李航统计学习方法(第二版)(五):k 近邻算法简介
2021-02-06 00:18
标签:src 其他 应用 输出 欧氏距离 二维 预测 方法 假设 k近邻法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类。k近邻法假设给定一个训练数据集,其中的实例类别已定。 2.1 简介 k近邻法中,当训练集、距离度量(如欧氏距离)、k值及分类决策规则(如多数表决)确定后,对于任何一个新的输入实例,它所属的类唯一地确定。 这相当于根据上述要素将特征空间划分为一些子空间,确定子空间里的每个点所属的类。 特征空间中,对每个训练实例点 每个训练实例点拥有一个单元,所有训练实例点的单元构成对特征空间的一个划分。 2.2 距离度量 欧式距离 曼哈顿距离 各个坐标距离的最大值 2.3 k值选择 在应用中,k值一般取一个比较小的数值。通常采用交叉验证法来选取最优的k值。 2.4 分类决策规则 k近邻法中的分类决策规则往往是多数表决,即由输入实例的k个邻近的训练实例中的多数类决定输入实例的类。 输入 输出 特征向量 李航统计学习方法(第二版)(五):k 近邻算法简介 标签:src 其他 应用 输出 欧氏距离 二维 预测 方法 假设 原文地址:https://www.cnblogs.com/qiu-hua/p/12785180.html1 简介
分类时,对新的实例,根据其k个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此,k近邻法不具有显式的学习过程。
k近邻法实际上利用训练数据集对一特征向量空间进行划分,并作为其分类的“模型”。k值的选择、距离度量及分类决策规则是k近邻法的三个基本要素。2 模型
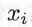 ,距离该点比其他点更近的所有点组成一个区域,叫作单元(Cell)。
,距离该点比其他点更近的所有点组成一个区域,叫作单元(Cell)。
最近邻法将实例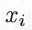 的类
的类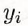 ,作为其单元中所有点的类标记(class label)。这样,每个单元的实例点的类别是确定的。图3.1是二维特征空间划分的一个例子。
,作为其单元中所有点的类标记(class label)。这样,每个单元的实例点的类别是确定的。图3.1是二维特征空间划分的一个例子。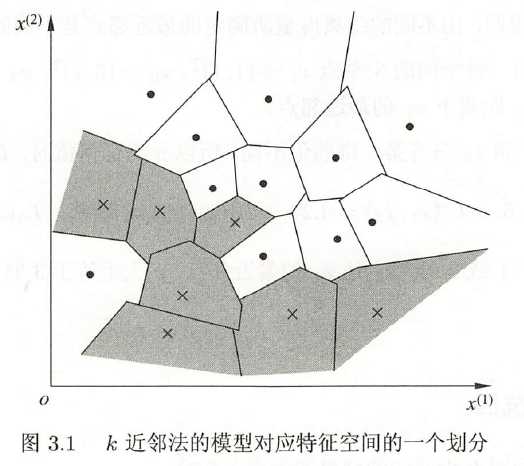


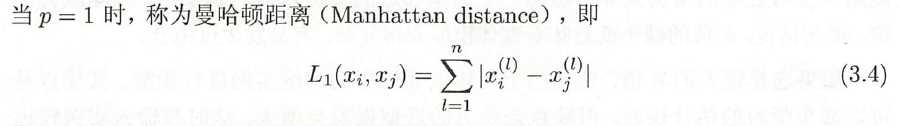
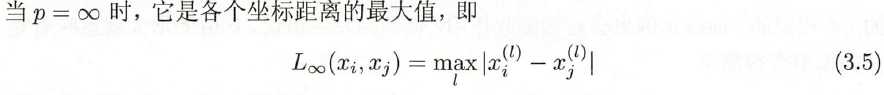


3 算法


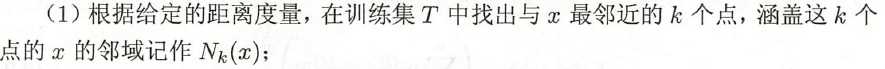

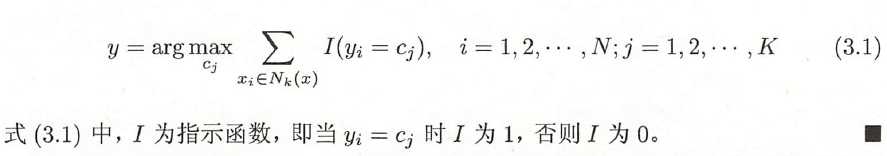
上一篇:springMVC依赖注意事项