这个厉害了,阿里P7大佬都在看的SpringCloud 总结,帮你梳理全部知识点!
2021-04-13 06:30
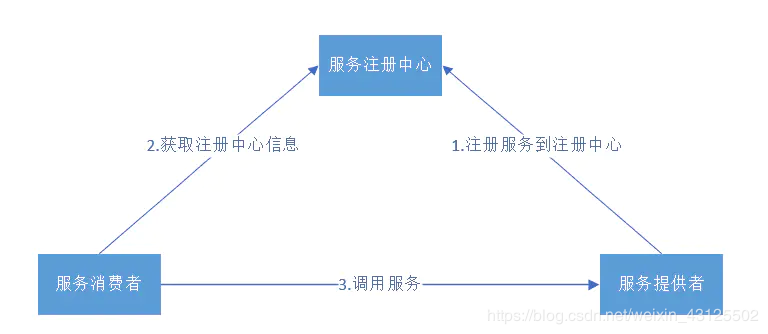
标签:ogr sql 情况下 str 批量 开发 方式 registry src ??微服务架构是一种以一些微服务来替代开发单个大而全应用的方法,每一个小服务运行在自己的进程里,并以轻量级的机制来通信, 通常是 HTTP RESTful API。微服务强调小快灵, 任何一个相对独立的功能服务不再是一个模块, 而是一个独立的服务。 ??可以对微服务架构中的每个组件服务进行开发、部署、运营和扩展,而不影响其他服务的功能。这些服务不需要与其他服务共享任何代码或实施。各个组件之间的任何通信都是通过明确定义的 API 进行的。 ??每项服务都是针对一组功能而设计的,并专注于解决特定的问题。如果开发人员逐渐将更多代码增加到一项服务中并且这项服务变得复杂,那么可以将其拆分成多项更小的服务。 ??通过微服务,您可以独立扩展各项服务以满足其支持的应用程序功能的需求。这使团队能够适当调整基础设施需求,准确衡量功能成本,并在服务需求激增时保持可用性。 ??微服务支持持续集成和持续交付,可以轻松尝试新想法,并可以在无法正常运行时回滚。由于故障成本较低,因此可以大胆试验,更轻松地更新代码,并缩短新功能的上市时间。 ??目前主流的就是springCloud和dubbo了,那么我们对他们做一个对比: ??一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用、智能容错、负载均衡,以及服务自动注册和发现。 Provider: 暴露服务的服务提供方。 服务容器负责启动,加载,运行服务提供者。 ??SpringCould是基于SpringBoot的基础上的一个微服务架构。包括包服务发现(Eureka),断路器(Hystrix),服务网关(Zuul),客户端负载均衡(Ribbon)、服务跟踪(Sleuth)、消息总线(Bus)、消息驱动(Stream)、批量任务(Task)等。Spring Cloud抛弃了Dubbo 的RPC通信,采用的是基于HTTP的REST方式。 Eureka包含两个组件:Eureka Server和Eureka Client Eureka Server提供服务发现能力,各个微服务启动时会向Eureka Server注册自己的信息(服务名、IP、端口等),Eureka Server便存储了这个信息。功能类似于zookeeper ??CAP原则又称CAP定理,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。CAP原则是NOSQL(Redis、mongdb)数据库的基石。 一致性(Consistency):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本) CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但放弃P的同时也就意味着放弃了系统的扩展性,也就是分布式节点受限,没办法部署子节点,这是违背分布式系统设计的初衷的。传统的关系型数据库RDBMS:Oracle、MySQL就是CA。 CP without A:如果不要求A(可用),相当于每个请求都需要在服务器之间保持强一致,而P(分区)会导致同步时间无限延长(也就是等待数据同步完才能正常访问服务),一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统。设计成CP的系统其实不少,最典型的就是分布式数据库,如Redis、HBase等。对于这些分布式数据库来说,数据的一致性是最基本的要求,因为如果连这个标准都达不到,那么直接采用关系型数据库就好,没必要再浪费资源来部署分布式数据库。 AP wihtout C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。典型的应用就如某米的抢购手机场景,可能前几秒你浏览商品的时候页面提示是有库存的,当你选择完商品准备下单的时候,系统提示你下单失败,商品已售完。这其实就是先在 A(可用性)方面保证系统可以正常的服务,然后在数据的一致性方面做了些牺牲,虽然多少会影响一些用户体验,但也不至于造成用户购物流程的严重阻塞。 zookeeper保证的是CP Ribbon工作原理 集中式LoadBalance 随机负载均衡(默认):随机选择状态为UP的Server Hystrix为分布式系统的延迟和故障提供强大的容错能力。 当一个节点出问题的时候,hystrix保证了整体不会失败,提高了分布式系统的弹性 ??微服务架构中某个微服务发生故障时,要快速切断服务,提示用户,后续请求,不调用该服务,直接返回,释放资源,这就是服务熔断。 ??服务器高并发下,压力剧增的时候,根据当业务情况以及流量,对一些服务和页面有策略的降级(可以理解为关闭不必要的服务),以此缓解服务器资源的压力以保障核心任务的正常运行。 网关:系统唯一对外的入口,介于客户端与服务器端之间,用于对请求进行鉴权、限流、 路由、监控等功能。 zuul提供了两个主要功能:路由和过滤 路由功能负责将外部请求转发到具体的微服务实例上,是实现外部访问统一入口的基础。 通俗点就是统一了访问地址 ??在分布式系统中,由于服务数量巨多,为了方便服务配置文件统一管理,实时更新,所以需要分布式配置中心组件。在Spring Cloud中,有分布式配置中心组件spring cloud config ,它支持配置服务放在配置服务的内存中(即本地),也支持放在远程Git仓库中。在spring cloud config 组件中,分两个角色,一是config server,二是config client。server提供配置文件的存储、以接口的形式将配置文件的内容提供出去,client通过接口获取数据、并依据此数据初始化自己的应用。 大家看完有什么不懂的可以在下方留言讨论,也可以关注我私信问我,我看到后都会回答的。也欢迎大家关注我的公众号:前程有光,金三银四跳槽面试季,整理了1000多道将近500多页pdf文档的Java面试题资料,文章都会在里面更新,整理的资料也会放在里面。谢谢你的观看,觉得文章对你有帮助的话记得关注我点个赞支持一下! 这个厉害了,阿里P7大佬都在看的SpringCloud 总结,帮你梳理全部知识点! 标签:ogr sql 情况下 str 批量 开发 方式 registry src 原文地址:https://blog.51cto.com/14801695/2511728
??微服务是一种生态,不是一种具体技术微服务的特性
自主性(松耦合)
专用性
灵活扩展
轻松部署
目前微服务的发展状况
Dubbo
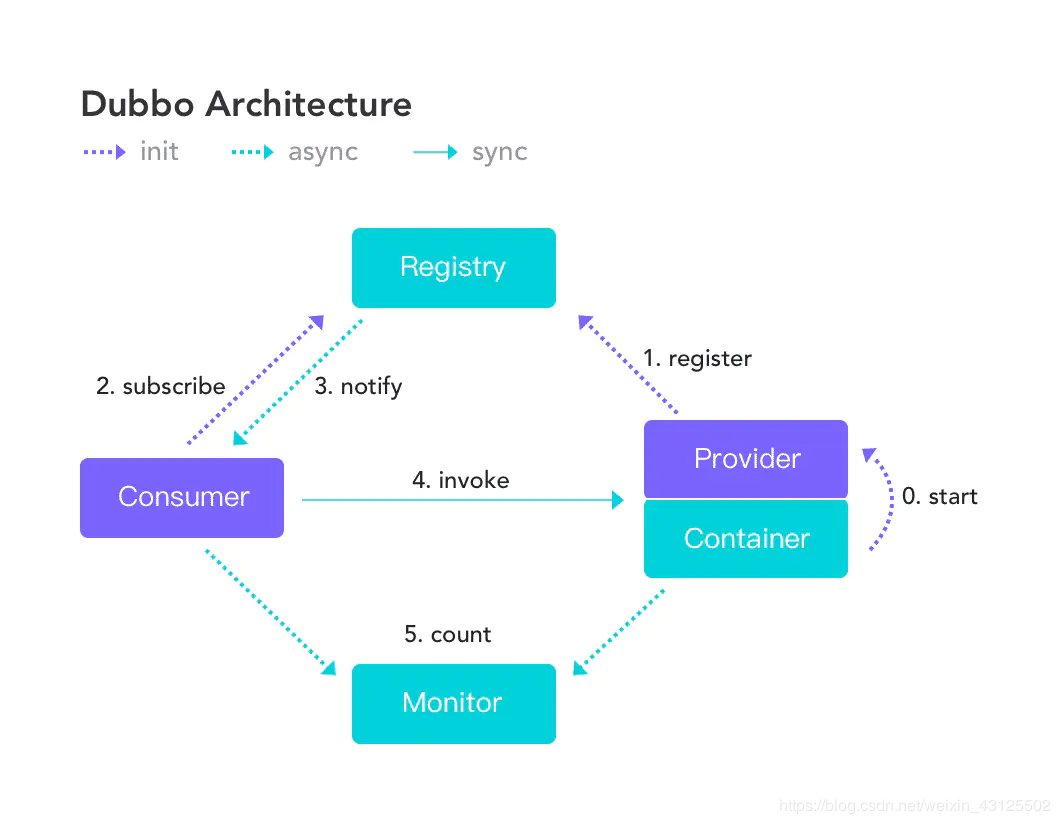
节点角色说明:
Consumer: 调用远程服务的服务消费方。
Registry: 服务注册与发现的注册中心。(Dubbo种一般都是使用zookeeper作为注册中心)
Monitor: 统计服务的调用次调和调用时间的监控中心。
Container: 服务运行容器。调用关系说明:
服务提供者在启动时,向注册中心注册自己提供的服务。
服务消费者在启动时,向注册中心订阅自己所需的服务。
注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。SpringCloud与Dubbo的对比
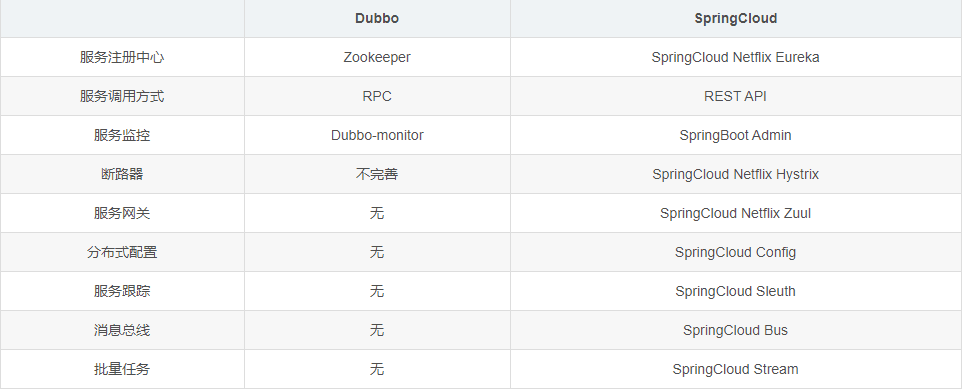
??Dubbo和Spring Cloud并不是完全的竞争关系,两者所解决的问题域不一样:Dubbo的定位始终是一款RPC框架,而Spring Cloud的目的是微服务架构下的一站式解决方案。SpringCloud
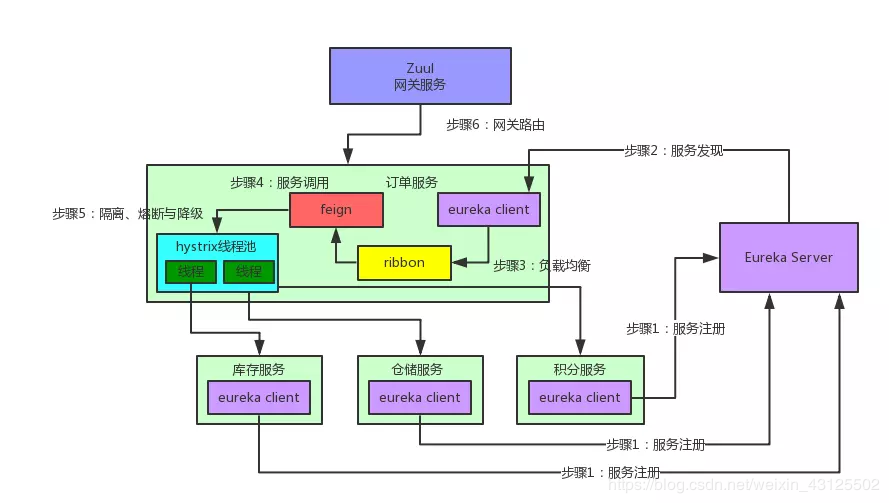
服务发现——Netflix Eureka
Eureka Client 是一个Java客户端,用于简化与Eureka的交互。
心跳机制:每个微服务启动后, 会每个一定时间(默认30s)向Eureka Server 发送心,让其知道自己扔健康存活。如果Eureka Server在一定时间内(默认90s)没有收到某个微服务实例的心跳,Eureka Server就会注销该实例
Eureka集群:默认情况下,Eureka Server也是Eureka Client,多个Eureka Server之间通过复制方式,来实现服务注册表中的数据同步。Eureka Client会缓存服务注册表中的信息, 无须每次都请求Eureka Server查询,缓解了Eureka Server的压力;即使Eureka Server所有节点都宕机,服务消费者依然可以查询自己缓存中的信息找到去调用服务提供者。
自我保护机制:若是因为网络原因,通过心跳机制判读该服务已死导致实例被注销时,这是不被允许的。因此自我保护机制来解决这个问题,当EurekaServer节点短时间内丢失过多客户端(网络原因导致),那么这个节点就会进入自我保护模式,一旦进入该模式,EurekaServer就会保护服务注册表中的信息,不再删除服务注册表中的数据(也就是不会注销任何微服务)。当网络恢复时,该EurekaServer节点会退出自我保护机制。自我保护机制使Eureka集群更加的稳定与健壮。CAP原则
可用性(Availability):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
分区容错性(Partition tolerance):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择(集群下必须要保证P)。CAP三个特性只能满足其中两个:
zookeeper和Eureka
zookeeper存在的问题:当master挂掉的时候会通过选举产生新的master,但是由于在选举期间集群不可用且选举时间过长导致服务长期不可用。
Eureka保证的是AP
Eureka由于保证的是可用性,因此不会出现上面那种情况。因为Eureka的每个节点都是平等的,挂掉几个节点不会影响整体的工作,当某个Eurek的客户端注册失败的时候会自动切换到其他节点进行注册,只要是还有一台存活就阔以保证可用性,只不过查询到的数据不是最新的。
?? 因此Eureka可以很好的应对因为网络故障导致节点丢失的情况,而不是像zookeeper那样使整个注册服务瘫痪的情况。客服端负载均衡——Netflix Ribbon
ribbon实现的关键点是为ribbon定制的RestTemplate,ribbon利用了RestTemplate的拦截器机制,在拦截器中实现ribbon的负载均衡。负载均衡的基本实现就是利用applicationName从服务注册中心获取可用的服务地址列表,然后通过一定算法负载,决定使用哪一个服务地址来进行http调用。负载均衡分类
在消费者和提供者之间使用独立的LoadBanlance设备,如Nginx(反向代理服务器)。由该设备将访问亲求分发到提供者。
进程式LoadBalance
将LoadBanlance的逻辑整合到消费者,消费者从注册中心获取可用的地址,然后自己通过策略选择合适的服务器。Ribbon就是典型的进程式。负载均衡算法
简单轮询负载均衡:以轮询的方式依次将请求调度不同的服务器
加权响应时间负载均衡:根据响应时间分配一个weight,响应时间越长,weight越小,被选中的可能性越低
区域感知轮询负载均衡:复合判断server所在区域的性能和server的可用性选择server断路器——Netflix Hystrix
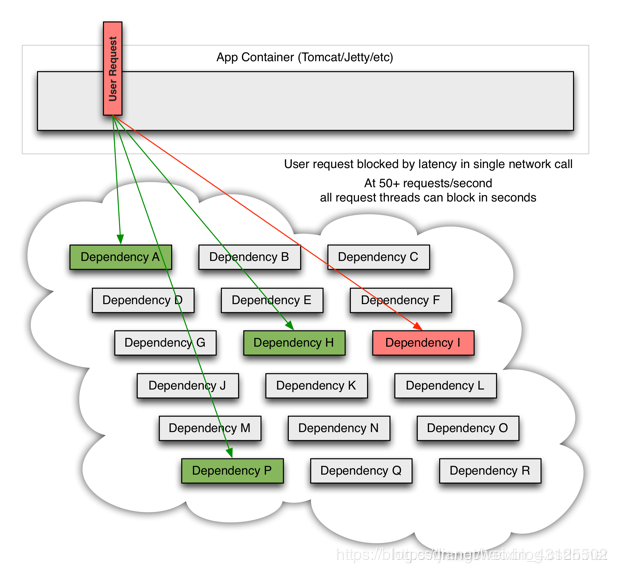
服务熔断
熔断生效后,会在指定的时间后调用请求来测试依赖是否恢复,依赖的应用恢复后关闭熔断。服务降级
双十一期间,支付宝很多功能都会提示,[双十一期间,保障核心交易,某某服务数据延迟]。服务网关——Netflix Zuul
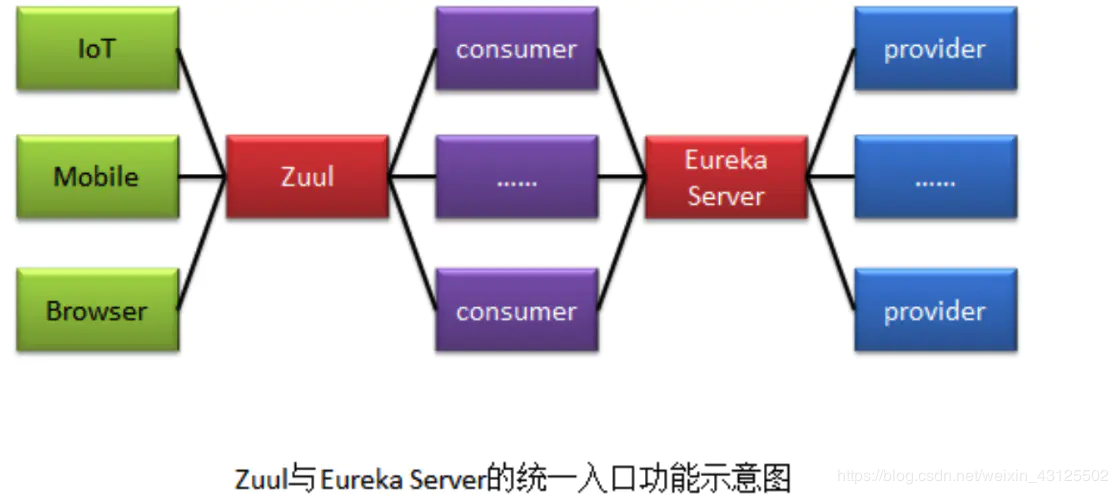
过滤功能则负责对请求的处理过程进行干预,是实现请求校验、鉴权等处理
??Zuul和Eureka进行整合,将Zuul自身注册为Eureka服务治理下的应用,同时从Eureka中获得其他微服务的消息,也即以后的访问微服务都是通过Zuul跳转后获得。
??注意:Zuul服务最终还是会注册进Eureka分布式配置——Spring Cloud Config
最后
文章标题:这个厉害了,阿里P7大佬都在看的SpringCloud 总结,帮你梳理全部知识点!
文章链接:http://soscw.com/essay/75080.html