Java做爬虫也很牛
2021-04-04 11:28
标签:msi osi win 响应 快照 use input close ip代理 工具类实现比较简单,就一个get方法,读取请求地址的响应内容,这边我们用来抓取网页的内容,这边没有用代理,在真正的抓取过程中,当你大量请求某个网站的时候,对方会有一系列的策略来禁用你的请求,这个时候代理就排上用场了,通过代理设置不同的IP来抓取数据。 接下来我们随便找一个有图片的网页,来试试抓取功能 首先将网页的内容抓取下来,然后用正则的方式解析出网页的标签,再解析img的地址。执行程序我们可以得到下面的内容: 通过上面的地址我们就可以将图片下载到本地了,下面我们写个图片下载的方法: 这样就很简单的实现了一个抓取并且提取图片的功能了,看起来还是比较麻烦哈,要写正则之类的 ,下面给大家介绍一种更简单的方式,如果你熟悉jQuery的话对提取元素就很简单了,这个框架就是Jsoup。 jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。 添加jsoup的依赖: 使用jsoup之后提取的代码只需要简单的几行即可: 通过Jsoup.parse创建一个文档对象,然后通过getElementsByTag的方法提取出所有的图片标签,循环遍历,通过attr方法获取图片的src属性,然后下载图片。 Jsoup使用起来非常简单,当然还有很多其他解析网页的操作,大家可以去看看资料学习一下。 下面我们再来升级一下,做成一个小工具,提供一个简单的界面,输入一个网页地址,点击提取按钮,然后把图片自动下载下来,我们可以用swing写界面。 执行main方法首先出来的就是我们的界面了,如下: 大数据时代,如何形成大数据。 大用户量,每天很多日志。 搞个爬虫,抓几十亿数据过来分析分析。 并不是只有Python才能做爬虫,Java照样可以。 今天带大家来写一个简单的图片抓取程序,将网页上的图片全部下载下来 原价59的课程,目前只要19.9,学习课程请加我微信: image 文章推荐 更多技术分享尽在微信群,加群请关注公众号,点击加群按钮。 Java做爬虫也很牛 标签:msi osi win 响应 快照 use input close ip代理 原文地址:https://blog.51cto.com/14888386/2516361import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
public class HttpUtils {
public static String get(String url) {
try {
URL getUrl = new URL(url);
HttpURLConnection connection = (HttpURLConnection) getUrl
.openConnection();
connection.setRequestMethod("GET");
connection.setRequestProperty("Accept", "*/*");
connection
.setRequestProperty("User-Agent",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; CIBA)");
connection.setRequestProperty("Accept-Language", "zh-cn");
connection.connect();
BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream(), "utf-8"));
String line;
StringBuffer result = new StringBuffer();
while ((line = reader.readLine()) != null){
result.append(line);
}
reader.close();
return result.toString();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}public static void main(String[] args) {
String url = "https://www.toutiao.com/a6568327638044115460/";
String html = HttpUtils.get(url);
Listhttp://p9.pstatp.com/large/pgc-image/1529307883634343f939c85
http://p1.pstatp.com/large/pgc-image/1529307883606177aaf408b
http://p3.pstatp.com/large/pgc-image/152930788361571655944eb
http://p1.pstatp.com/large/pgc-image/1529307883500ad4375beb0
http://p3.pstatp.com/large/pgc-image/1529307883536bc68e6156epublic static void main(String[] args) throws MalformedURLException, IOException {
String url = "https://www.toutiao.com/a6568327638044115460/";
String html = HttpUtils.get(url);
List
public static void main(String[] args) throws MalformedURLException, IOException {
String url = "https://www.toutiao.com/a6568327638044115460/";
String html = HttpUtils.get(url);
Document doc = Jsoup.parse(html);
Elements imgs = doc.getElementsByTag("img");
for (Element img : imgs) {
String imgSrc = img.attr("src");
if (imgSrc.startsWith("//")) {
imgSrc = "http:" + imgSrc;
}
Files.copy(new URL(imgSrc).openStream(), Paths.get("./img/"+UUID.randomUUID()+".png"));
}
}public class App {
public static void main(String[] args) {
JFrame frame = new JFrame();
frame.setResizable(false);
frame.setSize(425,400);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.setLayout(null);
frame.setLocationRelativeTo(null);
JTextField jTextField = new JTextField();
jTextField.setBounds(100, 44, 200, 30);
frame.add(jTextField);
JButton jButton = new JButton("提取");
jButton.setBounds(140, 144, 100, 30);
frame.add(jButton);
frame.setVisible(true);
jButton.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
String url = jTextField.getText();
if (url == null || url.equals("")) {
JOptionPane.showMessageDialog(null, "请填写抓取地址");
return;
}
String html = HttpUtils.get(url);
Document doc = Jsoup.parse(html);
Elements imgs = doc.getElementsByTag("img");
for (Element img : imgs) {
String imgSrc = img.attr("src");
if (imgSrc.startsWith("//")) {
imgSrc = "http:" + imgSrc;
}
try {
Files.copy(new URL(imgSrc).openStream(), Paths.get("./img/"+UUID.randomUUID()+".png"));
} catch (MalformedURLException e1) {
e1.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
}
JOptionPane.showMessageDialog(null, "抓取完成");
}
});
}
}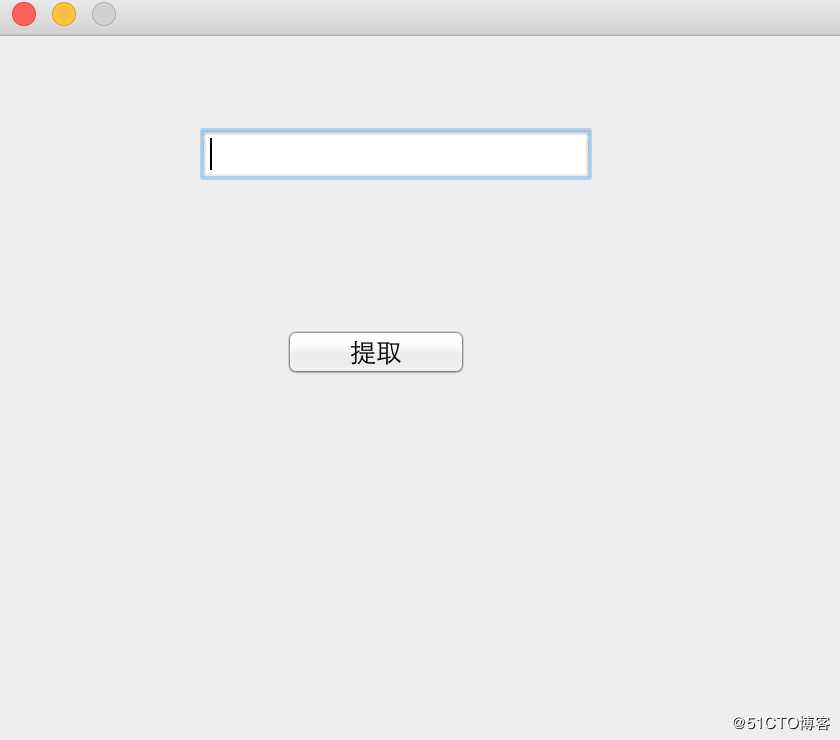
屏幕快照 2018-06-18 09.50.34 PM.png
屏幕快照 2018-06-18 09.50.34 PM.png
输入地址,点击提取按钮即可下载图片。课程推荐
image
image
本课程将带领大家一步一步编写爬虫程序,爬到我们想要的数据,非登陆的或者需要登陆的都爬下来。
课程大纲
image
1大牛坐镇|高端JAVA纯技术群你要加入吗?
2 Spring Cloud如何提供API给客户端
3前后端API交互如何保证数据安全性?
4Spring Cloud Zuul过滤器获取请求参数问题?
5Spring Boot 1.X和2.X优雅重启实战