JAVA对象生命周期(三)-对象的销毁
2021-02-03 01:14
标签:处理 老年 压缩 top 本地 目标 toc rom 基础 reference变量中直接存储的就是对象的地址,而java堆对象一部分存储了对象实例数据,另外一部分存储了对象类型数据。 java堆中将划分出一块内存来作为句柄池,reference中存储的就是对象的句柄地址,而句柄中包含了对象实例数据和类型数据各自的具体地址信息。 这两种访问对象的方式各有优势,使用句柄访问方式最大好处就是reference中存储的是稳定的句柄地址,在对象移动时只需要改变句柄中的实例数据指针,而reference不需要改变。使用指针访问方式最大好处就是速度快,它节省了一次指针定位的时间开销,就虚拟机而言,它使用的是第二种方式(直接指针访问) 堆中放着几乎所有的对象实例,回收前第一步就要判断对象是否死亡 给对象增加一个引用计数器,每当有一个地方引用他,计数器就加1:当引用失效后,计数器就减1.任何时候计数器为0的对象就是可回收对象。 通过一系列称为“GC Roots”的对象作为七点,从这些节点开始向下搜索,节点所走过的路径称为引用链,当一个对象到GCRoots没有任何引用链相链时,则证明此对象是不可用的。 最基础的收集算法是“标记-清除”(Mark-Sweep)算法,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。 将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。 这样使得每次都是对整个半区进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。 当回收时,将Eden和Survivor中还存活着的对象一次性地复制到另外一块Survivor空间上,最后清理掉Eden和刚才用过的Survivor空间。 HotSpot虚拟机默认Eden和Survivor的大小比例是8:1,也就是每次新生代中可用内存空间为整个新生代容量的90%(80%+10%),只有10%的内存会被“浪费”。 98%的对象可回收只是一般场景下的数据,没有办法保证每次回收都只有不多于10%的对象存活,当Survivor空间不够用时,需要依赖其他内存(这里指老年代)进行分配担保(Handle Promotion) 用于设置年轻代的大小,建议设为整个堆大小的1/3或者1/4,两个值设为一样大。 用于设置Eden和其中一个Survivor的比值,这个值也比较重要。 这个参数用于显示每次Minor GC时Survivor区中各个年龄段的对象的大小。 用于设置晋升到老年代的对象年龄的最小值和最大值,每个对象在坚持过一次Minor GC之后,年龄就加1。 复制收集算法在对象存活率较高时就要进行较多的复制操作,效率将会变低。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选用这种算法。 上面在讲复制算法优化的时候也提到了年轻代使用的垃圾收集算法。 G1是目前技术发展的最前沿成果之一,HotSpot开发团队赋予它的使命是未来可以替换掉JDK1.5中发布的CMS收集器。与CMS收集器相比G1收集器有以下特点: 垃圾收集的核心还是从“标记-清理”算法基础上的各种优化版本,每一种算法的都是从时间和空间两个角度出发来达到最高效率,请根据个人应用特性来选择最适合的垃圾收集器,好啦本文就说这么多,希望大家多思考多练习,欢迎留言讨论。 https://blog.csdn.net/high2011/article/details/80177473 JAVA对象生命周期(三)-对象的销毁 标签:处理 老年 压缩 top 本地 目标 toc rom 基础 原文地址:https://www.cnblogs.com/jimoliunian/p/12806537.html
从引用说起
Object object = new Object();
指向对象的引用地址,并没有定义这个引用应该通过那种方式去定位,访问到java堆中的对象位置,因此不同的虚拟机实现的访问方式可能不同,主流的方式有两种:使用句柄和直接指针。指针直接引用
句柄引用
优缺点
如何判断对象死亡
引用计数法
/**
* testGC()方法执行后会不会被GC? 不会!!!!
*
* @author TongWei.Chen 2017-09-05 11:15:53
*/
public class ReferenceCountingGC {
public Object instance = null;
public static void testGC() {
//step 1
ReferenceCountingGC objA = new ReferenceCountingGC();
//step 2
ReferenceCountingGC objB = new ReferenceCountingGC();
//相互引用
//step 3
objA.instance = objB;
//step 4
objB.instance = objA;
//step 5
objA = null;
//step 6
objB = null;
//假设在这行发生CG,objA和objB是否能被回收? 不能!!!!
System.gc();
}
public static void main(String[] args) {
testGC();
}
}
可达性分析法
可以作为GC Roots的对象包括以下几点
1、虚拟机栈(栈帧中的本地变量表)中引用的对象。
2、方法区中的类静态属性引用的对象或者常量引用的对象。
3、本地方法栈中JNI(就是native方法)引用的对象。
垃圾收集算法
标记-清除算法
标记-清除算法是最基础的收集算法,其他的收集算法都是基于这种思路并对其不足进行改进而得到的。
复制算法
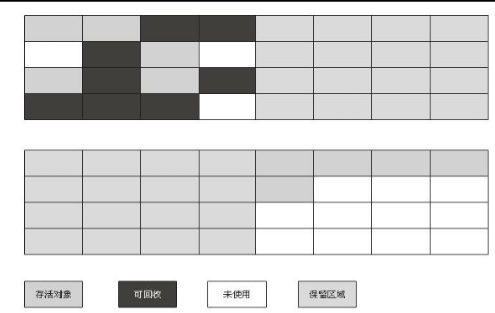
复制算法——优化
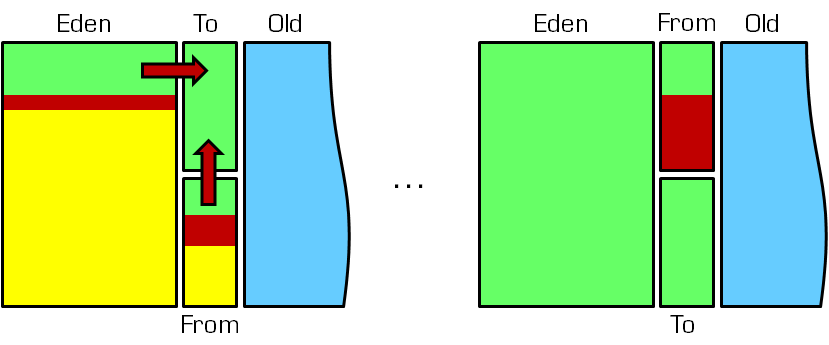
有关年轻代的JVM参数
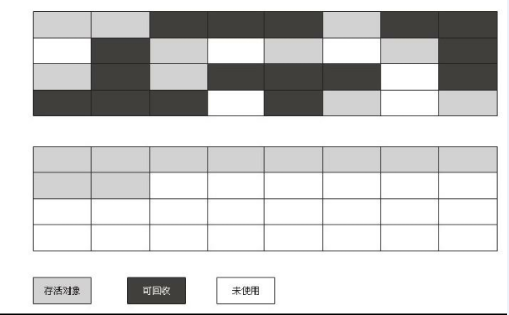
标记-整理算法
分代收集算法
在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记—清理”或者“标记—整理”算法来进行回收。几种常见的垃圾回收器
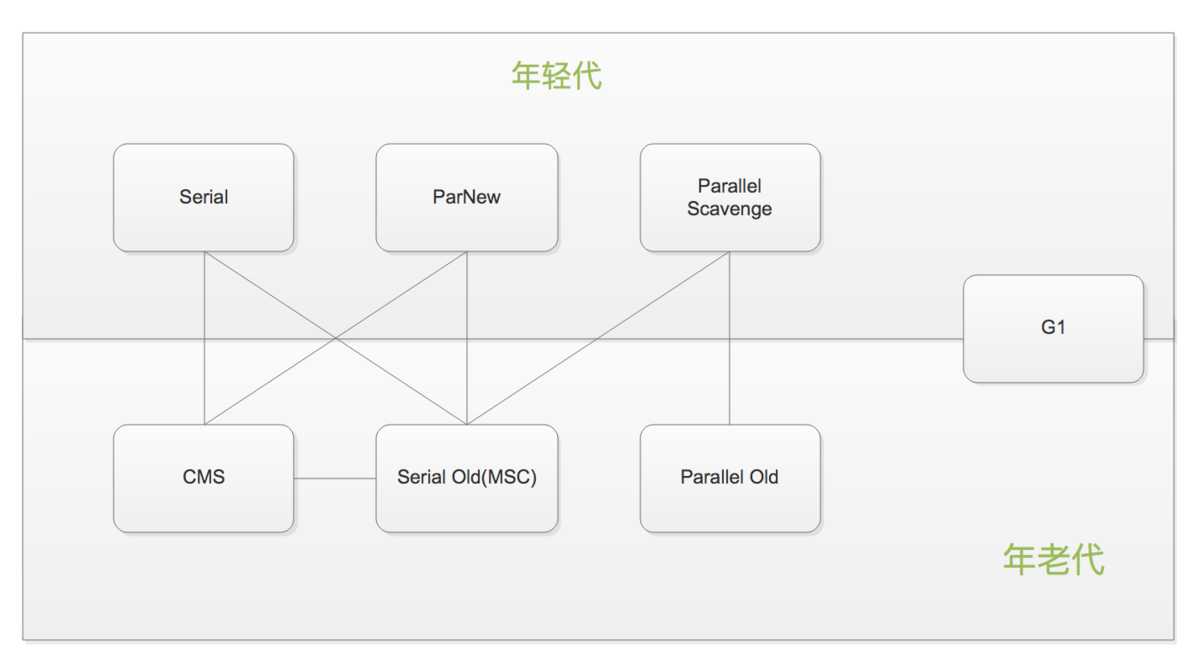
串行:Serial 和Serial Old组合收集
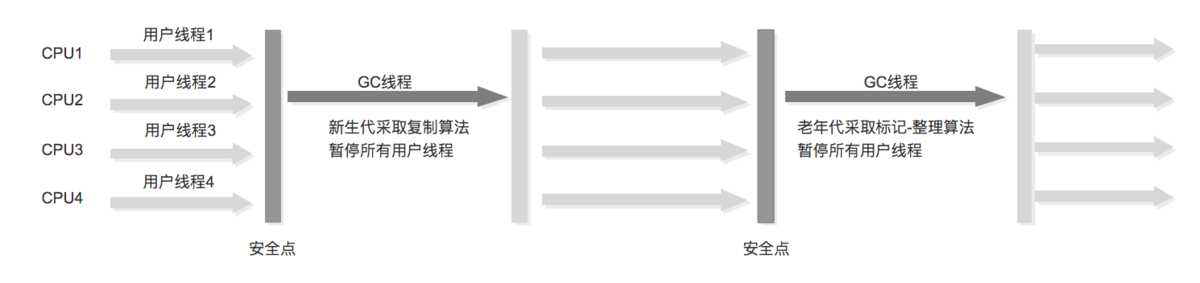
串行:ParNew收集器+Serial Old组合收集
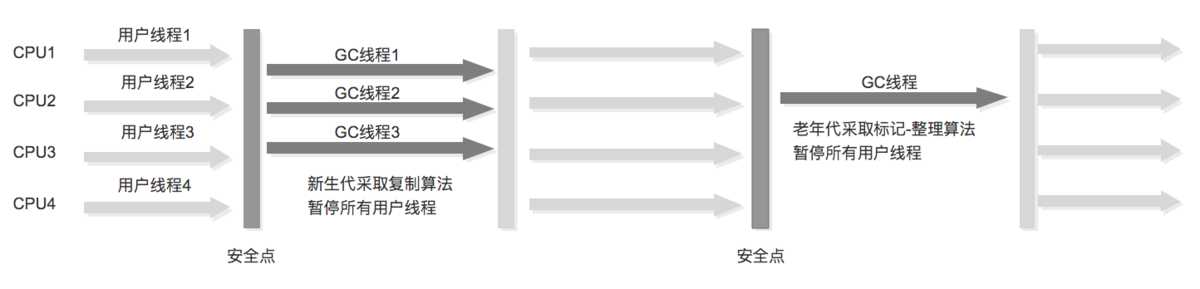
并行:Parallel Scavenge收集器+Serial Old(ps marksweep)组合收集
吞吐量 = 运行用户代码时间 / (运行用户代码时间) + 垃圾收集时间
并行:Parallel Scavenge收集器+Parallel Old组合收集
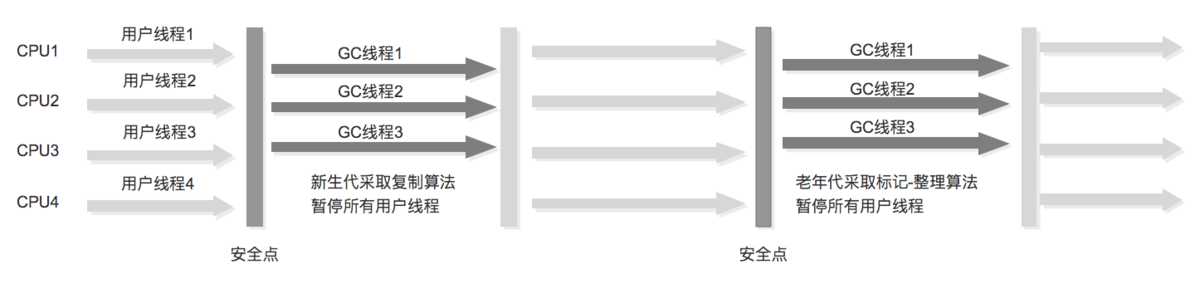
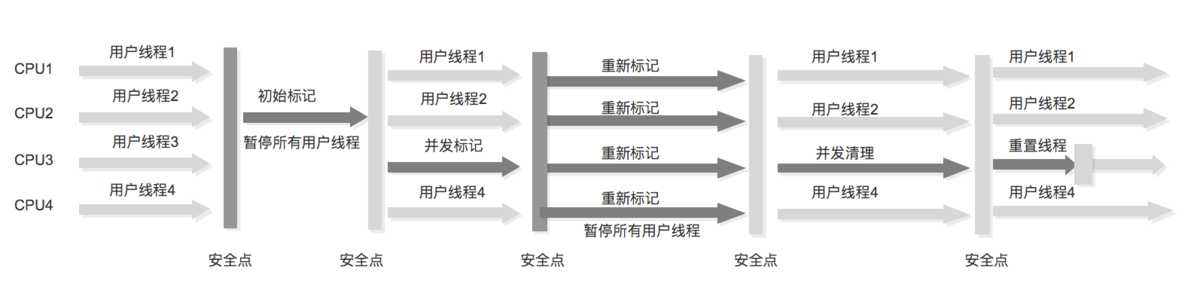
并发:ParNew+标记扫描CMS(Concurrent Mark Sweep)+Serial Old收集器
-XX:+ UseCMSCompactAtFullCollection Full GC后,进行一次碎片整理;整理过程是独占的,会引起停顿时间变长
-XX:+CMSFullGCsBeforeCompaction 设置进行几次Full GC后,进行一次碎片整理
-XX:ParallelCMSThreads 设定CMS的线程数量(一般情况约等于可用CPU数量)
并发:G1收集器
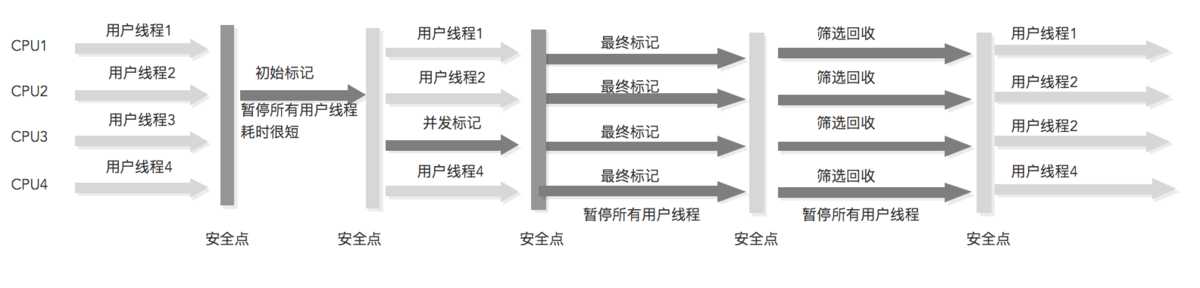
G1的新生代收集跟ParNew类似,当新生代占用达到一定比例的时候,开始出发收集。和CMS类似,G1收集器收集老年代对象会有短暂停顿。
G1收集器的核心思想是在CMS基础上增加了在有限的时间内尽可能高的收集效率。
几种垃圾收集器的组合
总结
参考
https://blog.csdn.net/u011130752/article/details/50886939
https://www.cnblogs.com/grey-wolf/p/9217497.html
https://www.sohu.com/a/217151448_812245