java提优-HashMap源码小析(基于JDK1.8)
2021-03-15 07:46
标签:好的 集合 介绍 code val from bit 增加 ESS HashMap是我们日常使用的非常多的java集合框架下的一员, 它是基于哈希表的 Map 接口的实现,以key-value的形式存在。 我们可以通过key快速地存、取value。 本文以基于 JDK1.8 为源码,简单梳理了一下hashMap的源码实现相关知识点。 HashMap实现了Map接口,继承AbstractMap。其中Map接口定义了键映射到值的规则,而AbstractMap类提供 Map 接口的骨干实现,以最大限度地减少实现此接口所需的工作 。 1.HashMap.Node 2.size:集合中存放key-value 的实时对数。 3.loadFactor :装载因子,是用来衡量 HashMap 满的程度,计算HashMap的实时装载因子的方法为:size/capacity,而不是占用桶的数量去除以capacity。capacity 是桶的数量,也就是 table 的长度length。 4.threshold : 计算公式:capacity * loadFactor。这个值是当前已占用数组长度的最大值。过这个数目就重新resize(扩容),扩容后的 HashMap 容量是之前容量的两倍。 HashMap提供了三个构造函数: 1.HashMap():构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap。 2.HashMap(int initialCapacity):构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap。 3.HashMap(int initialCapacity, float loadFactor):构造一个带指定初始容量和加载因子的空 HashMap。 HashMap 是通过散列函数来确定索引的位置的。散列函数设计的好坏,决定了map中元素分布的均匀度。 ? HashMap 是数组+链表+红黑树的组合,我们希望在有限个数组位置时,尽量每个位置的元素只有一个,那么当我们用散列函数求得索引位置的时候,我们能马上知道对应位置的元素是不是我们想要的,而不是要 该函数主要分为三步: ①取 hashCode 值: key.hashCode() ②高位参与运算:h ^ h>>>16 (^:异或,同值取0,异值取1。 ) ③hash值与长度取模运算:(n-1) & hash ? hashCode() 为native 方法,功能是获取对象的hash码,若要让数组均匀分布,需要将计算的hashCode 和数组长度取模,此处用 hash & (table.length -1) 来进行取模运算的。 前面说过 HashMap 底层数组的长度总是2的n次方,这是HashMap在速度上的优化。当 length 总是2的n次方时,hash & (length-1)运算等价于对 length 取模,也就是 hash%length,但是&比%具有更高的效率。比如 n % 32 = n & (32 -1). ? 再就是在 JDK1.8 中还有个高位参与运算,hashCode() 得到的是一个32位 int 类型的值,通过hashCode()的高16位 异或 低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这样让高位的信息也得到了了部分保留。这么做可以在数组table的length比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销。 大体流程: 判断键值对数组 table 是否为空或为null,是则进行执行resize()进行扩容; 计算数组索引 i = (n - 1) & hash, 如果table[i]==null,直接新建节点添加,转向 6,如果table[i]不为空,转向3; 判断table[i]的首个元素是否同 key,如果相同直接覆盖value,否则转向④,这里的 相同指的是hashCode以及equals; 判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向5; 遍历table[i],判断本次插入后的链表长度是否大于 8,大于的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可 插入成功后,判断实际存在的键值对数量size是否超过了最大容量threshold,如果超过,进行扩容。 如果新插入的key不存在,则返回null,如果新插入的key存在,则返回原key对应的value值(注意新插入的value会覆盖原value值) 在 6中,有一步,对size进行判断从而扩容,从代码中可知, 只要是调用put() 方法添加元素,那么就会调用 ++size(这里有个例外是插入重复key的键值对,不会调用,但是重复key元素不会影响size) 上述代码中最后55、62行分别调用了 两个方法,查看源码,得知是两个空方法,有的map实现类会重写这两个空方法,比如 LinkedHashMap 。 ? 通过前文我们了解到,当向Map中插入一个 元素时 ,如果HashMap 集合的元素已经大于了扩容阈值 threshold(capacity * loadFactor), 就会执行 resize() 扩容方法。 ? JDK1.8融入了红黑树的机制, 较为复杂,在此先分析 JDK1.7的扩容源码 JDK1.7 resize() 源码: ? JDK1.7中首先是创建一个新的大容量数组,然后依次重新计算原集合所有元素的索引,然后重新赋值。如果数组某个位置发生了hash冲突,使用的是单链表的头插入方法,同一位置的新元素总是放在链表的头部,这样与原集合链表对比,扩容之后的可能就是倒序的链表了。 下面我们在看看JDK1.8的。 该方法分为两部分,首先是计算新桶数组的容量 newCap 和新阈值 newThr,然后将原集合的元素重新映射到新集合中。 相比于JDK1.7,1.8使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”。 ? HashMap 删除元素首先是要找到 桶的位置,然后如果是链表,则进行链表遍历,找到需要删除的元素后,进行删除;如果是红黑树,也是进行树的遍历,找到元素删除后,进行平衡调节,注意,当红黑树的节点数小于 6 时,会转化成链表。 1.遍历集合 ? 基本上使用第3种方法是性能最好的, 第1种遍历方法在我们只需要 key 集合或者只需要 value 集合时使用; 第2种方法效率很低,不推荐使用; 第4种方法效率也挺好,而且可以再遍历的过程中对集合中的元素进行删除。 HashMap在JDK1.8中采用,数组+链表+红黑树 组成。根据key的索引 ( (n - 1) & hash)判断节点位置,同一节点中的数据非一个时: ? 个数大于 树化阈值(TREEIFY_THRESHOLD ) 8 时,节点内存储结构为红黑树, 当红黑树节点个数小于 6 时,又会转化成链表。 特点: 1.允许 key 和 value 都为 null。key 重复会被覆盖,value 允许重复。 非线程安全 无序(遍历HashMap得到元素的顺序不是按照插入的顺序) 参考文档: https://www.cnblogs.com/ysocean/p/8711071.html java提优-HashMap源码小析(基于JDK1.8) 标签:好的 集合 介绍 code val from bit 增加 ESS 原文地址:https://www.cnblogs.com/jiusixiantan/p/14005707.html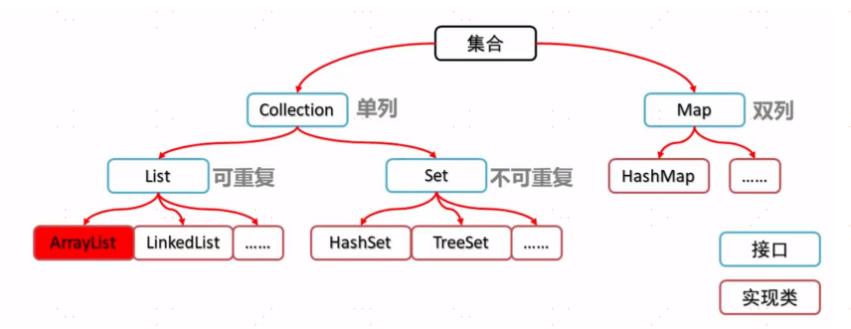
一、类定义

二、类属性成员
//默认初始容量16(必须是 2 的倍数)
static final int DEFAULT_INITIAL_CAPACITY = 1 该值时,才允许树形化链表 (即 将链表 转换成红黑树)
// 否则,若桶内元素太多时,则直接扩容,而不是树形化
// 为了避免进行扩容、树形化选择的冲突,这个值不能小于 4 * TREEIFY_THRESHOLD
static final int MIN_TREEIFY_CAPACITY = 64;
//初始化使用,长度总是 2的幂
transient HashMap.Node
默认的负载因子0.75 是对空间和时间效率的一个平衡选择,建议大家不要修改,除非在时间和空间比较特殊的情况下,如果内存空间很多而又对时间效率要求很高,可以降低负载因子loadFactor 的值;相反,如果内存空间紧张而对时间效率要求不高,可以增加负载因子 loadFactor 的值,这个值可以大于1。三、构造函数
/**
* 默认构造函数,默认 初始容量 (16) ,装载因子 loadFactor = 0.75
*/
public HashMap() {
this.loadFactor = 0.75F;
}
/**
* 构造一个带指定初始容量的空 HashMap
*/
public HashMap(int var1) {
this(var1, 0.75F);
}
/**
* @param initialCapacity:自定义大小,
* @param loadFactor:自定义装载因子
*/
public HashMap(int initialCapacity, float loadFactor) {
//1.初始化容量不能小于 0 ,不然抛出异常
if (initialCapacity MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//3.如果加载因子小于0,或者加载因子是一个非数值,抛出异常
if (loadFactor >> 操作符表示无符号右移,高位补0。
// | 按位或运算 1|0=1; 1|1=1; 0|0=0;
static final int tableSizeFor(int cap) {
int n = cap - 1;
//把最大位的1,通过位移后移一位,并且通过|运算,组合起来
n |= n >>> 1;
//把最大的两位,已经变成1的,往后移动两位,并且通过|运算,组合起来
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
//前面所有的过程,都是保证造成一个所有位都位1的数据。并且通过最后的+1实现最小的二次幂数值。
return (n = MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
四、关键方法介绍
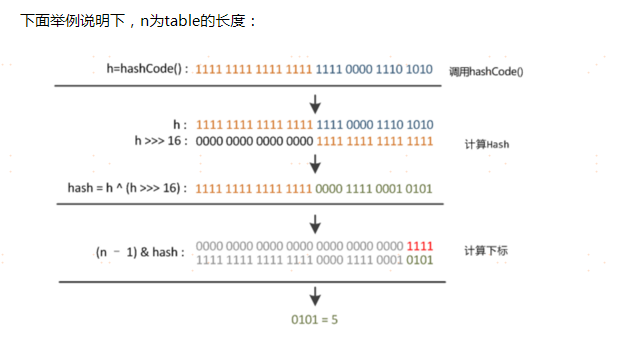
1.hash( ) 算法
进行链表的遍历或者红黑树的遍历,这会大大优化我们的查询效率。HashMap 中的哈希算法://取hash值的函数
static final int hash(Object key) {
int h;
//扰动函数,为了防止取出的hash值碰撞太严重
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
i = (table.length - 1) & hash;//这一步是在后面添加元素putVal()方法中进行位置的确定
2.添加元素 put(k, v)
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
*
* @param hash 索引的位置
* @param key 键
* @param value 值
* @param onlyIfAbsent true 表示不要更改现有值
* @param evict false表示table处于创建模式
* @return
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node

afterNodeAccess(e);
afterNodeInsertion(evict);

3.resize() 扩容方法
//需要扩容成的新数组大小
void resize(int newCapacity) {
//扩容前的老数组
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//扩容前的数组大小如果已经达到最大(2^30)了
if (oldCapacity == MAXIMUM_CAPACITY) {
//修改阈值为int的最大值(2^31-1),这样以后就不会扩容了
threshold = Integer.MAX_VALUE;
return;
}
//新数组
Entry[] newTable = new Entry[newCapacity];
//将数组元素转移到新数组里面
//根据initHashSeedAsNeeded结果判断是否进行rehash
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
//修改阈值为
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry final Node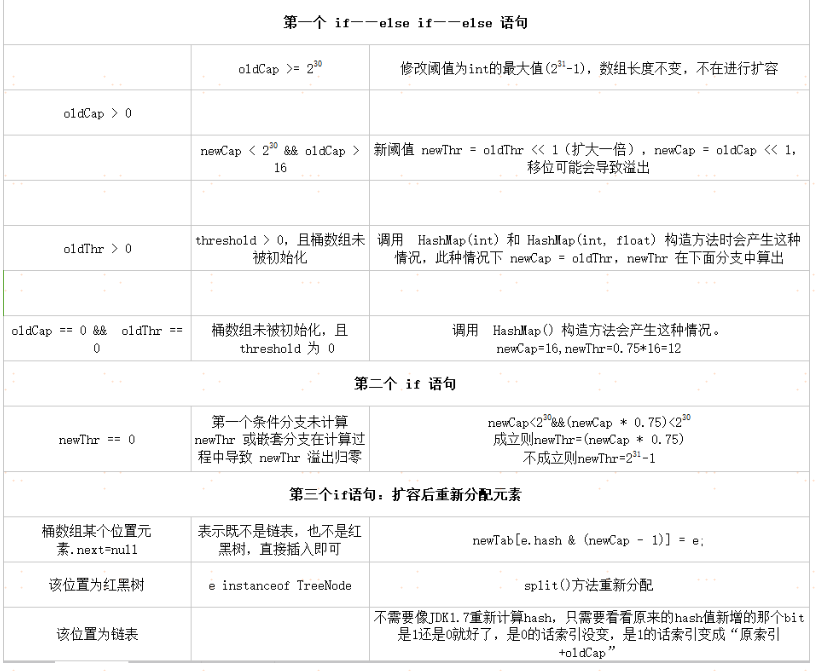
4.remove(Object key) 删除元素
public V remove(Object key) {
Node5.get(Key) 查找元素
首先通过 key 找到计算索引,找到桶位置,先检查第一个节点,如果是则返回,如果不是,则遍历其后面的链表或者红黑树。其余情况全部返回 null。
public V get(Object key) {
Node
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}
}
public boolean containsValue(Object value) {
Node五、集合常见应用
//1、分别获取key和value的集合
for(String key : map.keySet()){
System.out.println(key);
}
for(Object value : map.values()){
System.out.println(value);
}
Set
Set
Iterator总结
文章标题:java提优-HashMap源码小析(基于JDK1.8)
文章链接:http://soscw.com/essay/64868.html