教你nodejs爬虫制作知乎专栏RSS抓取程序
2021-02-18 07:18
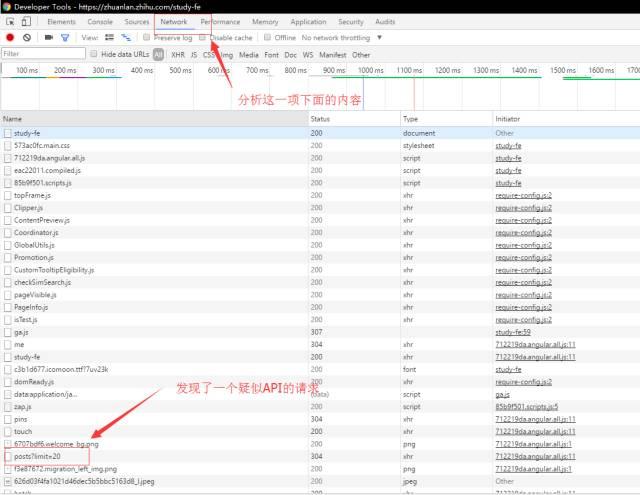
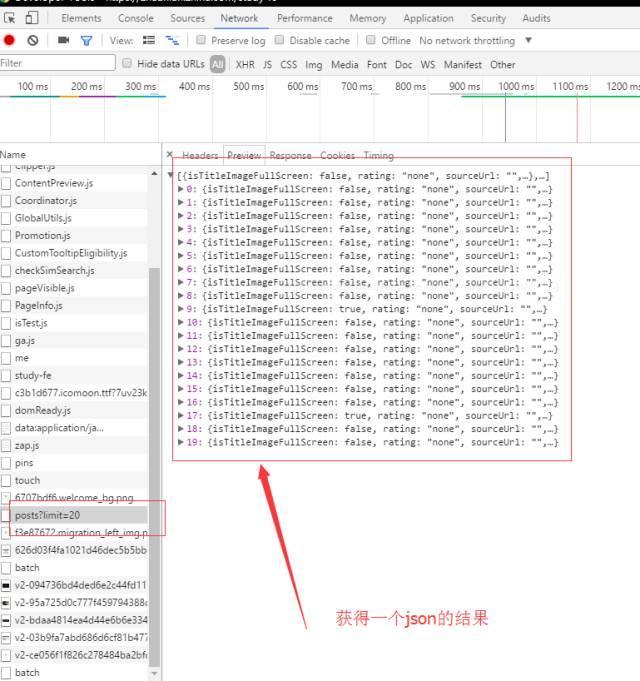
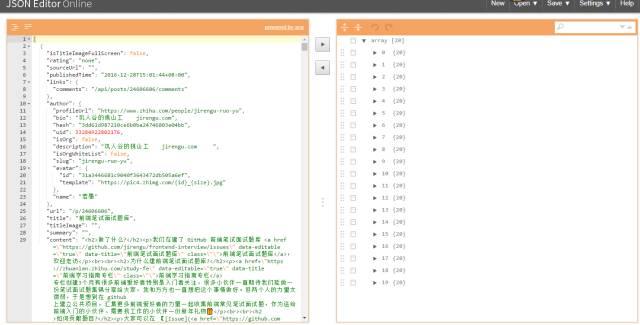
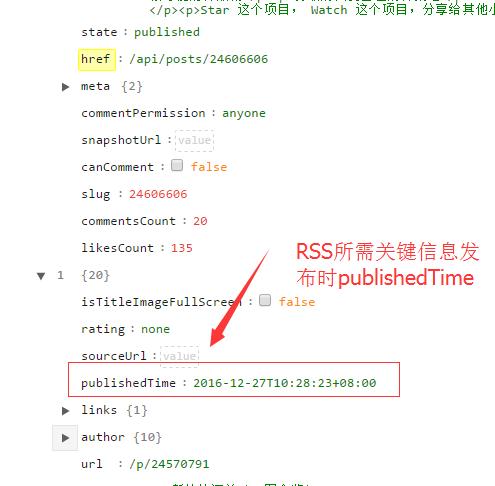
标签:可视化 渲染 适配 ice init ref rom lock links 现在这个社会是信息爆炸的社会,各个网站、app上铺天盖地的都是各种新闻和信息。 为了获取信息,我们每天都要进行各种麻烦的操作,打开各种网站或者手机app,操作显得低效,后来发现了一个神器,那就是RSS。 RSS中文名是简易信息聚合,就是让网站一个按照一定周期更新网站的文章概要内容(有些是全文)到一个xml中。RSS订阅工具一定时间抓取这个RSS订阅源生成数据供订阅者读取网站内容。 有了RSS,你只要去订阅工具上就可以浏览你自己订阅的新的更新内容,非常简单高效。这里推荐一个RSS订阅神器inoreader,支持中文。这个我认为是目前最好的RSS订阅器。 知乎专栏是一个知乎开给个人写的博客,有些专栏上面具有有价值的信息,但是很遗憾知乎专栏不提供RSS订阅,当然作为开发者来说,我们可以自己动手做一个知乎专栏RSS抓取程序。 很多网站提供了RSS,但是更多网站其实没有提供RSS订阅源。我们可以使用爬虫抓取网站更新内容制作个人的RSS订阅源。我作为一个前端er可以使用nodejs来进行RSS的制作。 Node.js是一个基于Chrome JavaScript运行时建立的平台, 用于方便地搭建响应速度快、易于扩展的网络应用。Node.js 使用事件驱动, 非阻塞I/O 模型而得以轻量和高效,非常适合在分布式设备上运行数据密集型的实时应用。 简单的说 Node.js 就是运行在服务端的 JavaScript。使用nodejs的可以让你一个只会用JavaScript也能写后端服务代码。当然也能用它进行爬虫抓取的工作。 进行爬取工作的话先要安装所要用到的依赖。 superagent是最常用的一个依赖库,利用它可以轻松发送各种请求。 cheerio就是一个nodejs版本的jquery,利用它可以获取网页中的各种dom结构。 data2xml就是一个json转化成xml的一个库。 其他还有node-schedule和fs就是进行定时操作和文件操作。 新建一个文件夹rssmaker,并且执行npm init创建package.json。 用npm install node_modules_name --save来进行安装各种依赖。 我这次举例爬取一个专栏前端学习指南。像这种适配手机端的网页,一般都有采用发送API请求来获得数据进行前端渲染页面,我们可以用chrome的network的查看可疑的请求。打开chrome的开发者工具。我们很快就发现了一个目标。一个可疑请求https://zhuanlan.zhihu.com/api/columns/study-fe/posts?limit=20 我们得到了一个json,我们现在使用一个json的查看工具chrome的插件JSON Editor可视化这个json数据方便我们进行分析。 我们可视化后数据如下: 前面我们发现的请求发送里面有一个参数是limit,它的值是20,从上图我们知道了我们得到了20组数据,这个参数其实就是限制获取的数据条目数。我们现在分析20组里面的一条数据。 我们在建了 GitHub 前端笔试面试题库 前端笔试面试题库, 欢迎走访 前端学习指南专栏 专栏创建3个月有很多前端爱好者特别是入门者关注,很多小伙伴一直期待我们能做一份笔试面试题集锦分享给大家,我和方方也一直想把这个事情做好。但两个人的力量太微弱,于是想到在 github 上建立公共项目,汇集更多前端爱好者的力量一起收集前端常见笔试面试题,作为送给前端入门的小伙伴、需要找工作的小伙伴一份新年礼物?? 大家可以在 【[Issue](jirengu/frontend-interview)】上通过提交Issue的形式提交日常遇到的笔试面试题,无论是多\"高端\"或者多\"低级\"。 注意: 不要吝啬自己的答案,在脑子里的答案不叫答案,只有写下来后才知道答案没那么简单,面试官真问起的时候才能对答如流 勇敢的回复自己的答案吧 觉得不错? Star 这个项目, Watch 这个项目,分享给其他小伙伴吧 我们可以通过《XML那些事...》 实现简单的RSS可知RSS几个关键的值。跟上图截图的对应。 我们现在知道爬取的入口,那么我们现在开始coding吧。 新建一个文件studyfe.js,在文件中用require引入各种依赖。然后我们用superagent获取数据后进行数组的拼装。 而在得到这个数组的时候,我们已经相当于得到了所有要采集的数据了,那下面要做的东西就很简单了,那就是json数组转化成xml格式。而转化我们我们要用到data2xml这个库。在开头我们已经require进来了。 data2xml的使用文档可以查看data2xml-npmjs.com 最后就是把数据输出到文件中去 输出到文件之后,然后要把这个文件放到服务器上,这样才能被rss服务器抓取到,如何放在服务器上这本文就不讨论了,还有一个问题就是RSS需要实时更新的,所以还有使用定时抓取,这次用到的是node-schedule。里面的定时写法其实跟linux中的crontab定时任务写法是很相似的。下面的代码其实代表着每3分钟定时执行一次。 定时执行任务还会有一个问题就是在nodejs在执行异常的时候退出,这样就会导致不会实时抓取,这个要用到一个nodejs中能自动重启任务的,我用的是pm2。 为此,为了学好前端,创建了一个学习交流裙,能够与大家一起学习、交流。大家免费领取面试题,电子书籍,特效项目源码等干货。 教你nodejs爬虫制作知乎专栏RSS抓取程序 标签:可视化 渲染 适配 ice init ref rom lock links 原文地址:https://www.cnblogs.com/coderhf/p/12942787.html什么是RSS
制作爬虫
什么是nodejs
先安装爬虫所需依赖
分析知乎专栏结构获取要爬取的入口
 4
4
 5
5
 6
6
{ "isTitleImageFullScreen": false, "rating": "none", "sourceUrl": "", "publishedTime": "2016-12-28T15:01:44+08:00", "links": { "comments": "/api/posts/24606606/comments"
}, "author": { "profileUrl": "https://www.zhihu.com/people/jirengu-ruo-yu", "bio": "饥人谷的挑山工 jirengu.com", "hash": "3dd61d987210ce6b0ba24746803e04bb", "uid": 33284922802176, "isOrg": false, "description": "饥人谷的挑山工 jirengu.com ", "isOrgWhiteList": false, "slug": "jirengu-ruo-yu", "avatar": { "id": "31a3446681c9040f3643472db505a6ef", "template": "https://pic4.zhimg.com/{id}_{size}.jpg"
}, "name": "若愚"
}, "url": "/p/24606606", "title": "前端笔试面试题库", "titleImage": "", "summary": "", "content": "
做了什么?
为什么建前端笔试面试题库?
如何贡献题目?

如何贡献答案?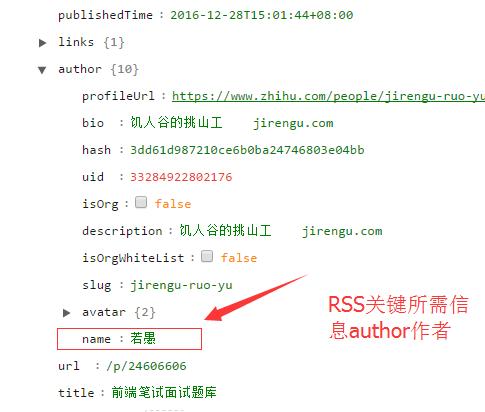
 8
8
 9
9
 10
10
用superagent抓取数据组成数组
 11
11

 13
13

 扫描二维码学习
扫描二维码学习