Reuqests-html教程
2021-03-20 04:24
最近爬虫遇到的情况是,爬取的网站使用JavaScript渲染的,网站爬取的结果只有一堆JS代码。之前遇到这种情况的处理办法是用Splash(一般是配合Scrapy),或者Selenium来爬取,介绍一下常用的模拟浏览器执行,来爬去js渲染页面的方法。
| 方法 | 介绍 |
| Selenium | 驱动Chrome、Firefox等浏览器爬取 |
| Splinter | 依赖于Selenium、Flask |
| Spynner | 依赖于PyQt |
| pyppeteer | puppetter的Python版本 |
| Splash | 常与Scrapy配合使用 |
| requests-html | requests作者开发,集成pyppeteer |
安装
pip3 install requests-html
二、基本使用
支持的特性
个人感觉最大的特点就是完整的JavaScrapt支持和异步支持。因为Requests不支持异步,之前使用异步请求的时候使用的是aiohttp(链接)和Python中的协程(链接)配合使用。
- 完整的JavaScript支持
- CSS Selectors 选择
- XPath Selectors
- 模拟用户代理
- 自动跟踪链接重定向
- 链接池和cookie持久特性
- 异步支持
获取页面
非异步
之前解析库都是专门的模块支持,我们需要把网页下载下来,然后传给HTMl解析库,而Requests-html自带这个功能,在爬取页面十分方便。
from requests_html import HTMLSession session = HTMLSession() response = session.get(‘http://news.qq.com/‘) print(response.html.html) # 获取页面内容
异步获取
自带异步请求方法
from requests_html import AsyncHTMLSession asession = AsyncHTMLSession() async def get_qq(): r = await asession.get(‘http://news.qq.com/‘) return r async def get_toutiao(): r = await asession.get(‘https://www.toutiao.com/‘) return r result = asession.run(get_qq, get_toutiao) print(result)
获取链接
links和absolute_links两个属性分别返回HTML对象所包含的所有链接和绝对链接(均不包含锚点):
response.html.links()
response.html.absolute_links()
完整代码:
from requests_html import HTMLSession session = HTMLSession() r = session.get(‘https://python.org/‘) links = r.html.links print("links",links) absolute_links = r.html.absolute_links print("absolute_links",absolute_links)
获取元素
CSS选择器
支持CSS和XPATH两种语法来选取HTML元素。
def find(self, selector: str = "*", *, containing: _Containing = None, clean: bool = False, first: bool = False, _encoding: str = None)
- selector:要用的CSS选择器
- clean:是否清理已发现的
和标签的HTML。 - contaning:返回该属性文本的标签
- first:True 返回第一个元素,否则返回满足条件的元素列表。
- _encoding:编码格式
访问京东,搜索x1关键字的商品列表


from requests_html import HTMLSession session = HTMLSession() r = session.get(‘https://search.jd.com/Search?keyword=x1&enc=utf-8&wq=x1&pvid=add52cb63f7e4887b5ba29406a5756ba‘) link_list = r.html.find(‘.gl-item‘) for i in link_list: print(i.text)
执行输出:
¥9999.00 联想ThinkPad X1 Carbon 2019(01CD)英特尔酷睿i5 14英寸轻薄笔记本电脑(i5-10210U 8G 512GSSD FHD)黑 ...
Xpath选择器
xpath(self, selector: str, *, clean: bool = False, first: bool = False, _encoding: str = None)
- selector:要用的XPATH选择器
- clean:是否清理已发现的
和标签的HTML。 - first:True 返回第一个元素,否则返回满足条件的元素列表。
- _encoding:编码格式
获取新闻列表
from requests_html import HTMLSession session = HTMLSession() r = session.get(‘https://python.org/‘) #里面是css选择器内容 text = r.html.xpath(‘//*[@class="menu"]/li/a/text()‘) print(text)
JavaScript支持
就是在HTML结果上调用一下render函数,它会在用户目录(默认是~/.pyppeteer/)中下载一个chromium,然后用它来执行JS代码。
from requests_html import HTMLSession session = HTMLSession() response = session.get(‘https://www.zhihu.com/topic/19552832/hot‘) response.html.render() # 不调用该方法无法获取标题 print(response.html.xpath(‘//*[@id="root"]/div/main/div/div[1]/div[1]/div[1]/div/div/div/div[2]/h2/div‘))
执行报错:
pyppeteer.errors.PageError: Protocol Error: Connectoin Closed. Most likely the page has been closed.
解决办法,参考链接:
https://github.com/miyakogi/pyppeteer/pull/160/files
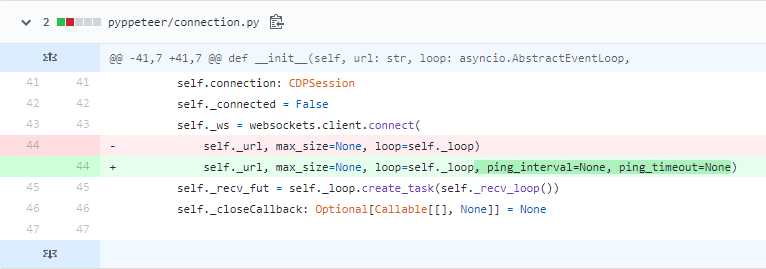
需要修改源代码
你的python安装路径\lib\site-packages\pyppeteer\connection.py
将
self._url, max_size=None, loop=self._loop)
修改为
self._url, max_size=None, loop=self._loop, ping_interval=None, ping_timeout=None)
再次执行,输出:
[‘div‘ class=(‘TopicMetaCard-title‘,)>]
render函数属性
def render(self, retries: int = 8, script: str = None, wait: float = 0.2, scrolldown=False, sleep: int = 0, reload: bool = True, timeout: Union[float, int] = 8.0, keep_page: bool = False):
- retries:加载页面失败的次数
- script:页面上需要执行的JS脚本
- wait:加载页面的等待时间,防止超时
- scrolldown:页面向下滚动的次数
- sleep:在页面渲染之后的等待时间
- reload:Flase页面不会从浏览器中加载,而是从内存中加载
- keep_page:True 允许你用r.html.page访问页面
爬取知乎页面,并且模拟下滑页面。
from requests_html import HTMLSession session = HTMLSession() response = session.get(‘https://www.zhihu.com/topic/19552832/hot‘) response.html.render(scrolldown=4,sleep=5) for name in response.html.xpath("//h2[@class=‘ContentItem-title‘]/a/text()"): print(name)
输出:
如何看待Python和Java?到底入门学习哪一个更好?(附学习教程) 如何看待AI技术?什么是AI?(附教程) Python打包exe的王炸-Nuitka ...
本文参考链接:
https://blog.csdn.net/qq_1290259791/article/details/83413912
https://blog.csdn.net/weixin_39198406/article/details/86719814
https://www.jianshu.com/p/bd828b9cf74d
上一篇:css背景属性
下一篇:css中display属性