使用Netty如何解决拆包粘包的问题
2021-04-03 14:27
标签:initial sina protected atom 传输 需要 ram 分拆 field 首先,我们通过一个DEMO来模拟TCP的拆包粘包的情况:客户端连续向服务端发送100个相同消息。服务端的代码如下: 客户端代码如下: 运行结果如下: 首先,我们发了1000个消息,但是在服务端有49行输出,同时,有些消息是合并在一起的,有些消息解析出了乱码。上面的输出中,包含三种情况: 这个是因为Netty底层是走的TCP协议,说白了传输的是就是字节流,消息与消息之间是没有边界的。发生TCP粘包拆包的原因主要有: 本质上来讲,TCP协议的包并不是按照业务消息来拆分的,TCP层并不感知发送的消息的大小。 解决粘包拆包的思路,其实就是在接收数据的时候,将字节流拆分成完整的包: Netty中提供了一些拆包器,能够满足大部分的使用场景: 如果你的业务消息格式很简单,是固定长度的,则使用该拆包器很方便。 结果如下: 可以看到,服务端收到了1000个完整的独立的包。 这个拆包器拆包的逻辑就是按行拆分,发送端每个数据之间用换行符作为分隔符,接收端通过也会按照换行符将字节流拆分成业务消息。 接收数据段,添加行拆包器: 运行后,我们可以看到接收端能够接收到1000个完整的包。 DelimiterBasedFrameDecoder允许指定一个分隔符,在收到消息的时候按照指定的分隔符进行拆包。其实上面说的LineBasedFrameDecoder是一个特定的分隔符拆包器,它指定的是使用换行符作为分隔符,下面使用DelimiterBasedFrameDecoder来实现行拆包器: 基于分隔符的拆包器允许设置多个分隔符,在设置多个分隔符的情况下,会将包拆分成最小的满足分隔符的包。 最后一种拆包器是通用性最强的一种拆包器,只要我们协议的中有一个固定的区域来表示数据长度,就可以方便的使用该拆包器。LengthFieldBaesdFrameDecoder有很多可配置的参数,用来应对各种情况的长度域。 假设消息中长度域就在开头,这种情况下不需要考虑长度域之前是否有其他内容,配置LengthFieldBasedFrameDecoder很简单,设置offset为0,以及长度域的字节数。这里以长度域占2字节为例: 一个解析的例子: 上面的例子中,我们保留了协议头,虽然这里的协议头就有长度域。如果我们只想保留数据域,这里需要设置跳过的字节数为2字节: 拆包示例: 在前面两个例子,长度的长度表示的是长度之后的数据长度。这里我们考虑长度里面设置的长度表示的是整个消息的大小,包括头部和数据部分。这种情况下我们需要制定 拆包示例: 前面的case中,协议头部只有长度域,但是更多的情况中,HEADER中不只有长度域。比如下面这个例子,HEADER部分有三部分,HDR1,Length,HDR2三部分,分别占1个字节,2个字节,1个字节。 代码如下: 解析结果: 使用Netty如何解决拆包粘包的问题 标签:initial sina protected atom 传输 需要 ram 分拆 field 原文地址:https://www.cnblogs.com/yuanged/p/12539121.htmlAtomicLong count = new AtomicLong(0);
NioEventLoopGroup boss = new NioEventLoopGroup();
NioEventLoopGroup worker = new NioEventLoopGroup();
ServerBootstrap serverBootstrap = new ServerBootstrap()
.group(boss, worker)
.channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 1024)
.childOption(ChannelOption.SO_KEEPALIVE, true)
.childHandler(new ChannelInitializerNioEventLoopGroup nioEventLoopGroup = new NioEventLoopGroup();
Bootstrap bootstrap = new Bootstrap()
.group(nioEventLoopGroup)
.option(ChannelOption.SO_KEEPALIVE, true)
.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, 5000)
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer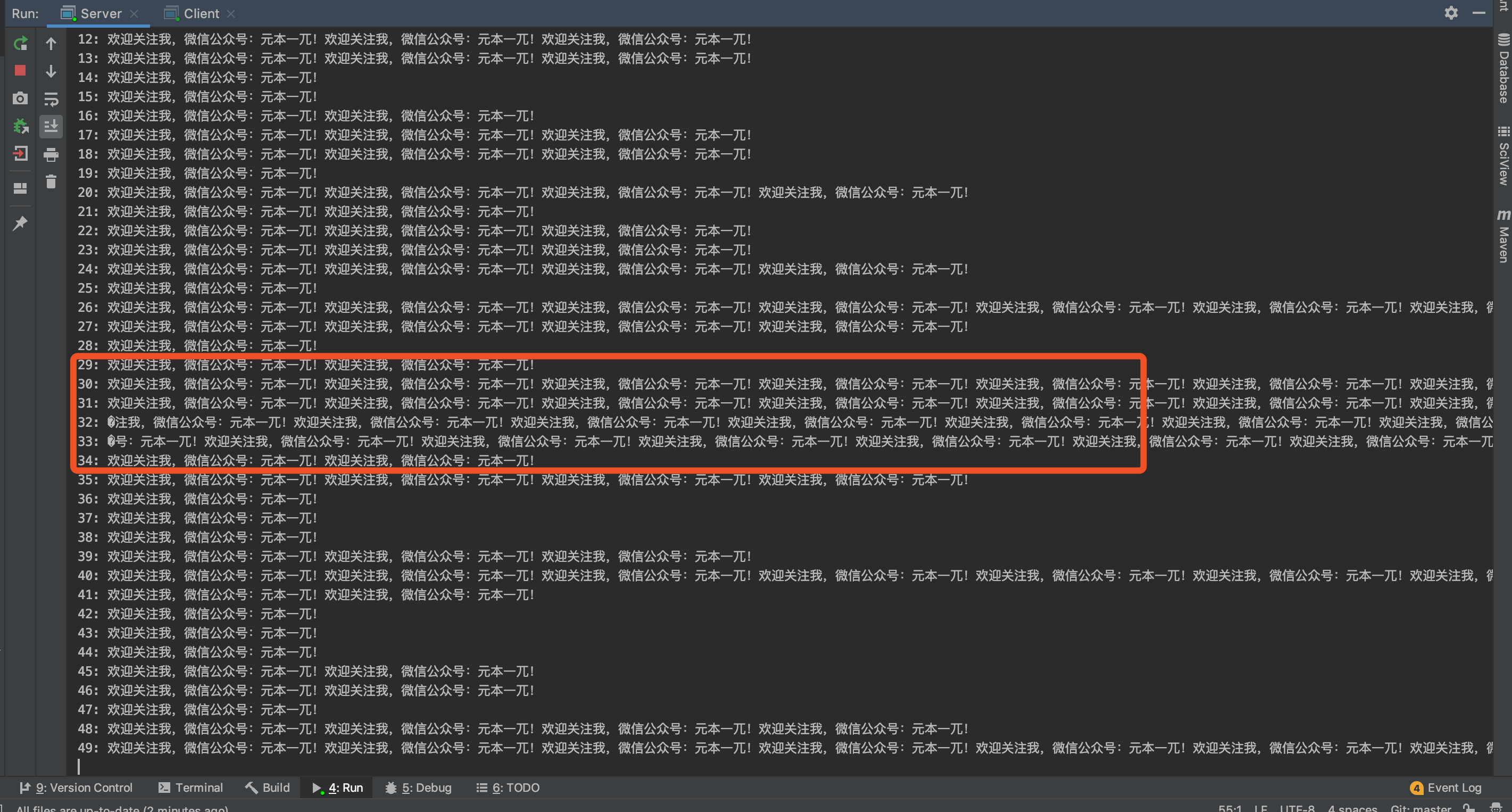
为什么会粘包、拆包?
解决粘包拆包的方法
Netty中常用的拆包器
定长拆包器-FixedLengthFrameDecoder
比如上面的代码,发送的数据是固定的51个字节,我们在服务端的pipeline中加上定长拆包器:AtomicLong count = new AtomicLong(0);
NioEventLoopGroup boss = new NioEventLoopGroup();
NioEventLoopGroup worker = new NioEventLoopGroup();
ServerBootstrap serverBootstrap = new ServerBootstrap()
.group(boss, worker)
.channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 1024)
.childOption(ChannelOption.SO_KEEPALIVE, true)
.childHandler(new ChannelInitializer
行拆包器-LineBasedFrameDecoder
修改一下的上面的客户端,消息后追加一个\r\n:@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
for (int i = 0; i @Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ch.pipeline().addLast(new LineBasedFrameDecoder(Integer.MAX_VALUE))
.addLast(new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf byteBuf = (ByteBuf) msg;
long l = count.incrementAndGet();
System.out.println(l + ": " + byteBuf.toString(StandardCharsets.UTF_8));
}
});
}基于分隔符的拆包器-DelimiterBasedFrameDecoder
ch.pipeline().addLast(
new DelimiterBasedFrameDecoder(Integer.MAX_VALUE, delimiterLine, delimiterSharp))
.addLast(new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf byteBuf = (ByteBuf) msg;
long l = count.incrementAndGet();
System.out.println(l + ": " + byteBuf.toString(StandardCharsets.UTF_8));
}
});基于长度域的拆包器-LengthFieldBasedFrameDecoder
长度域的offset为0
new LengthFieldBasedFrameDecoder(Integer.MAX_VALUE, 0, 2) BEFORE DECODE (14 bytes) AFTER DECODE (14 bytes)
+--------+----------------+ +--------+----------------+
| Length | Actual Content |----->| Length | Actual Content |
| 0x000C | "HELLO, WORLD" | | 0x000C | "HELLO, WORLD" |
+--------+----------------+ +--------+----------------+长度域offset为0,去掉协议头
new LengthFieldBasedFrameDecoder(
Integer.MAX_VALE, // maxFrameLength
0, // lengthFieldOffset
2, // lengthFieldLength
0, // lengthAdjustment
2) // initalBytesToStrip 跳过2字节,也就是跳过长度域 * BEFORE DECODE (14 bytes) AFTER DECODE (12 bytes)
* +--------+----------------+ +----------------+
* | Length | Actual Content |----->| Actual Content |
* | 0x000C | "HELLO, WORLD" | | "HELLO, WORLD" |
* +--------+----------------+ +----------------+
长度域占2字节,offset为0,不跳过header,长度域表示所有消息的大小
lengthAdjustment,数据部分的长度为 长度域里的长度 - lengthAdjustment。
new LengthFieldBasedFrameDecoder(
Integer.MAX_VALE, // maxFrameLength
0, // lengthFieldOffset
2, // lengthFieldLength
2, // lengthAdjustment 长度 - lengthAdjustment为数据部分的长度
0) // initalBytesToStrip * BEFORE DECODE (14 bytes) AFTER DECODE (14 bytes)
* +--------+----------------+ +--------+----------------+
* | Length | Actual Content |----->| Length | Actual Content |
* | 0x000E | "HELLO, WORLD" | | 0x000E | "HELLO, WORLD" |
* +--------+----------------+ +--------+----------------+
HEADER中不只有长度域的情况
在长度域之前还有HDR1,要定位到长度域,需要指定长度域的offset(lengthFieldOffset=1)。
这里长度域存的是所有的数据长度,如果我们希望拆包的结果中包含HDR2+Data两部分,可以通过设置lengthAdjustment=-3,长度域之后的内容长度是HDR2+DATA。拆包的结果中,只想包含HDR2+DATA,所以整个消息跳过钱3个字节(HDR1+Lenght部分)。 * +------+--------+------+----------------+
* | HDR1 | Length | HDR2 | Data |
* | 0xCA | 0x000C | 0xFE | "HELLO, WORLD" |
* +------+--------+------+----------------+
new LengthFieldBasedFrameDecoder(
Integer.MAX_VALE, // maxFrameLength
3, // lengthFieldOffset
2, // lengthFieldLength
-3, // lengthAdjustment 长度 - lengthAdjustment为数据部分的长度
3) // initalBytesToStrip * BEFORE DECODE (16 bytes) AFTER DECODE (13 bytes)
* +------+--------+------+----------------+ +------+----------------+
* | HDR1 | Length | HDR2 | Data |----->| HDR2 | Data |
* | 0xCA | 0x0010 | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
* +------+--------+------+----------------+ +------+----------------+