【BOOK】数据存储—文件存储(TXT、JSON、CSV)
2021-03-31 19:28
标签:字符 end zh-cn 结构 ade 文件的读写操作 header uid name 数据存储 文本文件—TXT、JSON、CSV 关系型数据库—MySQL、SQLite、Oracle、SQL Server、DB2 非关系型数据库—MongoDB、Redis 文件打开 open(),第二个参数设置文件打开方式 ※ r:只读,文件指针在文件开头 ※ rb:二进制只读,文件指针在文件开头 ※ r+:读写方式,文件指针在文件开头 ※ w:写入,如果文件已存在,则覆盖;若文件不存在,则新建 ※ wb:二进制写入,如果文件已存在,则覆盖;若文件不存在,则新建 ※ w+:读写,如果文件已存在,则覆盖;若文件不存在,则新建 ※ a:追加方式,如果文件已存在,将内容新增再最后;若文件不存在,则新建写入 ※ ab:二进制追加方式,如果文件已存在,将内容新增再最后;若文件不存在,则新建写入 ※ a+:读写追加,如果文件已存在,将内容新增再最后;若文件不存在,则新建写入 一、TXT文本存储 实例:爬取知乎--热门专题页面 运行结果: 二、JSON文件存储 JavaScript Object Notation—JavaScript对象标记 1、用对象和数组表示数据,结构化程度高 ※对象—键值对 {key : value} ※数组—[‘a’, ‘b’, ’c’] —> [{key 1: value1}, {key2 : value2}] 2、JSON库实现JSON文件的读写操作 ※读取JSON ※输出JSON 三、CSV文件存储【!!可以用excel打开!!】 Comma-Separated Values—逗号分隔值/字符分隔值 纯文本形式存储表格数据 1、 写入 2、 读取 【实例】知乎--热门专题--存储到excel 运行结果: 【BOOK】数据存储—文件存储(TXT、JSON、CSV) 标签:字符 end zh-cn 结构 ade 文件的读写操作 header uid name 原文地址:https://www.cnblogs.com/motoharu/p/12577132.html
## 爬取知乎热门专题
import requests
from pyquery import PyQuery as pq
url = ‘https://www.zhihu.com/special/all‘
try:
headers = {
‘cookie‘: ‘miid=421313831459957575; _samesite_flag_=true; cookie2=1cd225d128b8f915414ca1d56e99dd42; t=5b4306b92a563cc96ffb9e39037350b4; _tb_token_=587ae39b3e1b8; cna=DmpEFqOo1zMCAdpqkRZ0xo79; unb=643110845; uc3=nk2=30mP%2BxQ%3D&id2=VWsrWqauorhP&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&vt3=F8dBxdz4jRii0h%2Bs3pw%3D; csg=f54462ca; lgc=%5Cu5939zhi; cookie17=VWsrWqauorhP; dnk=%5Cu5939zhi; skt=906cb7efa634723b; existShop=MTU4MjI5Mjk4NQ%3D%3D; uc4=id4=0%40V8o%2FAfalcPHRLJCDGtb%2Fdp1gVzM%3D&nk4=0%403b07vSmMRqc2uEhDugyrBg%3D%3D; publishItemObj=Ng%3D%3D; tracknick=%5Cu5939zhi; _cc_=UIHiLt3xSw%3D%3D; tg=0; _l_g_=Ug%3D%3D; sg=i54; _nk_=%5Cu5939zhi; cookie1=AnPBkeBRJ7RXH1lHWy9jEkFiHPof0dsM6sKE2hraCKY%3D; enc=gTfBHQmDAXUW0nTwDZWT%2BXlVfPmDqVQdFSKTby%2BoWsATGTG4yqih%2FJwqG7BvGfl1N%2Bc1FeptT%2BWNjgCnd3%2FX9Q%3D%3D; __guid=154677242.2334981537288746500.1582292984682.7253; mt=ci=25_1; v=0; thw=cn; hng=CN%7Czh-CN%7CCNY%7C156; JSESSIONID=6A1CD727C830F88997EE7A11C795F670; uc1=cookie14=UoTUOLFGTPNtWQ%3D%3D&lng=zh_CN&cookie16=URm48syIJ1yk0MX2J7mAAEhTuw%3D%3D&existShop=false&cookie21=URm48syIYn73&tag=8&cookie15=URm48syIIVrSKA%3D%3D&pas=0; monitor_count=4; isg=BGRk121i5pgW-RJU8ZZzF7W5NWJW_Yhn96AFLn6F6C_yKQXzpgzI9-XL6IExt8C_; l=cBjv7QE7QsWpTNssBOCiNQhfh1_t7IRf6uSJcRmMi_5p21T_QV7OoWj0Ve96DjWhTFLB4IFj7TyTxeW_JsuKHdGJ4AadZ‘,
‘user-agent‘: "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
html = requests.get(url, headers=headers, timeout=30).text
except:
print(‘爬取失败!‘)
doc = pq(html)
## pyquery进行页面解析,class属性用 . 匹配
## 调用items()得到一个生成器,for in 进行遍历
items = doc(‘.SpecialListCard.SpecialListPage-specialCard‘).items()
for item in items:
title = item.find(‘.SpecialListCard-title‘).text()
intro = item.find(‘.SpecialListCard-intro‘).text()
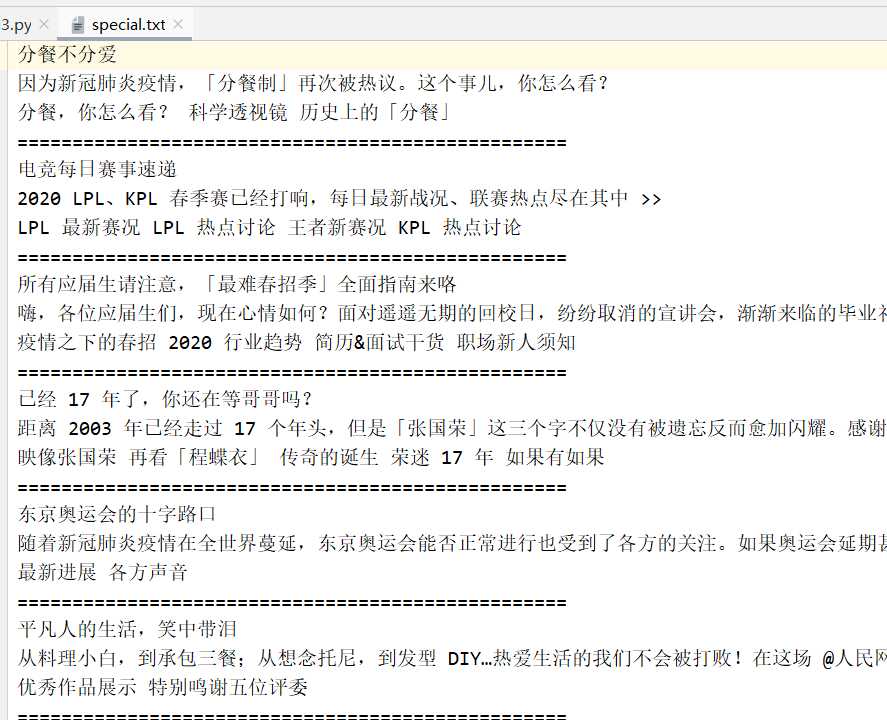
with open(‘special.txt‘, ‘a‘, encoding=‘utf-8‘) as file:
file.write(‘\n‘.join([title,intro]) + ‘\n‘)
sections = item.find(‘.SpecialListCard-sections‘).items()
for section in sections:
special = section.find(‘a‘).text()
file.write(‘\n‘.join([special]))
file.write(‘\n‘ + ‘=‘*50 + ‘\n‘)
file.close()
loads() 将字符串类型转换成JSON对象
import json
## JSON对象中的数据需要双引号 "" 包围
str = ‘‘‘
[{"name":"呱呱", "gender":"男", "age":"5"},
{"name":"嘎嘎", "gender":"女", "age":"22"}
]
‘‘‘
## loads() 将字符串类型转换成JSON对象
data = json.loads(str)
print(type(data)) ##
## 读取JSON文件
import json
with open(‘data.json‘, ‘r‘) as file:
str = file.read()
data = json.loads(str)
print(data)
dumps() 将JSON对象换成字符串
import json
## JSON对象中的数据需要双引号 "" 包围
data = [{"name":"呱呱", "gender":"男", "age":"5"},
{"name":"嘎嘎", "gender":"女", "age":"22"}
]
## dumps() 将JSON对象换成字符串
with open(‘data.json‘, ‘w‘, encoding=‘utf-8‘) as file:
## indent=2 保存的JSON对象自带缩进
## ensure_ascii=False,JSON文件中包含中文
file.write(json.dumps(data, indent=2, ensure_ascii=False))

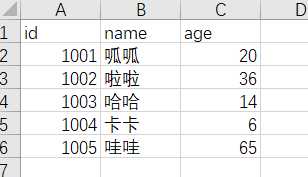
import csv
## newline=‘‘ ,保证每行之间没有空格
with open(‘data.csv‘, ‘w‘, newline=‘‘) as csvfile:
writer = csv.writer(csvfile)
## writerow() 每行写入
writer.writerow([‘id‘, ‘name‘, ‘age‘])
writer.writerow([‘1001‘, ‘呱呱‘, ‘20‘])
writer.writerow([‘1002‘, ‘啦啦‘, ‘36‘])
writer.writerow([‘1003‘, ‘哈哈‘, ‘14‘])
## writerows() 写入多行,效果同上
writer.writerows([[‘1004‘, ‘卡卡‘, ‘6‘],[‘1005‘, ‘哇哇‘, ‘65‘]])
import csv
## 字典写入
with open(‘data1.csv‘, ‘w‘, newline=‘‘) as csvfile:
fieldnames = [‘id‘, ‘name‘, ‘age‘] ## 给csv表的表头赋值
## DictWriter初始化一个字典写入对象
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({‘id‘:‘1001‘, ‘name‘:‘呱呱‘, ‘age‘:20})
writer.writerow({‘id‘: ‘1002‘, ‘name‘: ‘啦啦‘, ‘age‘: 36})
writer.writerow({‘id‘: ‘1003‘, ‘name‘: ‘哈哈‘, ‘age‘: 14})
## 追加数据
with open(‘data1.csv‘, ‘a‘, newline=‘‘) as csvfile:
fieldnames = [‘id‘, ‘name‘, ‘age‘]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writerow({‘id‘:‘1004‘, ‘name‘:‘八八‘, ‘age‘:20})
import csv
with open(‘data.csv‘, ‘r‘) as csvfile:
reader = csv.reader(csvfile)
for row in reader:
print(row)

## 爬取知乎热门专题
import requests
from pyquery import PyQuery as pq
import csv
url = ‘https://www.zhihu.com/special/all‘
try:
headers = {
‘cookie‘: ‘miid=421313831459957575; _samesite_flag_=true; cookie2=1cd225d128b8f915414ca1d56e99dd42; t=5b4306b92a563cc96ffb9e39037350b4; _tb_token_=587ae39b3e1b8; cna=DmpEFqOo1zMCAdpqkRZ0xo79; unb=643110845; uc3=nk2=30mP%2BxQ%3D&id2=VWsrWqauorhP&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&vt3=F8dBxdz4jRii0h%2Bs3pw%3D; csg=f54462ca; lgc=%5Cu5939zhi; cookie17=VWsrWqauorhP; dnk=%5Cu5939zhi; skt=906cb7efa634723b; existShop=MTU4MjI5Mjk4NQ%3D%3D; uc4=id4=0%40V8o%2FAfalcPHRLJCDGtb%2Fdp1gVzM%3D&nk4=0%403b07vSmMRqc2uEhDugyrBg%3D%3D; publishItemObj=Ng%3D%3D; tracknick=%5Cu5939zhi; _cc_=UIHiLt3xSw%3D%3D; tg=0; _l_g_=Ug%3D%3D; sg=i54; _nk_=%5Cu5939zhi; cookie1=AnPBkeBRJ7RXH1lHWy9jEkFiHPof0dsM6sKE2hraCKY%3D; enc=gTfBHQmDAXUW0nTwDZWT%2BXlVfPmDqVQdFSKTby%2BoWsATGTG4yqih%2FJwqG7BvGfl1N%2Bc1FeptT%2BWNjgCnd3%2FX9Q%3D%3D; __guid=154677242.2334981537288746500.1582292984682.7253; mt=ci=25_1; v=0; thw=cn; hng=CN%7Czh-CN%7CCNY%7C156; JSESSIONID=6A1CD727C830F88997EE7A11C795F670; uc1=cookie14=UoTUOLFGTPNtWQ%3D%3D&lng=zh_CN&cookie16=URm48syIJ1yk0MX2J7mAAEhTuw%3D%3D&existShop=false&cookie21=URm48syIYn73&tag=8&cookie15=URm48syIIVrSKA%3D%3D&pas=0; monitor_count=4; isg=BGRk121i5pgW-RJU8ZZzF7W5NWJW_Yhn96AFLn6F6C_yKQXzpgzI9-XL6IExt8C_; l=cBjv7QE7QsWpTNssBOCiNQhfh1_t7IRf6uSJcRmMi_5p21T_QV7OoWj0Ve96DjWhTFLB4IFj7TyTxeW_JsuKHdGJ4AadZ‘,
‘user-agent‘: "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
html = requests.get(url, headers=headers, timeout=30).text
except:
print(‘爬取失败!‘)
doc = pq(html)
## pyquery进行页面解析,class属性用 . 匹配
## 调用items()得到一个生成器,for in 进行遍历
with open(‘data1.csv‘, ‘a‘, newline=‘‘) as csvfile:
header = [‘专题标题‘, ‘说明‘, ‘子专题‘]
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
items = doc(‘.SpecialListCard.SpecialListPage-specialCard‘).items()
for item in items:
title = item.find(‘.SpecialListCard-title‘).text()
intro = item.find(‘.SpecialListCard-intro‘).text()
sections = item.find(‘.SpecialListCard-sections‘).items()
for section in sections:
special = section.find(‘a‘).text()
writer.writerow({‘专题标题‘: title, ‘说明‘: intro, ‘子专题‘: special})
csvfile.close()

文章标题:【BOOK】数据存储—文件存储(TXT、JSON、CSV)
文章链接:http://soscw.com/essay/70599.html