Transactions in Apache Kafka
2021-03-20 10:28
In a previous blog post, we introduced exactly once semantics for Apache Kafka®. That post covered the various message delivery semantics, introduced the idempotent producer, transactions, and the exactly once processing semantics for Kafka Streams. We will now pick up from where we left off and dive deeper into transactions in Apache Kafka. The goal of the document is to familiarize the reader with the main concepts needed to use the transaction API in Apache Kafka effectively.
We will discuss the primary use case the transaction API was designed for, Kafka’s transactional semantics, the details of the transaction API for the Java client, interesting aspects of the implementation, and finally, the important considerations to make when using the API.
This blog post isn’t intended to be a tutorial on the specifics of using transactions, and nor will we dive deep into the design nitty gritties. Instead, we will link to the JavaDocs or design docs where appropriate for readers who wish to go deeper.
We expect the reader to be familiar with basic Kafka concepts like topics, partitions, log offsets, and the roles of brokers and clients in a Kafka-based application. Familiarity with the Kafka clients for Java will also help.
Why Transactions?
We designed transactions in Kafka primarily for applications which exhibit a “read-process-write” pattern where the reads and writes are from and to asynchronous data streams such as Kafka topics. Such applications are more popularly known as stream processing applications.
The first generation of stream processing applications could tolerate inaccurate processing. For instance, applications which consumed a stream of web page impressions and produced aggregate counts of views per web page could tolerate some error in the counts.
However, the demand for stream processing applications with stronger semantics has grown along with the popularity of these applications. For instance, some financial institutions use stream processing applications to process debits and credits on user accounts. In these situations, there is no tolerance for errors in processing: we need every message to be processed exactly once, without exception.
More formally, if a stream processing application consumes message A and produces message B such that B = F(A), then exactly once processing means that A is considered consumed if and only if B is successfully produced, and vice versa.
Using vanilla Kafka producers and consumers configured for at-least-once delivery semantics, a stream processing application could lose exactly once processing semantics in the following ways:
- The producer.send() could result in duplicate writes of message B due to internal retries. This is addressed by the idempotent producer and is not the focus of the rest of this post.
- We may reprocess the input message A, resulting in duplicate B messages being written to the output, violating the exactly once processing semantics. Reprocessing may happen if the stream processing application crashes after writing B but before marking A as consumed. Thus when it resumes, it will consume A again and write B again, causing a duplicate.
- Finally, in distributed environments, applications will crash or—worse!—temporarily lose connectivity to the rest of the system. Typically, new instances are automatically started to replace the ones which were deemed lost. Through this process, we may have multiple instances processing the same input topics and writing to the same output topics, causing duplicate outputs and violating the exactly once processing semantics. We call this the problem of “zombie instances.”
We designed transaction APIs in Kafka to solve the second and third problems. Transactions enable exactly-once processing in read-process-write cycles by making these cycles atomic and by facilitating zombie fencing.
Transactional Semantics
Atomic multi-partition writes
Transactions enable atomic writes to multiple Kafka topics and partitions. All of the messages included in the transaction will be successfully written or none of them will be. For example, an error during processing can cause a transaction to be aborted, in which case none of the messages from the transaction will be readable by consumers. We will now look at how this enables atomic read-process-write cycles.
First, let’s consider what an atomic read-process-write cycle means. In a nutshell, it means that if an application consumes a message A at offset X of some topic-partition tp0, and writes message B to topic-partition tp1 after doing some processing on message A such that B = F(A), then the read-process-write cycle is atomic only if messages A and B are considered successfully consumed and published together, or not at all.
Now, the message A will be considered consumed from topic-partition tp0 only when its offset X is marked as consumed. Marking an offset as consumed is called committing an offset. In Kafka, we record offset commits by writing to an internal Kafka topic called the offsets topic. A message is considered consumed only when its offset is committed to the offsets topic.
Thus since an offset commit is just another write to a Kafka topic, and since a message is considered consumed only when its offset is committed, atomic writes across multiple topics and partitions also enable atomic read-process-write cycles: the commit of the offset X to the offsets topic and the write of message B to tp1 will be part of a single transaction, and hence atomic.
Zombie fencing
We solve the problem of zombie instances by requiring that each transactional producer be assigned a unique identifier called the transactional.id. This is used to identify the same producer instance across process restarts.
The API requires that the first operation of a transactional producer should be to explicitly register its transactional.id with the Kafka cluster. When it does so, the Kafka broker checks for open transactions with the given transactional.id and completes them. It also increments an epoch associated with the transactional.id. The epoch is an internal piece of metadata stored for every transactional.id.
Once the epoch is bumped, any producers with same transactional.id and an older epoch are considered zombies and are fenced off, ie. future transactional writes from those producers are rejected.
Reading Transactional Messages
Now, let’s turn our attention to the guarantees provided when reading messages written as part of a transaction.
The Kafka consumer will only deliver transactional messages to the application if the transaction was actually committed. Put another way, the consumer will not deliver transactional messages which are part of an open transaction, and nor will it deliver messages which are part of an aborted transaction.
It is worth noting that the guarantees above fall short of atomic reads. In particular, when using a Kafka consumer to consume messages from a topic, an application will not know whether these messages were written as part of a transaction, and so they do not know when transactions start or end. Further, a given consumer is not guaranteed to be subscribed to all partitions which are part of a transaction, and it has no way to discover this, making it tough to guarantee that all the messages which were part of a single transaction will eventually be consumed by a single consumer.
In short: Kafka guarantees that a consumer will eventually deliver only non-transactional messages or committed transactional messages. It will withhold messages from open transactions and filter out messages from aborted transactions.
The Transaction API in Java
The transaction feature is primarily a server-side and protocol level feature which is available for use by any client library that supports it. A ‘read-process-write’ application written in Java which uses Kafka’s transaction API would look something like this:
Lines 1-5 set up the producer by specifying the transactional.id configuration and registering it with the initTransactions API. After the producer.initTransactions() returns, any transactions started by another instance of a producer with the same transactional.id would have been closed and fenced off.
Line 7-10 specifies that the KafkaConsumer should only read non-transactional messages, or committed transactional messages from its input topics. Stream processing applications typically process their data in multiple read-process-write stages, with each stage using the outputs of the previous stage as its input. By specifying the read_committed mode, we can get exactly once processing across all the stages.
Lines 14-21 demonstrate the core of the read-process-write loop: we consume some records, start a transaction, process the consumed records, write the processed records to the output topic, send the consumed offsets to the offsets topic, and finally commit the transaction. With the guarantees mentioned above, we know that the offsets and the output records will be committed as an atomic unit.
How Transactions Work
In this section, we present a brief overview of the new components and new data flows introduced by the transaction APIs introduced above. For a more exhaustive treatment of this subject, you may read the original design document, or watch the Kafka summit talk where transactions were introduced.
The goal of the content below is to give a mental model when debugging applications which use transactions, or when trying to tune transactions for better performance.
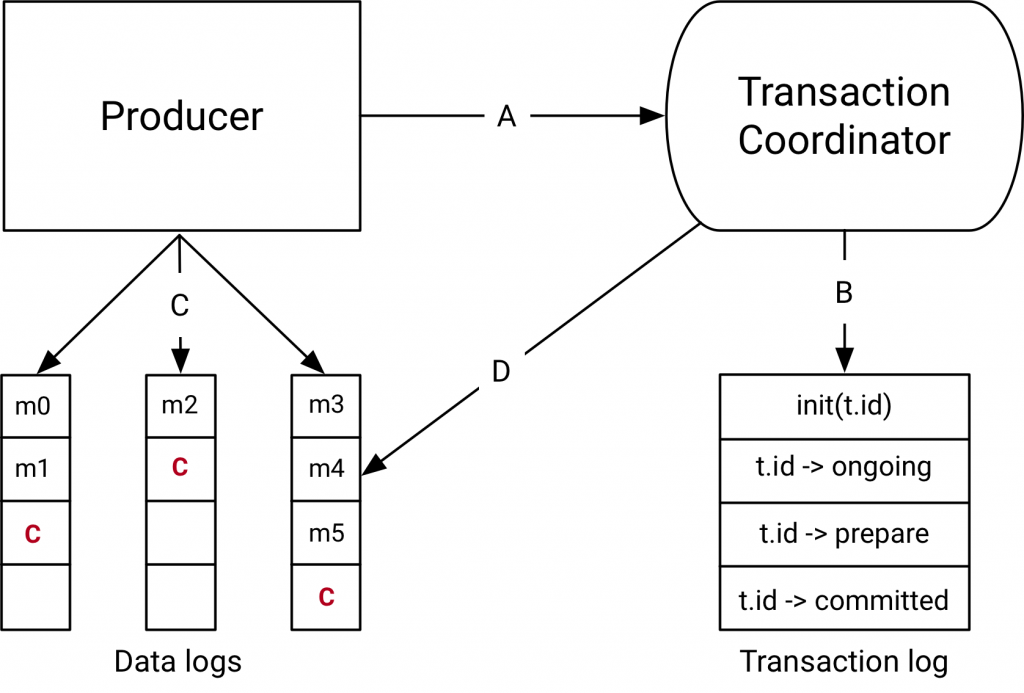
The Transaction Coordinator and Transaction Log
The components introduced with the transactions API in Kafka 0.11.0 are the Transaction Coordinator and the Transaction Log on the right hand side of the diagram above.
The transaction coordinator is a module running inside every Kafka broker. The transaction log is an internal kafka topic. Each coordinator owns some subset of the partitions in the transaction log, ie. the partitions for which its broker is the leader.
Every transactional.id is mapped to a specific partition of the transaction log through a simple hashing function. This means that exactly one coordinator owns a given transactional.id.
This way, we leverage Kafka’s rock solid replication protocol and leader election processes to ensure that the transaction coordinator is always available and all transaction state is stored durably.
It is worth noting that the transaction log just stores the latest state of a transaction and not the actual messages in the transaction. The messages are stored solely in the actual topic-partitions. The transaction could be in various states like “Ongoing,” “Prepare commit,” and “Completed.” It is this state and associated metadata that is stored in the transaction log.
Data flow
At a high level, the data flow can be broken into four distinct types.
A: the producer and transaction coordinator interaction
When executing transactions, the producer makes requests to the transaction coordinator at the following points:
- The initTransactions API registers a transactional.id with the coordinator. At this point, the coordinator closes any pending transactions with that transactional.id and bumps the epoch to fence out zombies. This happens only once per producer session.
- When the producer is about to send data to a partition for the first time in a transaction, the partition is registered with the coordinator first.
- When the application calls commitTransaction or abortTransaction, a request is sent to the coordinator to begin the two phase commit protocol.
B: the coordinator and transaction log interaction
As the transaction progresses, the producer sends the requests above to update the state of the transaction on the coordinator. The transaction coordinator keeps the state of each transaction it owns in memory, and also writes that state to the transaction log (which is replicated three ways and hence is durable).
The transaction coordinator is the only component to read and write from the transaction log. If a given broker fails, a new coordinator is elected as the leader for the transaction log partitions the dead broker owned, and it reads the messages from the incoming partitions to rebuild its in-memory state for the transactions in those partitions.
C: the producer writing data to target topic-partitions
After registering new partitions in a transaction with the coordinator, the producer sends data to the actual partitions as normal. This is exactly the same producer.send flow, but with some extra validation to ensure that the producer isn’t fenced.
D: the coordinator to topic-partition interaction
After the producer initiates a commit (or an abort), the coordinator begins the two phase commit protocol.
In the first phase, the coordinator updates its internal state to “prepare_commit” and updates this state in the transaction log. Once this is done the transaction is guaranteed to be committed no matter what.
The coordinator then begins phase 2, where it writes transaction commit markers to the topic-partitions which are part of the transaction.
These transaction markers are not exposed to applications, but are used by consumers in read_committed mode to filter out messages from aborted transactions and to not return messages which are part of open transactions (i.e., those which are in the log but don’t have a transaction marker associated with them).
Once the markers are written, the transaction coordinator marks the transaction as “complete” and the producer can start the next transaction.
Transactions in Practice
Now that we have understood the semantics of transactions and how they work, we turn our attention to the practical aspects of writing applications which leverage transactions.
How to pick a transactional.id
The transactional.id plays a major role in fencing out zombies. But maintaining an identifier that is consistent across producer sessions and also fences out zombies properly is a bit tricky.
The key to fencing out zombies properly is to ensure that the input topics and partitions in the read-process-write cycle is always the same for a given transactional.id. If this isn’t true, then it is possible for some messages to leak through the fencing provided by transactions.
For instance, in a distributed stream processing application, suppose topic-partition tp0 was originally processed by transactional.id T0. If, at some point later, it could be mapped to another producer with transactional.id T1, there would be no fencing between T0 and T1. So it is possible for messages from tp0 to be reprocessed, violating the exactly once processing guarantee.
Practically, one would either have to store the mapping between input partitions and transactional.ids in an external store, or have some static encoding of it. Kafka Streams opts for the latter approach to solve this problem.
How transactions perform, and how to tune them
Performance of the transactional producer
Let’s turn our attention to how transactions perform.
First, transactions cause only moderate write amplification. The additional writes are due to:
- For each transaction, we have had additional RPCs to register the partitions with the coordinator. These are batched, so we have fewer RPCs than there are partitions in the transaction.
- When completing a transaction, one transaction marker has to be written to each partition participating in the transaction. Again, the transaction coordinator batches all markers bound for the same broker in a single RPC, so we save the RPC overhead there. But we cannot avoid one additional write to each partition in the transaction.
- Finally, we write state changes to the transaction log. This includes a write for each batch of partitions added to the transaction, the “prepare_commit” state, and the “complete_commit” state.
As we can see the overhead is independent of the number of messages written as part of a transaction. So the key to having higher throughput is to include a larger number of messages per transaction.
In practice, for a producer producing 1KB records at maximum throughput, committing messages every 100ms results in only a 3% degradation in throughput. Smaller messages or shorter transaction commit intervals would result in more severe degradation.
The main tradeoff when increasing the transaction duration is that it increases end-to-end latency. Recall that a consumer reading transactional messages will not deliver messages which are part of open transactions. So the longer the interval between commits, the longer consuming applications will have to wait, increasing the end-to-end latency.
Performance of the transactional consumer
The transactional consumer is much simpler than the producer, since all it needs to do is:
- Filter out messages belonging to aborted transactions.
- Not return transactional messages which are part of open transactions.
As such, the transactional consumer shows no degradation in throughput when reading transactional messages in read_committed mode. The main reason for this is that we preserve zero copy reads when reading transactional messages.
Further, the consumer does not need to any buffering to wait for transactions to complete. Instead, the broker does not allow it to advance to offsets which include open transactions.
Thus the consumer is extremely lightweight and efficient. The interested reader may learn about the details of the consumer design in this document.
Further reading
We have just scratched the surface of transactions in Apache Kafka. Luckily, nearly all the details of the design are documented online. The relevant documents are:
- The original Kafka KIP: This provides good details on the data flow and a great overview of the public interfaces, particularly the configuration options that come along with transactions.
- The original design document: Not for the faint of heart, this is the definitive place—outside of the source code!—to learn about how each transactional RPC is processed, how the transaction log is maintained, how transactional data is purged, etc.
- The KafkaProducer javadocs: This is a great place to learn about how to use the new APIs. The example at the beginning of the page as well as the documentation of the send method are good starting points.
Conclusion
In this post, we learned about the key design goals for the transaction APIs in Apache Kafka, we understood the semantics of the transaction API, and got a high level idea of how the APIs actually work.
If we consider a read-process-write cycle, this post mainly covered the read and write paths, with the processing itself being a black box. The truth is that there is a lot that can be done in the processing stage which makes exactly once processing impossible to guarantee using the transaction APIs alone. For instance, if the processing has side effects on other storage systems, the APIs covered here are not sufficient to guarantee exactly once processing.
The Kafka Streams framework uses the transaction APIs described here to move up the value chain and provide exactly once processing for a wide variety of stream processing applications, even those which update certain additional state stores during processing.
A future blog post will cover how Kafka Streams provides exactly once processing semantics, and how to write applications which leverage it.
Finally, for those hungry for details about the implementation of the APIs above, we will have another follow up blog post that covers some of the more interesting solutions underlying the transaction APIs described here.
Interested in More?
If you’d like to know more, here are some resources for you:
- You can download the Confluent Platform
- Read our documentation
- Confluent Professional Services offers advice and help with deployments
- Confluent Training can get your team ready for development and deployment of the Confluent Platform
上一篇:爬取视频网站视频并下载
下一篇:PHP开发中使用的工具
文章标题:Transactions in Apache Kafka
文章链接:http://soscw.com/essay/66666.html