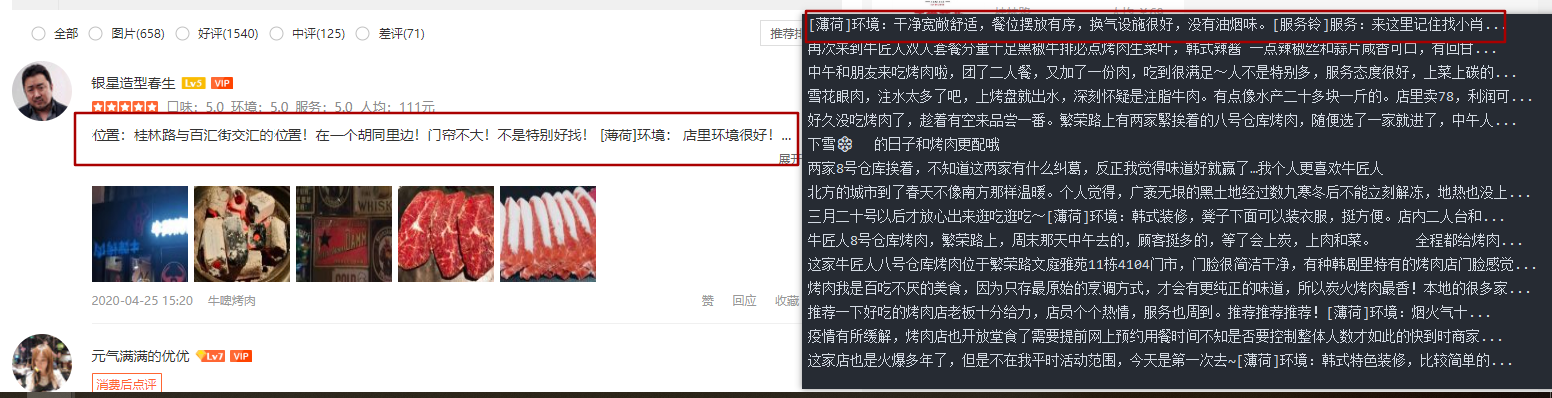
上一篇:SpringIOC
下一篇:python 练习题(三)