讲解GoogleNet的Inception从v1到v4的演变
2021-02-19 19:21
标签:产生 数据集 -o new ret https 返回 host 拼接 GhostNet是华为诺亚方舟实验室提出的一个新型神经网络结构。目的类似Google提出的MobileNet,都是为了硬件、移动端设计的轻小网络,但是效果想摆MobileNet更好。 GhostNet基于Ghost模块,这个特点是不改变卷积的输出特征图的尺寸和通道大小,但是可以让整个计算量和参数数量大幅度降低。简单的说,GhostNet的主要贡献就是减低计算量、提高运行速度的同时,精准度降低的更少了,而且这种改变,适用于任意的卷积网络,因为它不改变输出特征图的尺寸。下面来具体看一看GhostNet到底是怎么实现的吧。 GhostNet发现了一个这样的问题:想象一张要进行分类的图片,这个图片经过卷积层,假设产生了16个通道的特征图,如果我们把16个通道的图画出来,变成16个黑白图片,我们可以保证,每一个特征图都体现了原来图片不同的特征吗?如图19.9所示: 注意:这个相似的特征图,叫做Ghost,鬼影。 GhostNet的整体结构是仿照MobileNet-v3的结构,只是用Ghost Module作为基本组件,这里也不多将MobileNet-v3的结构了,下面要讲的就是我们能从GhostNet中到底学到什么?学到怎么用GhostNet的基本思想来降低我们模型的计算量。下面的内容就会围绕着GhostNet的Ghost-Blockneck展开。 注意:这个Ghost-Blockneck是基于Ghost Module组件,还有SE Module和Depthwise卷积。 Ghost Module就是GhostNet的主要贡献了。来看代码: 一个非常标准的PyTorch模型类的定义。代码中主要有以下内容需要注意: 之前在MobileNet的深度可分离卷积中已经讲了什么是Depthwise,其实这就是分组卷积的一种形式。如果分的组数等于输入特征图的通道数,那么就是Depthwise了,如果分的组没有那么多,就是一般的分组卷积。具体区分如图19.10所示: 有一个参数groups就是要分的组数,如果groups的数值等于输入通道数,那么就是Depthwise的方法。 注意:现在用分组卷积的话,一般就是用Depthwise的方法,所以要是看到Depthwise,实现的时候要想到用分组卷积groups这个参数。 SE Module是SENet网络提出的Module,这个网络在2017年的ImageNet的图像分类任务中拿到了冠军。SENet是啥就不说了,2017年的冠军现在在AI领域中现在已经有点过时了,但是SENet的核心SE Module保留了下来。 SE是Squeeze-and-Excitation,挤压与刺激(这个SE的翻译有点奇怪)。废话不多说,直接看代码来理解吧: 这个自适应池化层,其实就是可以随便设置池化之后的尺寸,然后这个都可以适应。比方说,输入的维度是[16,64,7,7],这个batch中有16个特征图,然后每一个图片有64个通道,特征图的尺寸是7*7的,然后假设设置的参数是(5,7),那么可以得到[16,64,5,7]这样的池化结果。具体过程就不讲解了,在这里只用知道怎么用就行了。 这里的参数是1,那么就会产生[16,64,1]这样的结果。说白了,就是一个全局平均池化层嘛。 然后继续上面的例子,把这个[16,64,1]变成[16,64]之后输入到全连接层,经过两层全连接层后还是[16,64]的尺寸,然后x*y就是SE Module的最终返回值。 其实很好理解,相当于SE Module对通道进行了一个权重的评估。有的通道可能重要,有的通道可能不重要,所以经过这个过程让特征图的每一个通道,得到了1个权重值。如何体现权重值的?就是让那个通道的每一个值,都乘上这个权重值就行了,简单粗暴,但是是有效果的。 讲解GoogleNet的Inception从v1到v4的演变 标签:产生 数据集 -o new ret https 返回 host 拼接 原文地址:https://www.cnblogs.com/PythonLearner/p/12925714.html通俗讲:端侧神经网络GhostNet(2019)
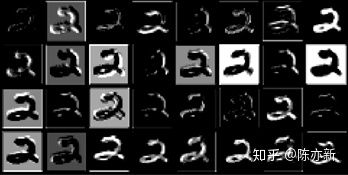
图19.9是处理MNIST手写数据集中第一层卷积层产生的32个特征图的图像,你可以找到多少组重复的、极为类似的特征图呢?不少吧。GhostNet就是觉得,既然有这么多的特征图都是相似的,那么生成相似的特征图的那部分计算量不就是多余的可以节省的嘛。19.14.1 Ghost Module
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels*(ratio-1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, padding=kernel_size//2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels,dw_size,stride=1,
padding=dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1,x2], dim=1)
return out[:,:self.oup,:,:]
19.14.2 Group Convolution分组卷积
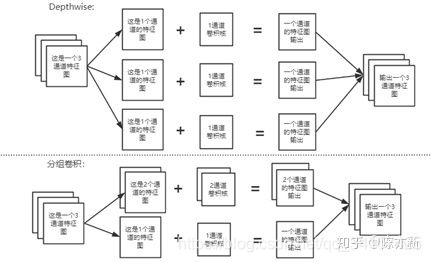
在这里介绍分组卷积只是因为在代码中使用到了这个概念。在代码中可以看到生成鬼影特征图的时候,使用的是分组卷积(也是Depthwise):self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels,dw_size,stride=1,
padding=dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
19.14.3 SE Module
class SELayer(nn.Module):
def __init__(self, channel, reduction=4):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction), # //是求商,%是求余数。8//2=4,8%2=0
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel),
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
y = torch.clamp(y, 0, 1)
return x * y
文章标题:讲解GoogleNet的Inception从v1到v4的演变
文章链接:http://soscw.com/essay/57669.html