机器学习算法GBDT的面试要点总结-上篇
2021-02-02 01:15
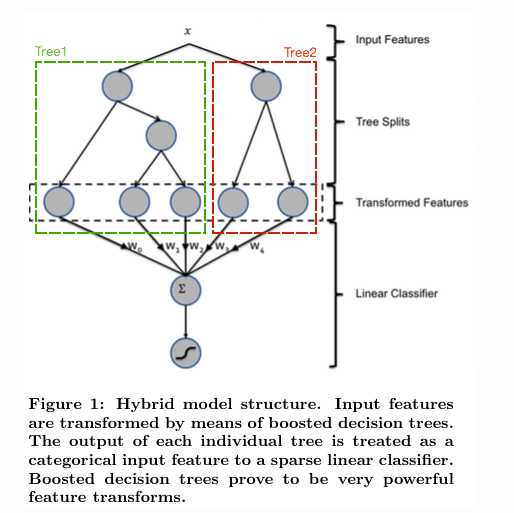
标签:如何 工业 原因 span mic tom append nbsp 回归 1.简介 gbdt全称梯度提升决策树,在传统机器学习算法里面是对真实分布拟合的最好的几种算法之一,在前几年深度学习还没有大行其道之前,gbdt在各种竞赛是大放异彩。原因大概有几个,一是效果确实挺不错。二是即可以用于分类也可以用于回归。三是可以筛选特征。这三点实在是太吸引人了,导致在面试的时候大家也非常喜欢问这个算法。 gbdt的面试考核点,大致有下面几个: 2. 正式介绍 首先gbdt 是通过采用加法模型(即基函数的线性组合),以及不断减小训练过程产生的残差来达到将数据分类或者回归的算法。 我们通过一张图片,图片来源来说明gbdt的训练过程: 图 1:GBDT 的训练过程 gbdt通过多轮迭代,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练。对弱分类器的要求一般是足够简单,并且是低方差和高偏差的。因为训练的过程是通过降低偏差来不断提高最终分类器的精度,(此处是可以证明的)。 弱分类器一般会选择为CART TREE(也就是分类回归树)。由于上述高偏差和简单的要求 每个分类回归树的深度不会很深。最终的总分类器 是将每轮训练得到的弱分类器加权求和得到的(也就是加法模型)。 模型最终可以描述为: 模型一共训练M轮,每轮产生一个弱分类器 T(x;θm)T(x;θm)。弱分类器的损失函数 Fm−1(x)Fm−1(x) 为当前的模型,gbdt 通过经验风险极小化来确定下一个弱分类器的参数。具体到损失函数本身的选择也就是L的选择,有平方损失函数,0-1损失函数,对数损失函数等等。如果我们选择平方损失函数,那么这个差值其实就是我们平常所说的残差。 gbdt选择特征的细节其实是想问你CART Tree生成的过程。这里有一个前提,gbdt的弱分类器默认选择的是CART TREE。其实也可以选择其他弱分类器的,选择的前提是低方差和高偏差。框架服从boosting 框架即可。 下面我们具体来说CART TREE(是一种二叉树) 如何生成。CART TREE 生成的过程其实就是一个选择特征的过程。假设我们目前总共有 M 个特征。第一步我们需要从中选择出一个特征 j,做为二叉树的第一个节点。然后对特征 j 的值选择一个切分点 m. 一个 样本的特征j的值 如果小于m,则分为一类,如果大于m,则分为另外一类。如此便构建了CART 树的一个节点。其他节点的生成过程和这个是一样的。现在的问题是在每轮迭代的时候,如何选择这个特征 j,以及如何选择特征 j 的切分点 m: 其实说gbdt 能够构建特征并非很准确,gbdt 本身是不能产生特征的,但是我们可以利用gbdt去产生特征的组合。在CTR预估中,工业界一般会采用逻辑回归去进行处理,在我的上一篇博文当中已经说过,逻辑回归本身是适合处理线性可分的数据,如果我们想让逻辑回归处理非线性的数据,其中一种方式便是组合不同特征,增强逻辑回归对非线性分布的拟合能力。 长久以来,我们都是通过人工的先验知识或者实验来获得有效的组合特征,但是很多时候,使用人工经验知识来组合特征过于耗费人力,造成了机器学习当中一个很奇特的现象:有多少人工就有多少智能。关键是这样通过人工去组合特征并不一定能够提升模型的效果。所以我们的从业者或者学界一直都有一个趋势便是通过算法自动,高效的寻找到有效的特征组合。Facebook 在2014年 发表的一篇论文便是这种尝试下的产物,利用gbdt去产生有效的特征组合,以便用于逻辑回归的训练,提升模型最终的效果。 图 2:用GBDT 构造特征 如图 2所示,我们 使用 GBDT 生成了两棵树,两颗树一共有五个叶子节点。我们将样本 X 输入到两颗树当中去,样本X 落在了第一棵树的第二个叶子节点,第二颗树的第一个叶子节点,于是我们便可以依次构建一个五纬的特征向量,每一个纬度代表了一个叶子节点,样本落在这个叶子节点上面的话那么值为1,没有落在该叶子节点的话,那么值为 0. 于是对于该样本,我们可以得到一个向量[0,1,0,1,0] 作为该样本的组合特征,和原来的特征一起输入到逻辑回归当中进行训练。实验证明这样会得到比较显著的效果提升。 首先明确一点,gbdt 无论用于分类还是回归一直都是使用的CART 回归树。不会因为我们所选择的任务是分类任务就选用分类树,这里面的核心是因为gbdt 每轮的训练是在上一轮的训练的残差基础之上进行训练的。这里的残差就是当前模型的负梯度值 。这个要求每轮迭代的时候,弱分类器的输出的结果相减是有意义的。残差相减是有意义的。 如果选用的弱分类器是分类树,类别相减是没有意义的。上一轮输出的是样本 x 属于 A类,本一轮训练输出的是样本 x 属于 B类。 A 和 B 很多时候甚至都没有比较的意义,A 类- B类是没有意义的。 我们具体到分类这个任务上面来,我们假设样本 X 总共有 K类。来了一个样本 x,我们需要使用gbdt来判断 x 属于样本的哪一类。 图三 gbdt 多分类算法流程 第一步 我们在训练的时候,是针对样本 X 每个可能的类都训练一个分类回归树。举例说明,目前样本有三类,也就是 K = 3。样本 x 属于 第二类。那么针对该样本 x 的分类结果,其实我们可以用一个 三维向量 [0,1,0] 来表示。0表示样本不属于该类,1表示样本属于该类。由于样本已经属于第二类了,所以第二类对应的向量维度为1,其他位置为0。 针对样本有 三类的情况,我们实质上是在每轮的训练的时候是同时训练三颗树。第一颗树针对样本x的第一类,输入为(x,0)(x,0)。第二颗树输入针对 样本x 的第二类,输入为(x,1)(x,1)。第三颗树针对样本x 的第三类,输入为(x,0)(x,0) 在这里每颗树的训练过程其实就是就是我们之前已经提到过的CATR TREE 的生成过程。在此处我们参照之前的生成树的程序 即可以就解出三颗树,以及三颗树对x 类别的预测值f1(x),f2(x),f3(x)f1(x),f2(x),f3(x)。那么在此类训练中,我们仿照多分类的逻辑回归 ,使用softmax 来产生概率,则属于类别 1 的概率 并且我们我们可以针对类别1 求出 残差y11(x)=0−p1(x)y11(x)=0−p1(x);类别2 求出残差y22(x)=1−p2(x)y22(x)=1−p2(x);类别3 求出残差y33(x)=0−p3(x)y33(x)=0−p3(x). 然后开始第二轮训练 针对第一类 输入为(x,y11(x)y11(x)), 针对第二类输入为(x,y22(x))y22(x)), 针对 第三类输入为 (x,y33(x)y33(x)).继续训练出三颗树。一直迭代M轮。每轮构建 3颗树。 所以当K =3。我们其实应该有三个式子 当训练完毕以后,新来一个样本 x1 ,我们需要预测该样本的类别的时候,便可以有这三个式子产生三个值,f1(x),f2(x),f3(x)f1(x),f2(x),f3(x)。样本属于 某个类别c的概率为

1 def findLossAndSplit(x,y):
2 # 我们用 x 来表示训练数据
3 # 我们用 y 来表示训练数据的label
4 # x[i]表示训练数据的第i个特征
5 # x_i 表示第i个训练样本
6
7 # minLoss 表示最小的损失
8 minLoss = Integet.max_value
9 # feature 表示是训练的数据第几纬度的特征
10 feature = 0
11 # split 表示切分点的个数
12 split = 0
13
14 # M 表示 样本x的特征个数
15 for j in range(0,M):
16 # 该维特征下,特征值的每个切分点,这里具体的切分方式可以自己定义
17 for c in range(0,x[j]):
18 L = 0
19 # 第一类
20 R1 = {x|x[j] c}
23 # 属于第一类样本的y值的平均值
24 y1 = ave{y|x 属于 R1}
25 # 属于第二类样本的y值的平均值
26 y2 = ave{y| x 属于 R2}
27 # 遍历所有的样本,找到 loss funtion 的值
28 for x_1 in all x
29 if x_1 属于 R1:
30 L += (y_1 - y1)^2
31 else:
32 L += (y_1 - y2)^2
33 if L
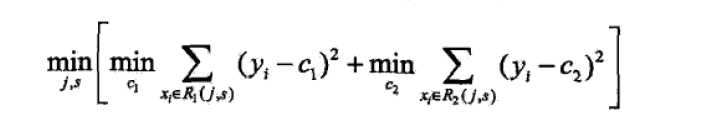

上一篇:Python语言开发工具选择
下一篇:tensorflow.python.framework.errors_impl.UnknownError: Failed to get convolution algorithm. This is p