发现了合自己胃口的公众号,但文章太多翻来翻去真麻烦,还好我学了 Python
2021-02-19 21:18
YPE html>
标签:item read 方式 api doc 字符 src with 一个
现在我们大多数人都会或多或少的关注几个公众号,如果发现一个比较合自己胃口的号
对公众号中的文章一定是每篇必读的。
有时候我们关注到宝藏型公众号时发现其历史文章已经好几百甚至上千篇了,而作者又只对其中自己认为比较好的几篇做了索引,我们翻来翻去实在太麻烦了,为了解决这种问题,我决定用 Python 将公众号中文章爬下来。
基本思路
-
爬取公众号文章列表信息,可获取的信息主要包括文章链接、标题等
-
利用 wechatsogou 模块根据文章链接获取文章 html 格式信息
爬取
文章爬取我们采用借助公众平台的方式,这种方式虽然简单,但需要我们自己有一个公众号,如果没有公众号可以自己注册一个,公众号的注册也比较简单,这里就不说了。
首先,登录自己的公众号,然后依次进行如下操作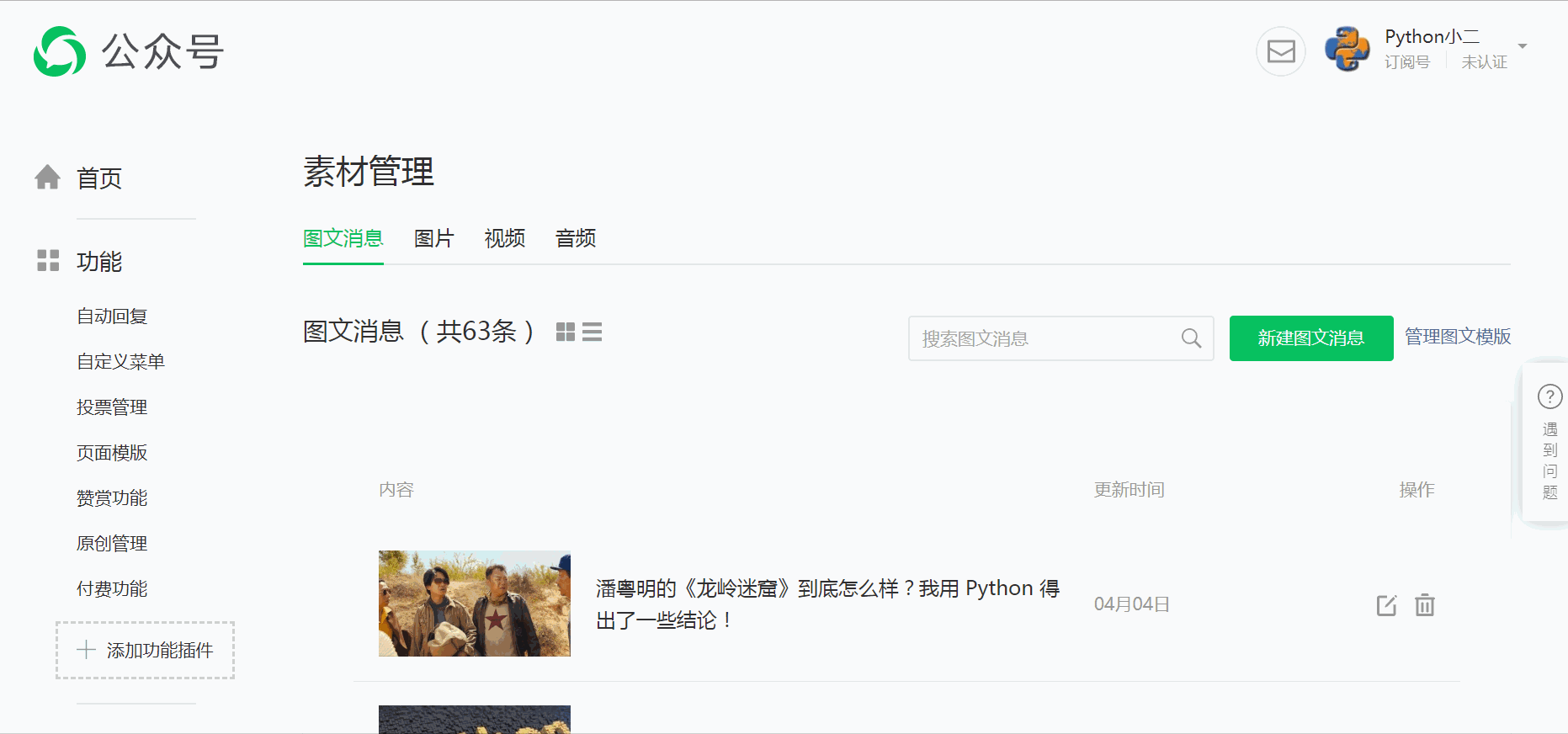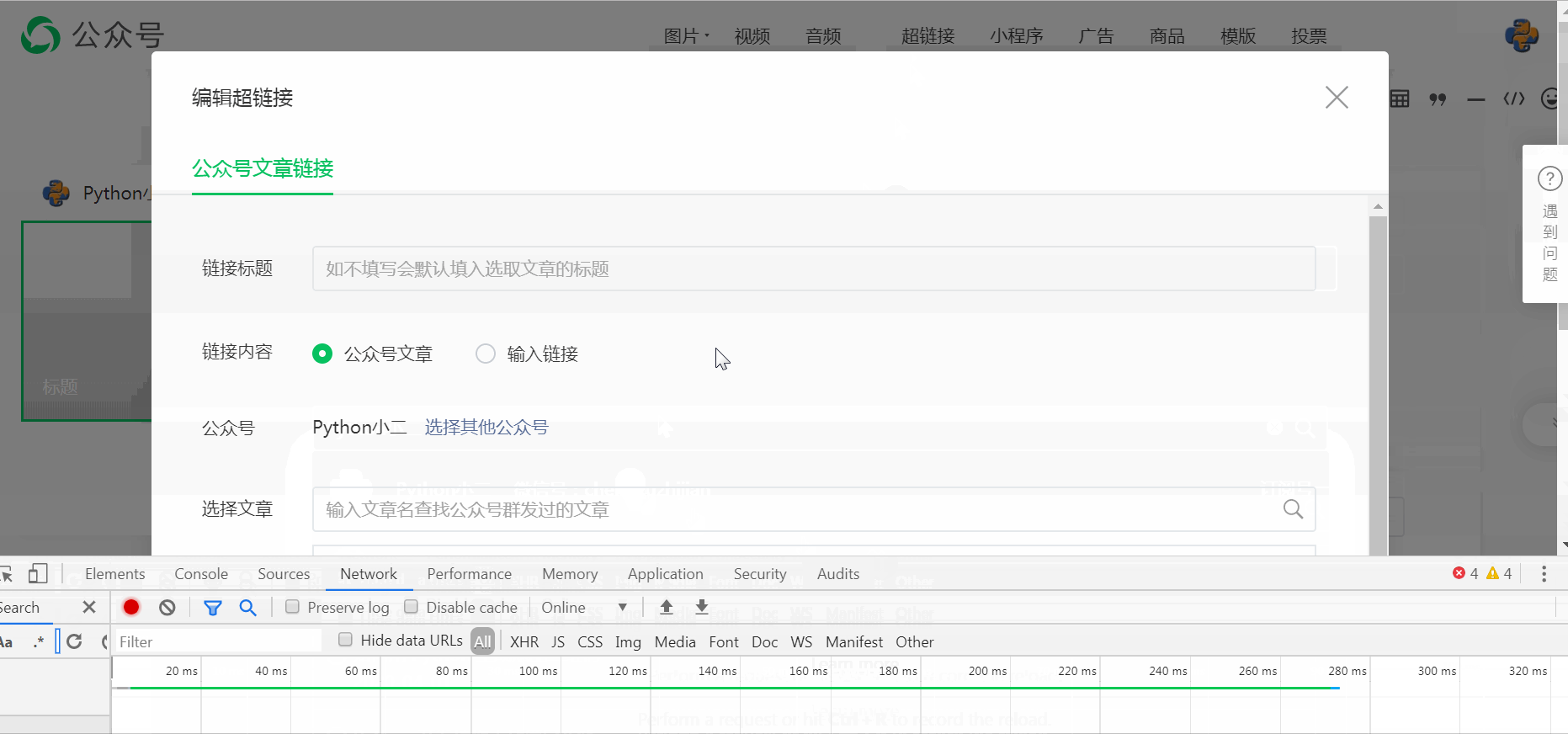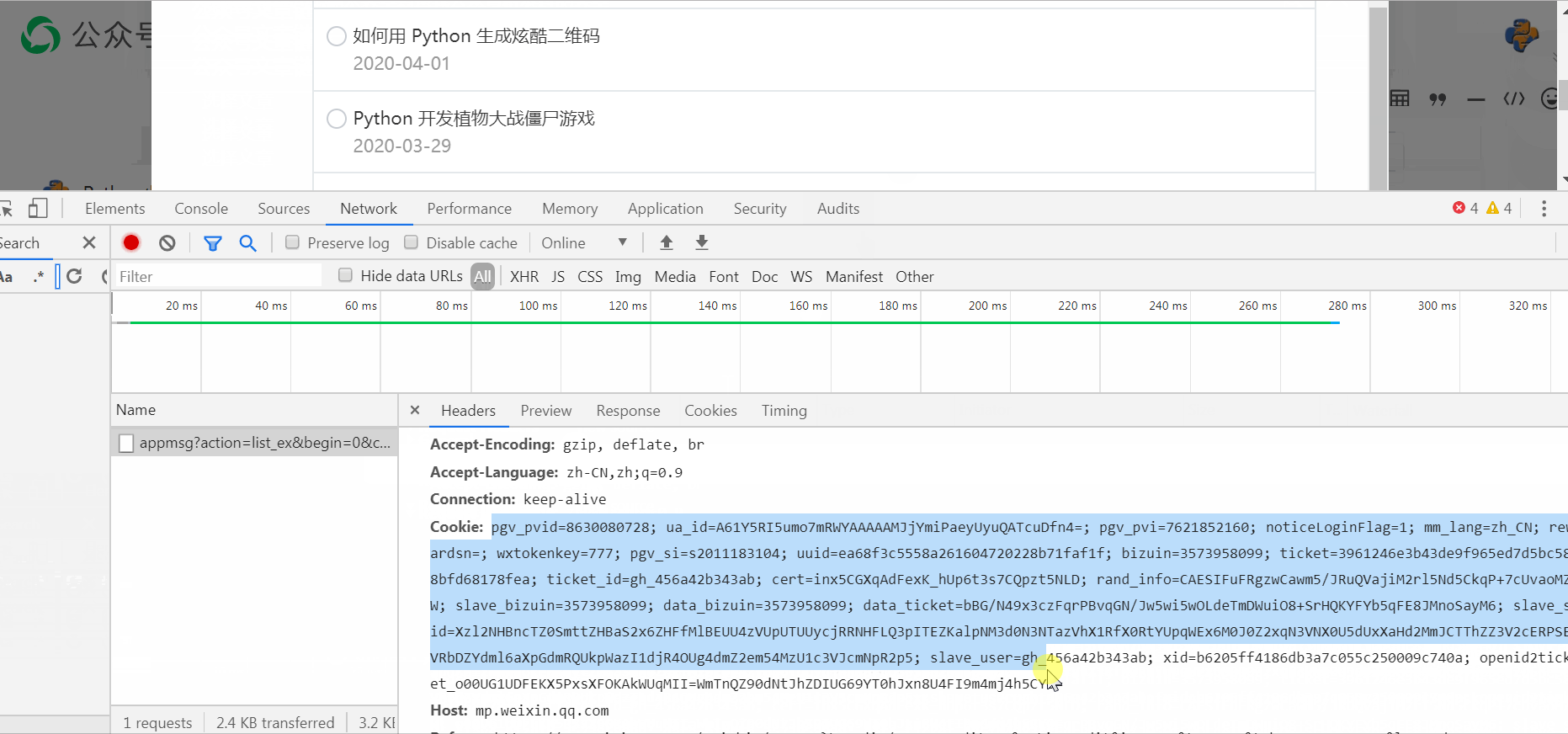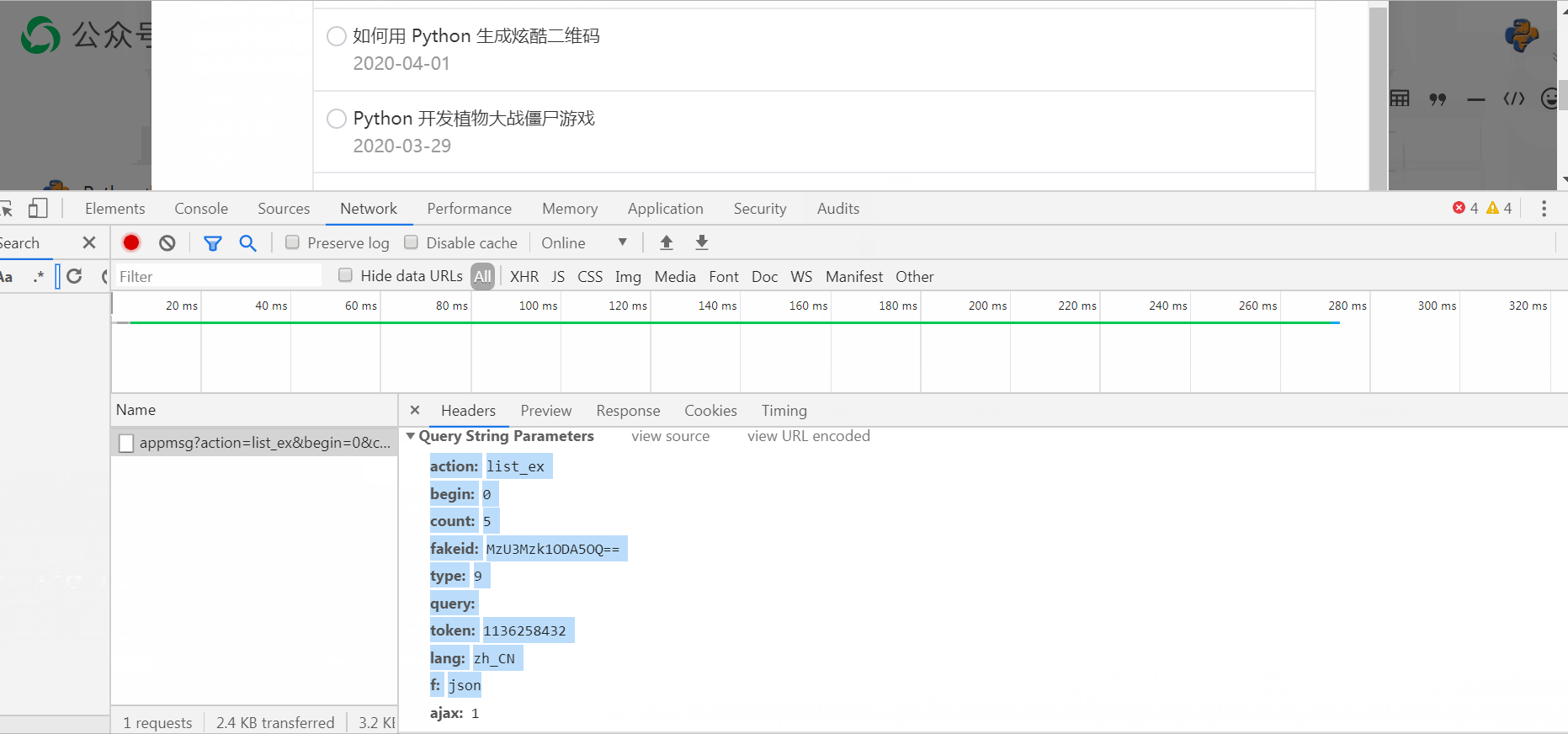
通过上面的操作,我们可以取到 cookie 等信息,我们先将 cookie 写入 txt 文件中,实现代码如下所示:
# 从浏览器中复制出来的 cookie 字符串
cookie_str = "自己的 cookie"
cookie = {}
# 遍历 cookie
for cookies in cookie_str.split("; "):
cookie_item = cookies.split("=")
cookie[cookie_item[0]] = cookie_item[1]
# 将 cookie 写入 txt 文件
with open(‘cookie.txt‘, "w") as file:
file.write(json.dumps(cookie))
接着我们获取公众号文章列表信息,代码实现如下所示:
with open("cookie.txt", "r") as file:
cookie = file.read()
cookies = json.loads(cookie)
url = "https://mp.weixin.qq.com"
response = requests.get(url, cookies=cookies)
# 获取token
token = re.findall(r"token=(\d+)", str(response.url))[0]
# 请求头信息
headers = {
"Referer": "https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&token=" + token + "&lang=zh_CN",
"Host": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
}
# 遍历指定页数的文章
for i in range(1, 5, 1):
begin = (i - 1) * 5
# 获取文章列表
requestUrl = "https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin="+str(begin)+"&count=5&fakeid=要爬取公众号的fakeid&type=9&query=&token=" + token + "&lang=zh_CN&f=json&ajax=1"
search_response = requests.get(requestUrl, cookies=cookies, headers=headers)
# 获取 JSON 格式的列表信息
re_text = search_response.json()
list = re_text.get("app_msg_list")
# 遍历文章列表
for j in list:
# 文章链接
url = j["link"]
# 文章标题
title = j["title"]
print(url)
# 等待 8 秒,避免请求过于频繁
time.sleep(8)
保存
通过文章列表信息我们可以得到公众号文章链接、标题等信息,接着我们就可以通过 wechatsogou 模块根据文章链接获取文章的 html 格式信息了,模块安装使用 pip install wechatsogou 即可。
这里需要注意一下,我们通过 wechatsogou 模块获取的 html 信息会有一些问题,主要的问题有两个,一是获取文章的 html 信息不全,需要我们自己补一下;另一个是获取的 html 信息可能会有一些 CSS 样式没有带过来,这个问题我们可以先通过浏览器的开发者工具取到样式,然后再手动添加一下就行了。代码实现如下所示:
# url:文章链接,title:文章标题
def save2html(url, title):
# captcha_break_time 为验证码输入错误的重试次数,默认为 1
ws_api = wechatsogou.WechatSogouAPI(captcha_break_time = 3)
content_info = ws_api.get_article_content(url)
html = f‘‘‘
{title}
{title}
{content_info[‘content_html‘]}
‘‘‘
with open(title + ‘.html‘, "w", encoding="utf-8") as file:
file.write(‘%s\n‘%html)
上述代码中 my.css 文件存放的就是一些没有带过来的 CSS 样式信息。
用浏览器打开一个公众号文章的 html 文件看一下效果:
通过上面的显示结果,可以看出我们保存的 html 文件的显示效果还算比较好。
如果需要完整代码,微信扫描识别文末二维码,后台回复 200411 即可。
参考:https://mp.weixin.qq.com/s/jGjCfnGdxzK29FgC4E-_Cg
发现了合自己胃口的公众号,但文章太多翻来翻去真麻烦,还好我学了 Python
标签:item read 方式 api doc 字符 src with 一个
原文地址:https://www.cnblogs.com/ityard/p/12682707.html
下一篇:C++之继承
文章标题:发现了合自己胃口的公众号,但文章太多翻来翻去真麻烦,还好我学了 Python
文章链接:http://soscw.com/essay/57693.html