[windows] anaconda 安装 scrapy
2021-03-13 06:29
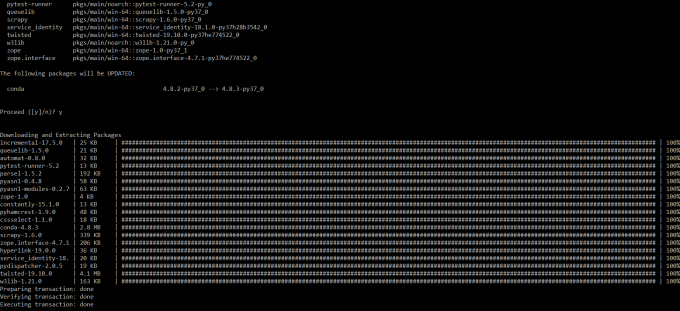
标签:lin cond 记录 checkbox sans 中断 pac pid ctrl 本文记录使用 anaconda 安装 scrapy. https://docs.anaconda.com/anaconda/install/ 我的环境是 windows. 所以安装过程比较简单. 在这里我勾选了两个 checkbox 然后持续点击 next, 直到安装完成. 打开 anaconda cmd 执行 conda install scrapy 此时输入 scarpy 会看到 通常会一次成功,在安装过程中,一定不要中断,否则下次安装因之前的文件不会删除,会提示失败。可能需要执行一次 conda clean --lock scrapy startproject tutorial 然后使用 vs code 打开文件夹 创建爬虫文件, 代码如下 你可能会发现 此处需要为 vs code 指定一个解释器, 来自 Stack Overflow 的解释: Unable to import scrapy package ctrl + shift + p 输入 我选 anaconda 进入顶层folder目录执行 scrapy crawl quotes http://www.scrapyd.cn/doc/124.html https://www.jianshu.com/p/6bc5a4641629 http://docs.scrapy.org/en/latest/intro/install.html https://docs.anaconda.com/anaconda/install/ [windows] anaconda 安装 scrapy 标签:lin cond 记录 checkbox sans 中断 pac pid ctrl 原文地址:https://www.cnblogs.com/it-dennis/p/12554553.html下载和安装 anaconda

安装 scrapy
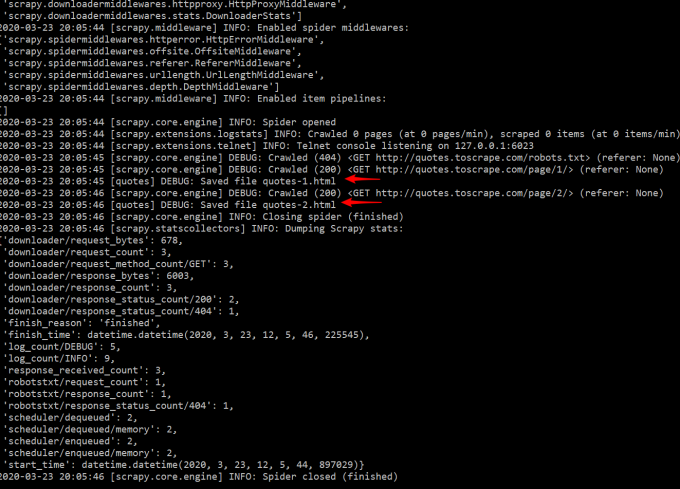
使用 scrapy 创建第一个爬虫项目
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
‘http://quotes.toscrape.com/page/1/‘,
‘http://quotes.toscrape.com/page/2/‘,
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = ‘quotes-%s.html‘ % page
with open(filename, ‘wb‘) as f:
f.write(response.body)
self.log(‘Saved file %s‘ % filename)
import scrapy 报错: Unable to import scrapy package, 解决方案如下:
Python: Select Interpreter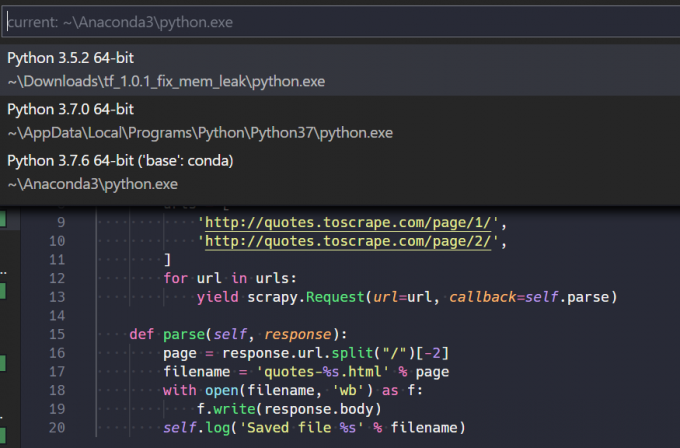
useful links
文章标题:[windows] anaconda 安装 scrapy
文章链接:http://soscw.com/essay/64008.html