python-爬虫学习1:爬虫原理(纯理论篇)
2021-03-27 06:25
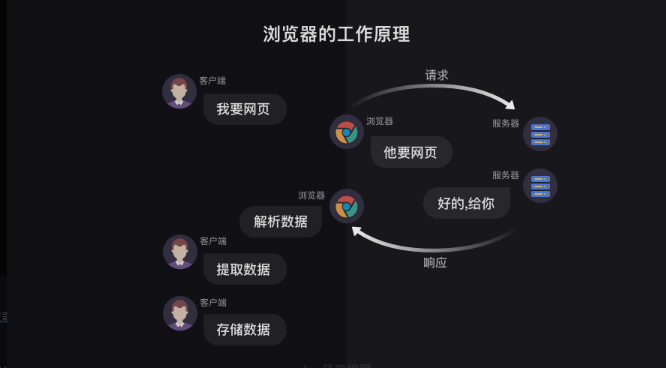
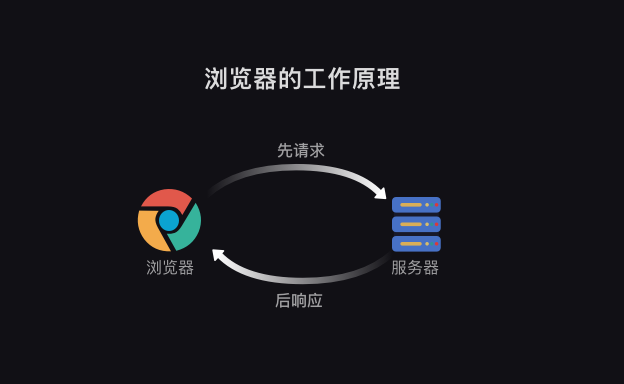
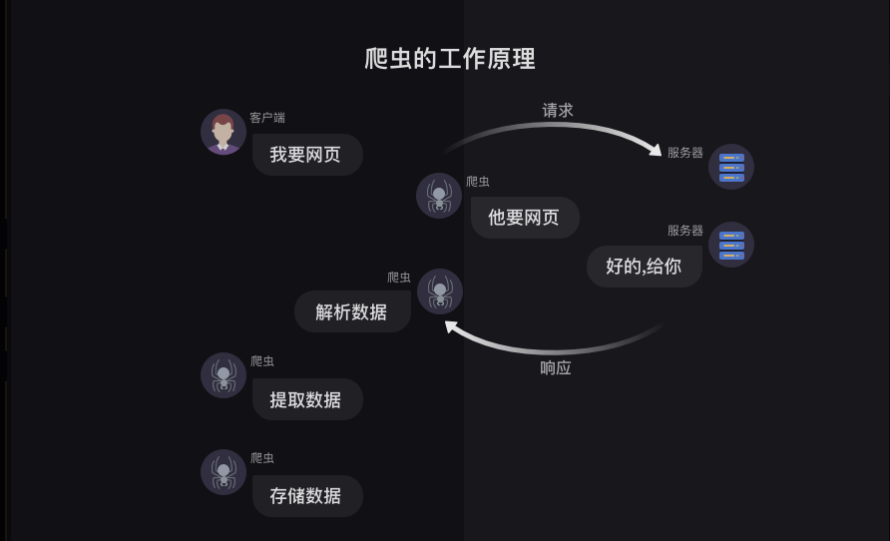
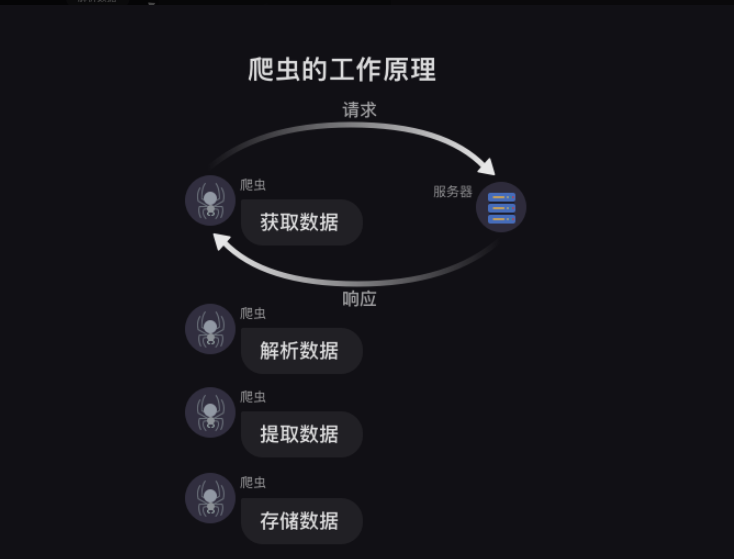
标签:语言 nbsp 存储 使用 pytho lazy 数据操作 返回 搜索 简单说的话,爬虫就像一个虚拟的虫子,然后利用这只虫子,我们可以在网上获取到我们想要的信息。 浏览器工作原理 一般情况下,我们获取数据都是打开浏览器,然后搜索关键字,浏览器去工作,然后显示出来我们要的数据,我们再进行复制粘贴或者其他操作。 类似于下图 这里的客户端是我们,然后我们打开浏览器搜索关键字,相当于告诉浏览器我需要xx网页,浏览器就去给服务端说,他需要xx网页,服务端收到请求之后就会告诉浏览器网页给你(就像打招呼,同事给你打招呼,你肯定会回应嘛),浏览器会对网页进行解析,转化成客户端看的懂的界面返回出来,然后我们就可以看到查找的网页,然后我们就可以对网页进行数据操作啦。 这里有两个概念要知道的,请求和响应。 请求:我们在浏览器输入了网址,然后浏览器告诉服务器,我们要访问某个网址的请求,这个过程就叫做请求。 响应:服务器把我们想要的网址数据发送给浏览器,这个过程就叫做响应。(所以一般就是先请求后响应) 服务器把请求返回给了浏览器之后,浏览器不会把数据直接给我们,为什么呢,因为这些数据都是用计算机语言写的,浏览器需要把它翻译成我们看得懂的样子,这个过程就叫做解析数据 然后我们在数据中挑出来对我们有用的数据,这个 过程就是提取数据 最后我们对这些数据进行存储复制操作,这个过程就是存储数据 这就是浏览器工作的整个流程了。 爬虫工作原理 先看一下原理图 爬虫可以执行的部分: 首先,模拟浏览器去向服务器发出请求; 其次,等服务响应后,爬虫程序可以代替浏览器解析数据; 接着,爬虫可以根据设定的规则批量提取相关数据,不需要我们手动去执行, 最后,爬虫可以批量把数据存储到本地。 总结完的话就是这四步骤: 这就是爬虫的整个过程啦 大致理解之后就可以开始敲代码咯 python-爬虫学习1:爬虫原理(纯理论篇) 标签:语言 nbsp 存储 使用 pytho lazy 数据操作 返回 搜索 原文地址:https://www.cnblogs.com/Sagittarius23/p/13671645.html一、爬虫定义
二、爬虫的工作原理
上一篇:python多态与抽象类
下一篇:springmvc入门