3分钟Python爬取9000张表情包图片
2021-03-26 06:27
阅读:915
YPE html PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN" "http://www.w3.org/TR/REC-html40/loose.dtd">
标签:back 截断 pen port 针对 content put width 如何
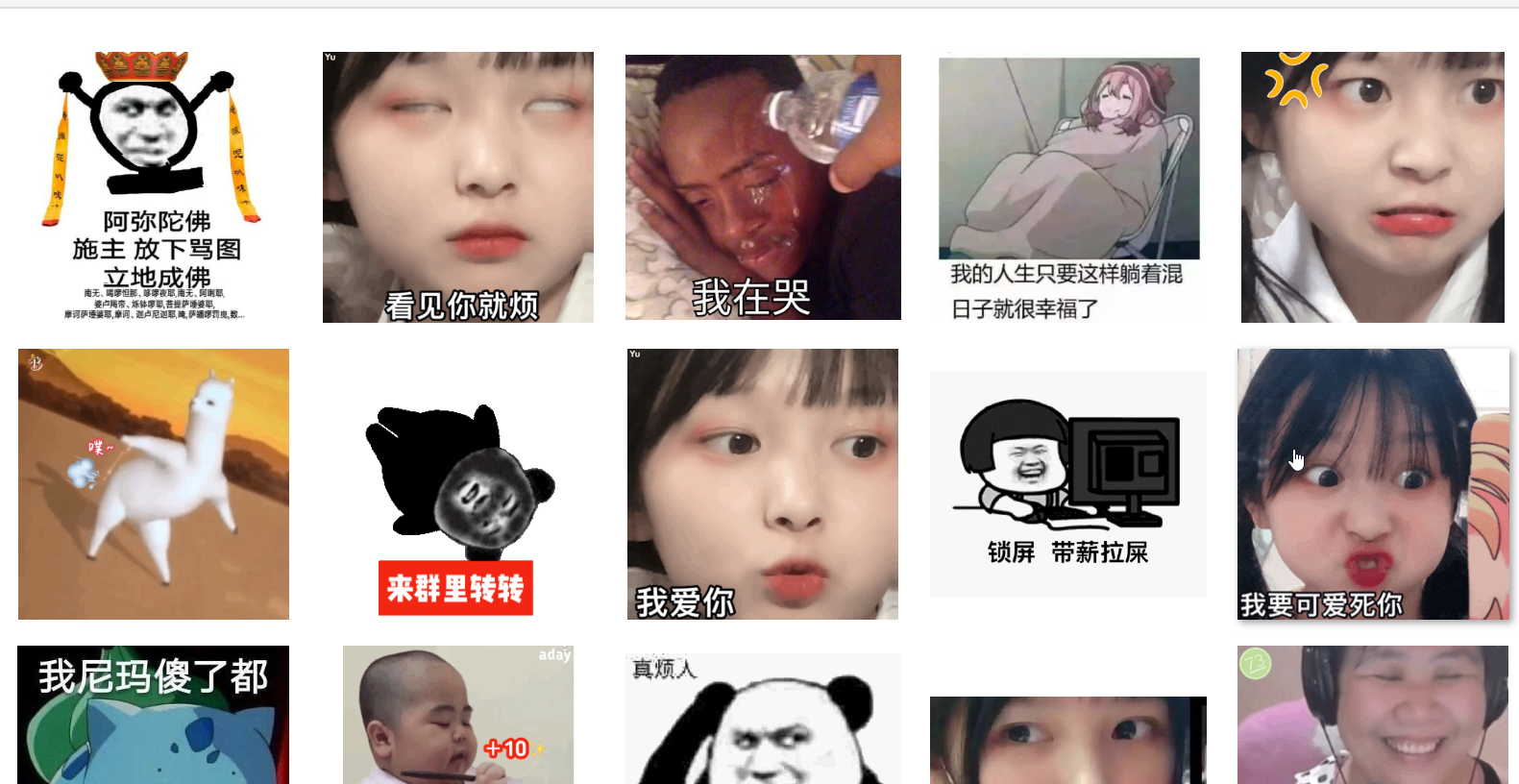
先看下我的爬取成果:
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:961562169
本视频的演示步骤:
- 使用requests爬取200个网页
- 使用BeautifulSoup实现图片的标题和地址解析
- 将图片下载到本地目录
这2个库的详细用法,请看我的其他视频课程
import requests
from bs4 import BeautifulSoup
import re
1、下载共200个页面的HTML
def download_all_htmls():
"""
下载所有列表页面的HTML,用于后续的分析
"""
htmls = []
for idx in range(200):
url = f"https://fabiaoqing.com/biaoqing/lists/page/{idx+1}.html"
print("craw html:", url)
r = requests.get(url)
if r.status_code != 200:
raise Exception("error")
htmls.append(r.text)
print("success")
return htmls
# 执行爬取
htmls = download_all_htmls()
craw html: https://fabiaoqing.com/biaoqing/lists/page/1.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/2.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/3.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/4.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/188.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/189.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/190.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/191.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/192.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/193.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/194.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/195.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/196.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/197.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/198.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/199.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/200.html
success
htmls[0][:1000]
‘\n\n\n \n \n \n\n 热门表情_发表情,表情包大全fabiaoqing.com \n \n \n \n \n \n \n import pprint
pprint.pprint(parse_single_html(htmls[0])[:10])
[(‘阿弥陀佛,施主放下骂图,立地成佛!‘,
‘http://ww2.sinaimg.cn/bmiddle/9150e4e5gy1g6qlfb10avj20d70f7gmf.jpg‘),
(‘看见你就烦(草莓果酱ox白眼 GIF 动图表情包)‘,
‘http://wx1.sinaimg.cn/bmiddle/006APoFYly1g68tiftpbmg30bh0bh4o5.gif‘),
(‘我在哭‘, ‘http://wx3.sinaimg.cn/bmiddle/006qir4ogy1g54eoes2q2j309q09cdgh.jpg‘),
(‘我的人生只要这样躺着混日子就很幸福了‘,
‘http://ww4.sinaimg.cn/bmiddle/9150e4e5gy1g6qm7x6fiuj20mw0mmt9y.jpg‘),
(‘草莓果酱ox动图表情包‘,
‘http://wx1.sinaimg.cn/bmiddle/ceeb653ely1g64664qyc0g20bf0br4jn.gif‘),
(‘噗呲 放屁(沙雕羊驼动图表情包)‘,
‘http://wx1.sinaimg.cn/bmiddle/78b88159gy1g69cze2hkkg20bp0bpx0y.gif‘),
(‘来群里转转(熊猫头旋转 GIF 动图)‘,
‘http://wx1.sinaimg.cn/bmiddle/ceeb653ely1g68tzab8xng207608wwou.gif‘),
(‘我爱你(草莓果酱oxGIF 动图表情包)‘,
‘http://wx2.sinaimg.cn/bmiddle/006APoFYly1g68uwg8djlg30b60b6e57.gif‘),
(‘锁屏 带薪拉屎‘,
‘http://wx3.sinaimg.cn/bmiddle/ceeb653ely1g654hwdsjkg20dc0avgm4.gif‘),
(‘我要可爱死你(草莓果酱ox表情包)‘,
‘http://wx2.sinaimg.cn/bmiddle/bf976b12gy1g68hx2gtleg208c08bk8q.gif‘)]
# 执行所有的HTML页面的解析
all_imgs = []
for html in htmls:
all_imgs.extend(parse_single_html(html))
all_imgs[:10]
[(‘阿弥陀佛,施主放下骂图,立地成佛!‘,
‘http://ww2.sinaimg.cn/bmiddle/9150e4e5gy1g6qlfb10avj20d70f7gmf.jpg‘),
(‘看见你就烦(草莓果酱ox白眼 GIF 动图表情包)‘,
‘http://wx1.sinaimg.cn/bmiddle/006APoFYly1g68tiftpbmg30bh0bh4o5.gif‘),
(‘我在哭‘, ‘http://wx3.sinaimg.cn/bmiddle/006qir4ogy1g54eoes2q2j309q09cdgh.jpg‘),
(‘我的人生只要这样躺着混日子就很幸福了‘,
‘http://ww4.sinaimg.cn/bmiddle/9150e4e5gy1g6qm7x6fiuj20mw0mmt9y.jpg‘),
(‘草莓果酱ox动图表情包‘,
‘http://wx1.sinaimg.cn/bmiddle/ceeb653ely1g64664qyc0g20bf0br4jn.gif‘),
(‘噗呲 放屁(沙雕羊驼动图表情包)‘,
‘http://wx1.sinaimg.cn/bmiddle/78b88159gy1g69cze2hkkg20bp0bpx0y.gif‘),
(‘来群里转转(熊猫头旋转 GIF 动图)‘,
‘http://wx1.sinaimg.cn/bmiddle/ceeb653ely1g68tzab8xng207608wwou.gif‘),
(‘我爱你(草莓果酱oxGIF 动图表情包)‘,
‘http://wx2.sinaimg.cn/bmiddle/006APoFYly1g68uwg8djlg30b60b6e57.gif‘),
(‘锁屏 带薪拉屎‘,
‘http://wx3.sinaimg.cn/bmiddle/ceeb653ely1g654hwdsjkg20dc0avgm4.gif‘),
(‘我要可爱死你(草莓果酱ox表情包)‘,
‘http://wx2.sinaimg.cn/bmiddle/bf976b12gy1g68hx2gtleg208c08bk8q.gif‘)]
len(all_imgs)
8999
3、下载图片到本地目录
for idx, (title, img_url) in enumerate(all_imgs):
# 移除标点符号,只保留中文、大小写字母和阿拉伯数字
reg = "[^0-9A-Za-z\u4e00-\u9fa5]"
title = re.sub(reg, ‘‘, title)
# 发现了超长的图片标题,做截断
if len(title)>10: title = title[:10]
# 得到jpg还是gif后缀
post_fix = img_url[-3:]
filename = f"./output/{title}.{post_fix}"
print(idx, filename)
img_data = requests.get(img_url)
with open(filename,"wb")as f:
f.write(img_data.content)
print("success")
0 ./output/阿弥陀佛施主放下骂图.jpg
1 ./output/看见你就烦草莓果酱o.gif
2 ./output/我在哭.jpg
3 ./output/我的人生只要这样躺着.jpg
4 ./output/草莓果酱ox动图表情.gif
5 ./output/噗呲放屁沙雕羊驼动图.gif
6 ./output/来群里转转熊猫头旋转.gif
7 ./output/我爱你草莓果酱oxG.gif
8 ./output/锁屏带薪拉屎.gif
9 ./output/我要可爱死你草莓果酱.gif
10 ./output/我尼玛傻了都.jpg
11 ./output/你今天表现蛮好10分.gif
12 ./output/真烦人得找个理由做她.gif
13 ./output/哇哦草莓果酱ox表情.jpg
14 ./output/哥哥又说笑了乔碧萝表.gif
15 ./output/锁屏带薪拉屎.gif
16 ./output/我简直难上加难麻将表.jpg3分钟Python爬取9000张表情包图片
标签:back 截断 pen port 针对 content put width 如何
原文地址:https://www.cnblogs.com/41280a/p/13714877.html
上一篇:java入门罗技代数
下一篇:C++primer 第三章
评论
亲,登录后才可以留言!