WebMaic介绍
2021-02-04 14:17
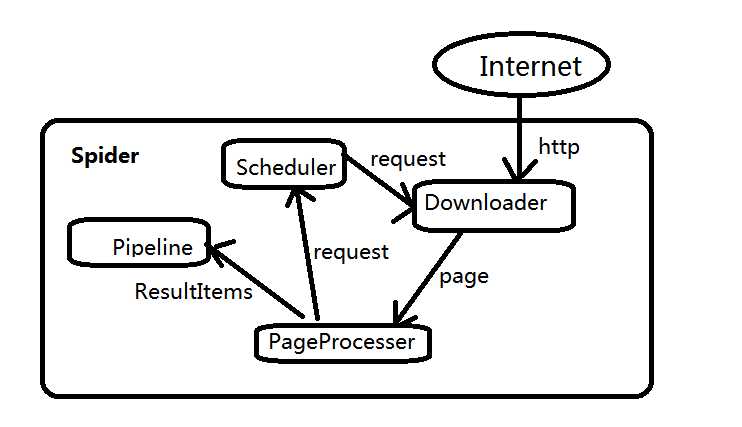
标签:focus 有用 之间 scheduler nload 流转 保存 设计 xpath 一款爬虫框架 WebMagic项目代码分为核心和扩展两部分。 核心部分是一个精简的、模块化的爬虫实现 扩展部分则是包括一些便利的、实用性的功能 架构介绍 WebMagic的结构分为四部分:Downloader、PageProcessor、 Scheduler、Pipeline四大组件,并有Spider将他们彼此组织起来。这四大组件应对爬虫生命周期中的下载、处理、管理和持久化等功能。其设计参考了Scapy,但是实现方式更java化一些 而Spider则将四大组件组织起来,让他们之间可以相互交互,流程化的执行,可以认为Spider是一个大容器,它也是WebMagic逻辑的核心 四大组价的作用 Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认是用了HttpClient作为下载工具 PageProcessor负责页面的解析,抽取有用的信息,以及发现新的连接。WebMagic是用Jsoup作为Html解析工具,并基于其开发了解析Xpath的工具Xsoup 注意:PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分 Scheduler负责管理抓取的url,以及一些去重的工作。WebMagic默认提供了JDK的内从队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理 Pipeline定义了结果的保存方式,如果要保存到指定的数据库,则需要编写对应的Pipeline.对于一类需求一般只需要编写一个Pipeline 用于数据流转的对象 request:是对URL地址的一层封装,一个request对应一个URl地址,是Pageprocessor与Downloder交互的载体,也是P控制D的唯一方式 Page:代表了从Downloder下载到的一个页面---可能是HTML,也可能是Json或者其他文本格式的内容,page是Webmagci抽取过程中的核心对象,他提供一些方法可供抽取,结果保存等 ResultItems:相当于一个Map,他保存Pageorocessor处理的结果,供Pipeline使用。它的API与Map很类似,值得注意的是他有一个字段Skip,若设置为true,则不应该被pipeline处理 WebMaic介绍 标签:focus 有用 之间 scheduler nload 流转 保存 设计 xpath 原文地址:https://www.cnblogs.com/juddy/p/13138598.htmlWebMagic