Netty(五)Netty 高性能之道
2021-02-05 19:17
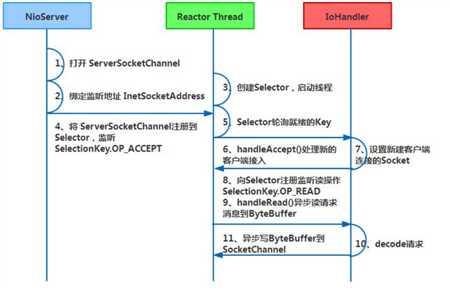
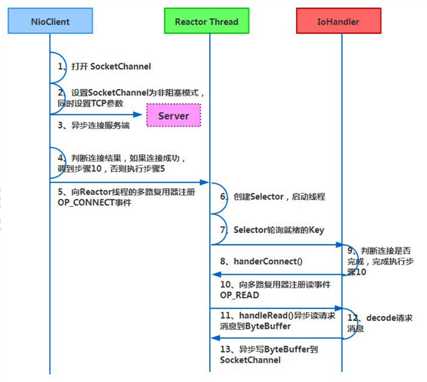
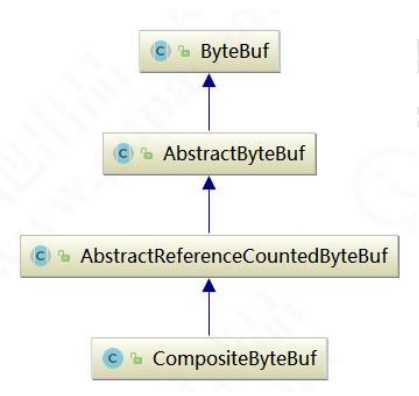
标签:原因 rabl request ddc dem private 安全 时延 selector 4.2 Netty 高性能之道 与 Socket 类和 ServerSocket 类相对应,NIO 也提供了 SocketChannel 和 ServerSocketChannel 两种不同的套接字通 客户端通信序列图如下: 通过继承关系我们可以看出 CompositeByteBuf 实际就是个 ByteBuf 的包装器,它将多个 ByteBuf 组合成一个集合,然 An attempt is made to read up to count bytes starting at
* the given position in this channel‘s file and write them to the
* target channel. An invocation of this method may or may not transfer
* all of the requested bytes; whether or not it does so depends upon the
* natures and states of the channels. Fewer than the requested number of
* bytes are transferred if this channel‘s file contains fewer than
* count bytes starting at the given position, or if the
* target channel is non-blocking and it has fewer than count
* bytes free in its output buffer.
*
* This method does not modify this channel‘s position. If the given
* position is greater than the file‘s current size then no bytes are
* transferred. If the target channel has a position then bytes are
* written starting at that position and then the position is incremented
* by the number of bytes written.
*
* This method is potentially much more efficient than a simple loop
* that reads from this channel and writes to the target channel. Many
* operating systems can transfer bytes directly from the filesystem cache
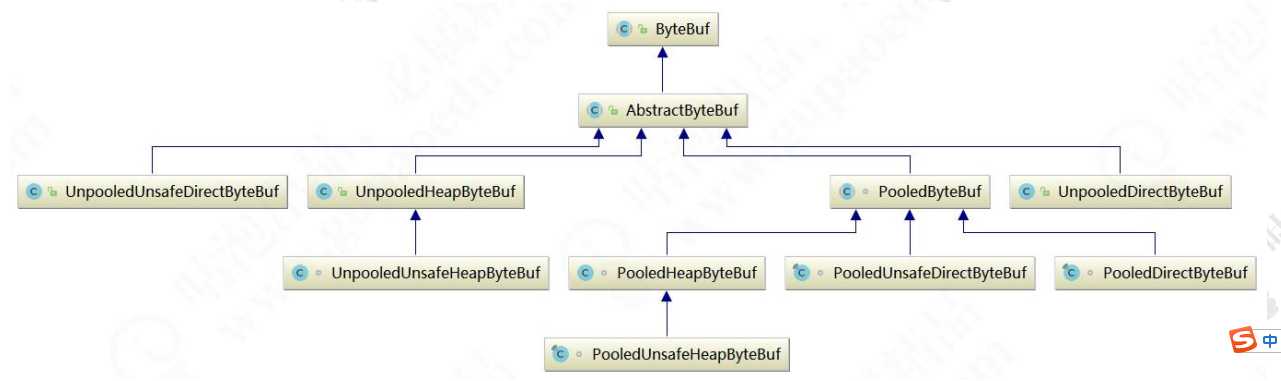
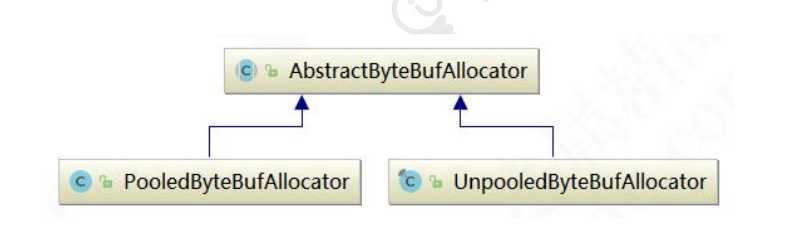
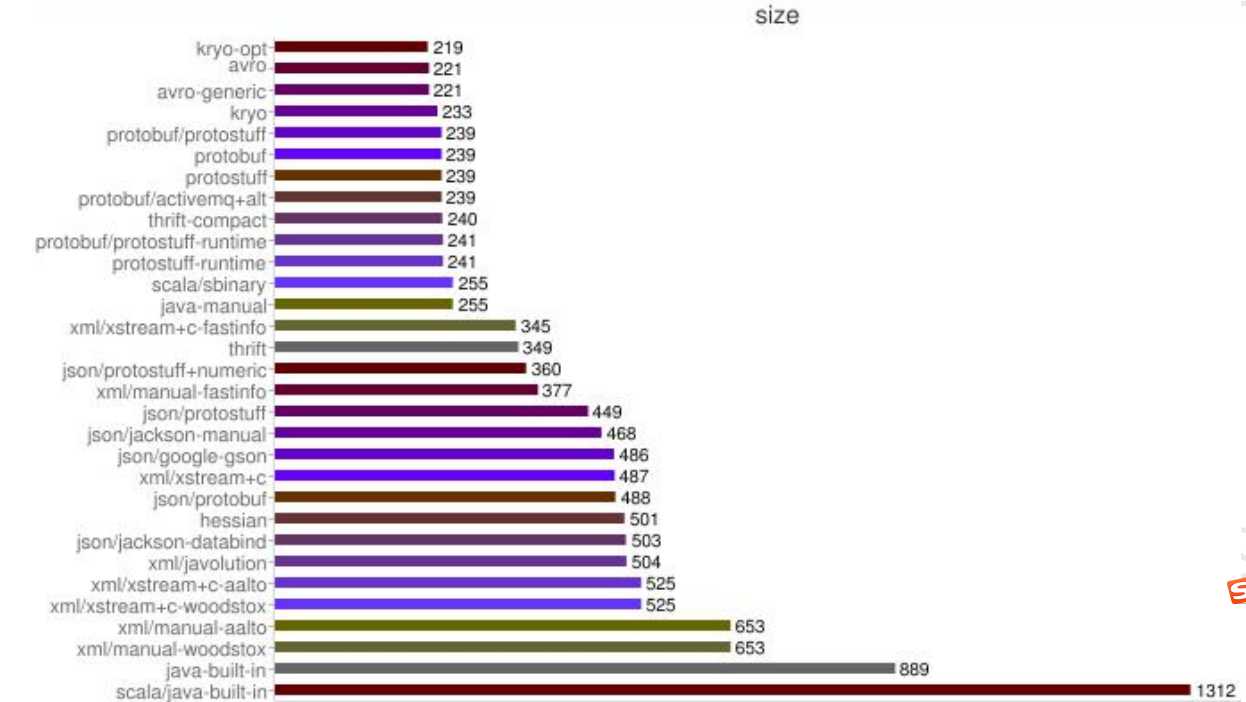
* to the target channel without actually copying them. Netty 提供了多种内存管理策略,通过在启动辅助类中配置相关参数,可以实现差异化的定制。 因此重点分析 DirectArena 的实现:如果没有开启使用 sun 的 unsafe,则 由于 Reactor 模式使用的是异步非阻塞 IO,所有的 IO 操作都不会导致阻塞,理论上一个线程可以独立处理所有 IO 相 Reactor 多线程模型的特点: 利用主从 NIO 线程模型,可以解决 1 个服务端监听线程无法有效处理所有客户端连接的性能不足问题。因此,在 Netty Netty 的 NioEventLoop 读取到消息之后,直接调用 ChannelPipeline 的 fireChannelRead(Object msg),只要用户不主 从上图可以看出,Protobuf 序列化后的码流只有 Java 序列化的 1/4 左右。正是由于 Java 原生序列化性能表现太差, Netty(五)Netty 高性能之道 标签:原因 rabl request ddc dem private 安全 时延 selector 原文地址:https://www.cnblogs.com/flgb/p/13122281.html4.背景介绍
4.1.1 Netty 惊人的性能数据
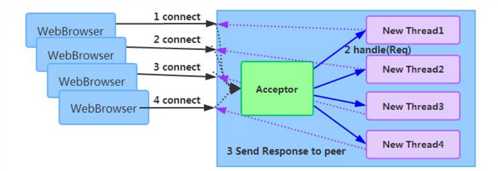
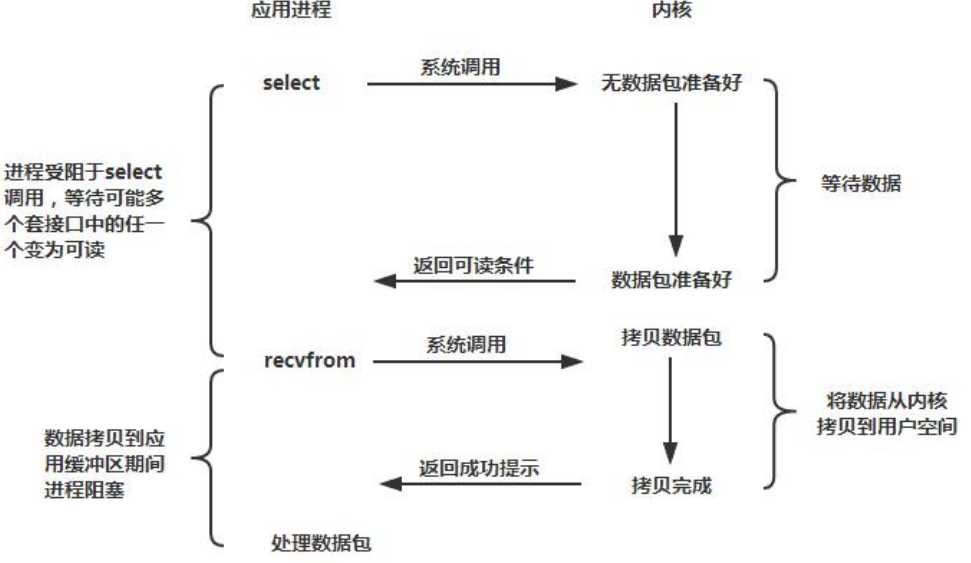
4.1.2 传统 RPC 调用性能差的三宗罪
public final void read() {
ChannelConfig config = AbstractNioByteChannel.this.config();
ChannelPipeline pipeline = AbstractNioByteChannel.this.pipeline();
ByteBufAllocator allocator = config.getAllocator();
Handle allocHandle = this.recvBufAllocHandle();
allocHandle.reset(config);
ByteBuf byteBuf = null;
boolean close = false;
try {
do {
byteBuf = allocHandle.allocate(allocator);
allocHandle.lastBytesRead(AbstractNioByteChannel.this.doReadBytes(byteBuf));
if (allocHandle.lastBytesRead() 0) {
byteBuf.release();
byteBuf = null;
close = allocHandle.lastBytesRead() 0;
break;
}
allocHandle.incMessagesRead(1);
AbstractNioByteChannel.this.readPending = false;
pipeline.fireChannelRead(byteBuf);
byteBuf = null;
} while(allocHandle.continueReading());
allocHandle.readComplete();
pipeline.fireChannelReadComplete();
if (close) {
this.closeOnRead(pipeline);
}
} catch (Throwable var11) {
this.handleReadException(pipeline, byteBuf, var11, close, allocHandle);
} finally {
if (!AbstractNioByteChannel.this.readPending && !config.isAutoRead()) {
this.removeReadOp();
}
}
}
}
public ByteBuf allocate(ByteBufAllocator alloc) {
return alloc.ioBuffer(guess());
}
public abstract class ByteBuf implements ReferenceCounted, Comparable
private static final ByteBuffer EMPTY_NIO_BUFFER = Unpooled.EMPTY_BUFFER.nioBuffer();
private static final Iterator
private int addComponents0(boolean increaseWriterIndex, int cIndex, ByteBuf[] buffers, int offset, int len) {
ObjectUtil.checkNotNull(buffers, "buffers");
int i = offset;
boolean var16 = false;
int var20;
try {
var16 = true;
this.checkComponentIndex(cIndex);
while(true) {
if (i len) {
ByteBuf b = buffers[i++];
if (b != null) {
cIndex = this.addComponent0(increaseWriterIndex, cIndex, b) + 1;
int size = this.components.size();
if (cIndex > size) {
cIndex = size;
}
continue;
}
}
var20 = cIndex;
var16 = false;
break;
}
} finally {
if (var16) {
while(true) {
if (i >= len) {
;
} else {
ByteBuf b = buffers[i];
if (b != null) {
try {
b.release();
} catch (Throwable var17) {
;
}
}
++i;
}
}
}
}
for(; i i) {
ByteBuf b = buffers[i];
if (b != null) {
try {
b.release();
} catch (Throwable var18) {
;
}
}
}
return var20;
}
public long transferTo(WritableByteChannel target, long position) throws IOException {
long count = this.count - position;
if (count >= 0L && position >= 0L) {
if (count == 0L) {
return 0L;
} else if (this.refCnt() == 0) {
throw new IllegalReferenceCountException(0);
} else {
this.open();
long written = this.file.transferTo(this.position + position, count, target);
if (written > 0L) {
this.transferred += written;
}
return written;
}
} else {
throw new IllegalArgumentException("position out of range: " + position + " (expected: 0 - " + (this.count - 1L) + ‘)‘);
}
}
/**
* Transfers bytes from this channel‘s file to the given writable byte
* channel.
*
*
public abstract long transferTo(long position, long count,
WritableByteChannel target)
throws IOException;
package com.lf.io.nio;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.PooledByteBufAllocator;
import io.netty.buffer.Unpooled;
public class BufTest {
public static void main(String[] args) {
directBuf();
}
public static void directBuf() {
final byte[] CONTENT = new byte[1024];
int loop = 1800000;
long startTime = System.currentTimeMillis();
ByteBuf poolBuffer = null;
for (int i = 0; i ) {
poolBuffer = PooledByteBufAllocator.DEFAULT.directBuffer(1024);
poolBuffer.writeBytes(CONTENT);
poolBuffer.release();
}
long endTime = System.currentTimeMillis();
System.out.println("内存池分配缓冲区耗时" + (endTime - startTime) + "ms.");
long startTime2 = System.currentTimeMillis();
ByteBuf buffer = null;
for (int i = 0; i ) {
buffer = Unpooled.directBuffer(1024);
buffer.writeBytes(CONTENT);
}
endTime = System.currentTimeMillis();
System.out.println("非内存池分配缓冲区耗时" + (endTime - startTime2) + "ms.");
}
}
public ByteBuf directBuffer(int initialCapacity, int maxCapacity) {
if (initialCapacity == 0 && maxCapacity == 0) {
return this.emptyBuf;
} else {
validate(initialCapacity, maxCapacity);
return this.newDirectBuffer(initialCapacity, maxCapacity);
}
}
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = (PoolThreadCache)this.threadCache.get();
PoolArena
PooledByteBuf
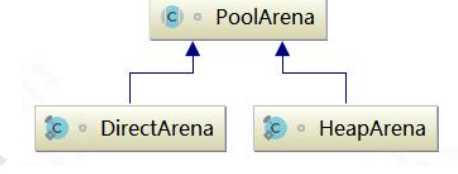
protected PooledByteBuf
static PooledDirectByteBuf newInstance(int maxCapacity) {
PooledDirectByteBuf buf = (PooledDirectByteBuf)RECYCLER.get();
buf.reuse(maxCapacity);
return buf;
}
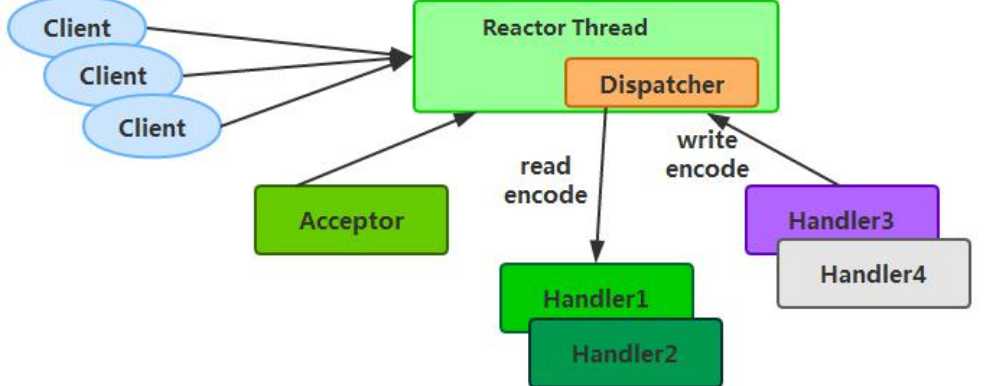
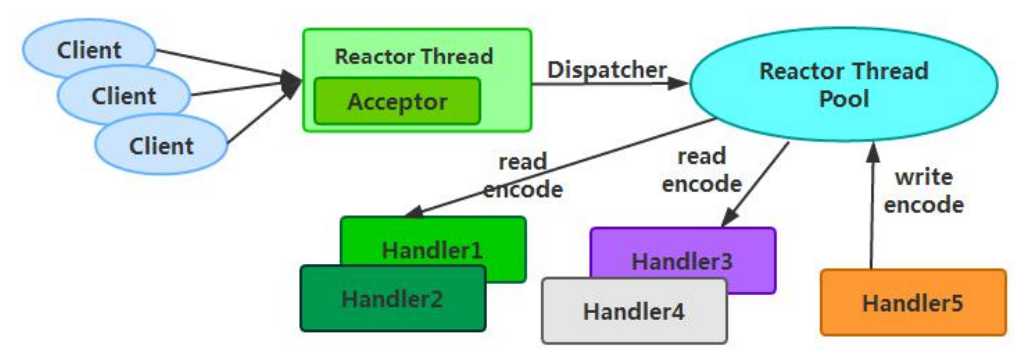
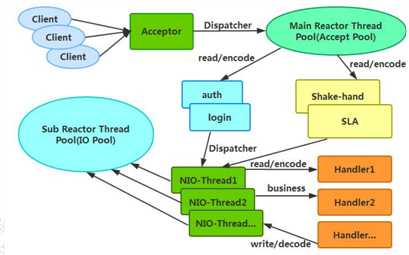



上一篇:jsp-servlet面试题
下一篇:PHP配置文件www.conf