Apache Spark有哪些局限性
2021-02-07 06:17
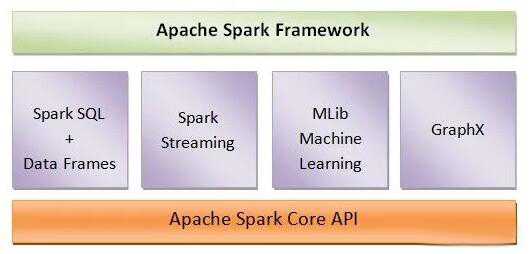
标签:计算 转移 min 流行 loading 结构 集群计算 组件 lib Apache Spark是行业中流行和广泛使用的大数据工具之一。Apache Spark已成为业界的热门话题,并且如今非常流行。但工业正在转移朝向apache flink。 Apache Spark简介 Apache Spark是为快速计算而设计的开源,闪电般快速的集群计算框架。Apache Spark扩展了MapReduce模型,以有效地将其用于多种计算,包括流处理和交互式查询。Apache Spark的主要功能是内存中的群集计算,可以提高应用程序的处理速度。 Spark计划用于涵盖各种工作负载,例如迭代算法,批处理应用程序,流和交互式查询。除了支持这些工作负载,它还减少了维护不同工具的管理障碍。 Apache Spark框架的核心组件 Apache Spark框架由负责Spark功能的主要五个组件组成。这些组成部分是– Spark SQL和数据框架–在顶部,Spark SQL允许用户运行SQL和HQL查询以处理结构化和半结构化数据。 SparkStreaming – Spark流传输有助于处理实时流数据,即日志文件。它还包含用于处理数据流的API MLib机器学习– MLib是具有机器学习功能的Spark库。它包含各种机器学习算法,例如回归,聚类,协作过滤,分类等。 GraphX –支持图形计算的库称为GraphX。它使用户能够执行图操作。它还提供了图形计算算法。 Apache Spark Core API –它是Spark框架的内核,并提供了一个执行Spark应用程序的平台。 下图清楚地显示了Apache Spark的核心组件。 Apache Spark的局限性 用户在使用它时必须面对Apache Spark的一些限制。本文完全侧重于Apache Spark的限制以及克服这些限制的方法。让我们详细阅读Apache Spark的以下限制以及克服这些Apache Spark限制的方法。 1.没有文件管理系统 Apache Spark中没有文件管理系统,需要与其他平台集成。因此,它依赖于Hadoop等其他平台或任何其他基于云的文件管理系统平台。这是Apache Spark的主要限制之一。 2.不进行实时数据处理 Spark不完全支持实时数据流处理。在Spark流中,实时数据流被分为几批,称为Spark RDD(弹性分布式数据库)。在这些RDD上应用诸如join,map或reduce等操作来处理它们。处理后,结果再次转换为批次。这样,Spark流只是一个微批处理。因此,它不支持完整的实时处理,但是有点接近它。 3.昂贵 在谈论大数据的经济高效处理时,将数据保存在内存中并不容易。使用Spark时,内存消耗非常高。Spark需要巨大的RAM来处理内存。Spark中的内存消耗非常高,因此用户友好性并不高。运行Spark所需的额外内存成本很高,这使Spark变得昂贵。 4.小文件发行 当我们将Spark与Hadoop一起使用时,存在文件较小的问题。HDFS附带了数量有限的大文件,但有大量的小文件。如果我们将Spark与HDFS一起使用,则此问题将持续存在。但是使用Spark时,所有数据都以zip文件的形式存储在S3中。现在的问题是所有这些小的zip文件都需要解压缩才能收集数据文件。 仅当一个核心中包含完整文件时,才可以压缩zip文件。仅按顺序刻录核心和解压缩文件需要大量时间。此耗时的长过程也影响数据处理。为了进行有效处理,需要对数据进行大量改组。 5.延迟 Apache Spark的等待时间较长,这导致较低的吞吐量。与Apache Spark相比,Apache Flink的延迟相对较低,但吞吐量较高,这使其比Apache Spark更好。 6.较少的算法 在Apache Spark框架中,MLib是包含机器学习算法的Spark库。但是,Spark MLib中只有少数几种算法。因此,较少可用的算法也是Apache Spark的限制之一。 7.迭代处理 迭代基本上意味着重复使用过渡结果。在Spark中,数据是分批迭代的,然后为了处理数据,每次迭代都被调度并一个接一个地执行。 8.窗口标准 在Spark流传输中,根据预设的时间间隔将数据分为小批。因此,Apache Spark支持基于时间的窗口条件,但不支持基于记录的窗口条件。 9.处理背压 背压是指缓冲区太满而无法接收任何数据时,输入/输出开关上的数据累积。缓冲区为空之前,无法传输数据。因此,Apache Spark没有能力处理这种背压,但必须手动完成。 10.手动优化 使用Spark时,需要手动优化作业以及数据集。要创建分区,用户可以自行指定Spark分区的数量。为此,需要传递要固定的分区数作为并行化方法的参数。为了获得正确的分区和缓存,应该手动控制所有此分区过程。 尽管有这些限制,但Apache Spark仍然是流行的大数据工具之一。但是,现在已经有许多技术取代了Spark。Apache Flink是其中之一。Apache Flink支持实时数据流。因此,Flink流比Apache Spark流更好。 总结 每种工具或技术都具有一些优点和局限性。因此,Apache Spark的限制不会将其从游戏中删除。它仍然有需求,并且行业正在将其用作大数据解决方案。最新版本的Spark进行了不断的修改,以克服这些Apache Spark的局限性。 免费领取技术资料及视频 Apache Spark有哪些局限性 标签:计算 转移 min 流行 loading 结构 集群计算 组件 lib 原文地址:https://www.cnblogs.com/Jss-forever/p/13095498.html