讲解GoogleNet的Inception从v1到v4的演变
2021-02-19 19:20
标签:组成 优秀 googlenet 研究 ESS 结合 速度 str ado GoogleNet和VGG是ImageNet挑战赛中的第一名和第二名。共同特点就是两个网络的层次都更深了。但是: 对于GoogleNet结构的描述,什么是GoogleNet?什么是Inception?GoogleNet结构详解(2014年) 对了GoogLeNet,可不是GoogleNet!!,我之前都打错了哈哈,据说是向LeNet致敬哈哈哈 总之,Inception是GoogLeNet的核心,GoogLeNet优秀,一方面是运算速度快,而这就是Inception的功劳。 1x1的卷积核有什么用呢? 1x1卷积的主要目的是为了减少维度,还用于修正线性激活(ReLU)。比如,上一层的输出为100x100x128,经过具有256个通道的5x5卷积层之后(stride=1,pad=2),输出数据为100x100x256,其中,卷积层的参数为128x5x5x256= 819200。而假如上一层输出先经过具有32个通道的1x1卷积层,再经过具有256个输出的5x5卷积层,那么输出数据仍为为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256= 204800,大约减少了4倍。 为什么会有池化层在其中呢? 一般来说,想让图像缩小,有以下两种方式: 设计人员想,如果只是单纯的堆叠网络,虽然可以提高准确率,但是会导致计算效率的下降,如何在不增加过多额计算量的同时提高网络的表达能力呢? 卷积分解(Fatorizing Convolutions) 大尺寸的卷积核可以带来更大的感受野,但是也意味着更多的参数,比如size=5的卷积核有25个参数,size=3的有9个参数。GoogLeNet团队提出可以用2个连续的3x3的卷积核组成小网络来代替单个size=5的卷积层: 团队更新了网络中的Inception的结构,如下图: 最重要的改进就是分解Factorization,把7x7分解成两个一维的卷积(1x7和7x1),3x3的也是一样,这样的好处是,既可以加速运算,又可以将一个卷积拆成两个卷积,这样使得网络的深度进一步加深,并且增加了网络的非线性。(每增加一层都要用ReLU),此时网络的输入也从224x224变成299x299。 研究了Inception模块与残差连接的结合,ResNet结构大大加深了网络的深度,而且极大的提高了训练速度。总之,Inception v4就是利用残差连接(Residual Connection)来改进v3,得到Inception-ResNet-v1, Inception-ResNet-v2, Inception-v4网络 然后通过二十个类似的模块,得到: 讲解GoogleNet的Inception从v1到v4的演变 标签:组成 优秀 googlenet 研究 ESS 结合 速度 str ado 原文地址:https://www.cnblogs.com/PythonLearner/p/12925712.html
Inception v1
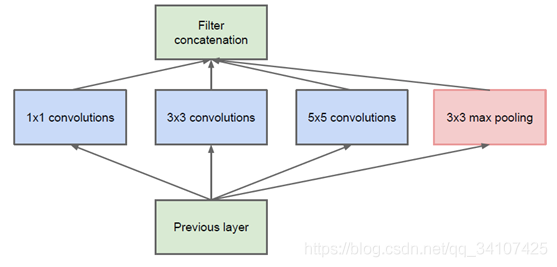 设计一个稀疏网络结构,但是怎么产生稠密的数据呢。就用这个!CNN中常见的三种卷积核,和池化操作堆叠在一起,一方面增加了网络的宽度,另一方面也加强了网络对尺度的是影响。但是这个原始的版本思路是好的,但是计算量太大了,因此作者对3x3和5x5的卷积层之前用了1x1的缩小图片的channel数量,因此V1是这个样子:
设计一个稀疏网络结构,但是怎么产生稠密的数据呢。就用这个!CNN中常见的三种卷积核,和池化操作堆叠在一起,一方面增加了网络的宽度,另一方面也加强了网络对尺度的是影响。但是这个原始的版本思路是好的,但是计算量太大了,因此作者对3x3和5x5的卷积层之前用了1x1的缩小图片的channel数量,因此V1是这个样子: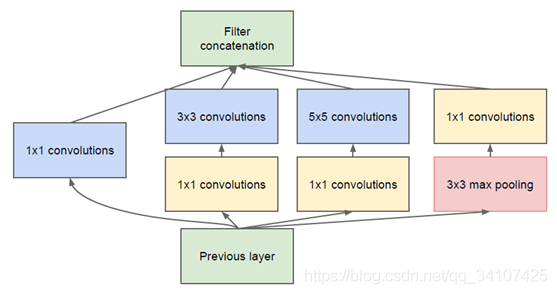
但是左边的方法先池化层后inception,这样会导致特征的确实,而右边的方法,会导致运算量很大。为了同时保持特征并且降低运算发,将网络改成下图,使用两个并行化的模块来降低计算量,也就是池化,卷积并行,然后再合并inception V2
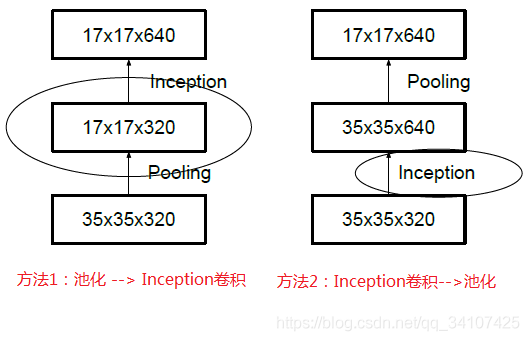
通过大量的实验证明,这样的方案并不会导致表达的缺失。更进一步,团队考虑了nx1的卷积核,如下图:
因此,任意的nxn的卷积都可以通过nx1后接上1xn来代替。但是团队发现在网络的前期使用这样分解的效果并不好,在中部使用效果才会好。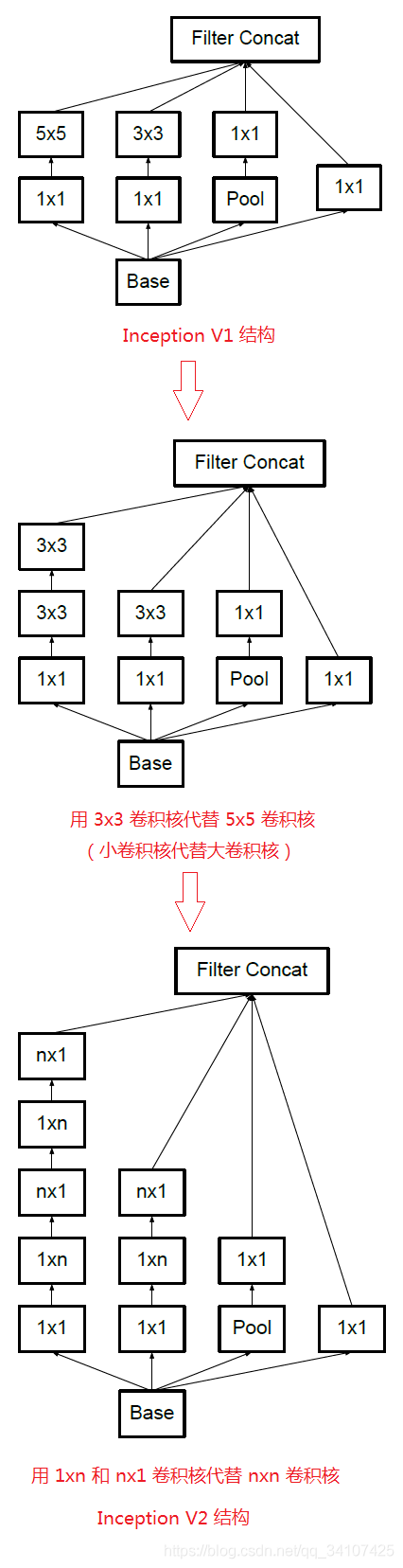
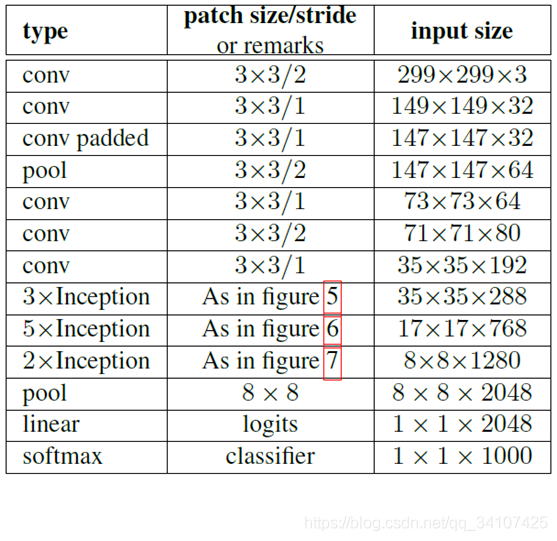 figure5是原来的v1版本,然后figure6是改成两个3x3的版本,然后figure7是改成了1xn和nx1的版本。
figure5是原来的v1版本,然后figure6是改成两个3x3的版本,然后figure7是改成了1xn和nx1的版本。inception v3
Inception v4
我们先简单的看一下什么是残差结构: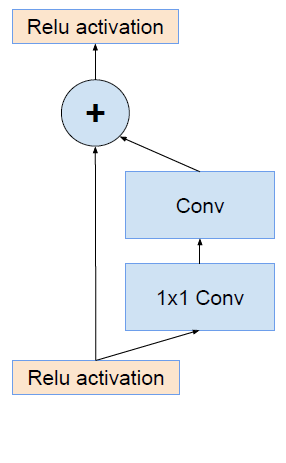
结合起来就是: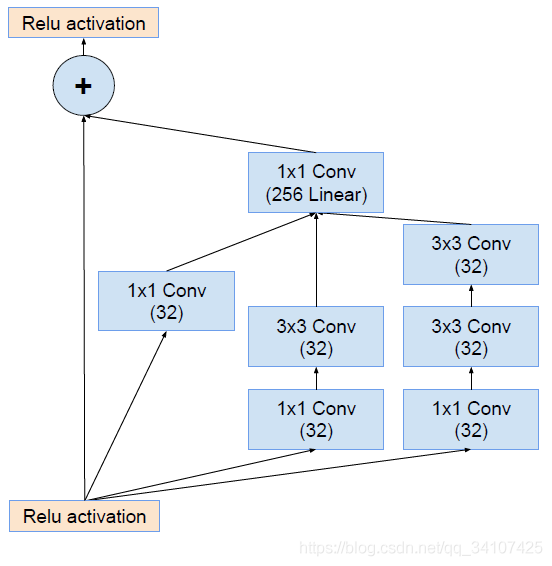
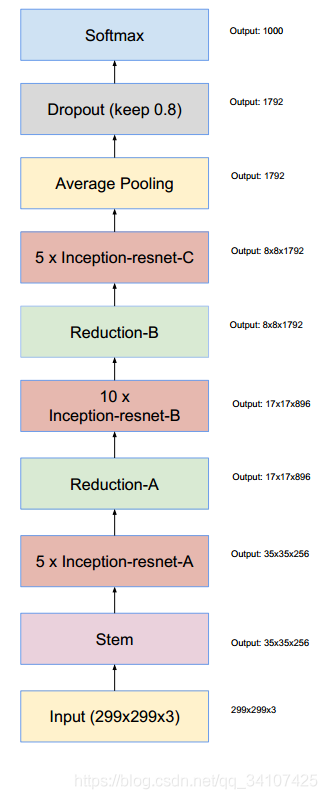
参考博文:
googleNet
文章标题:讲解GoogleNet的Inception从v1到v4的演变
文章链接:http://soscw.com/essay/57666.html