SpringCloud学习总结(十一)——服务熔断Hystrix高级
2021-04-30 16:29
标签:比较 探测 sof row 一起 慢慢 服务架构 图片 中心 案例准备 用例 我们知道,当请求失败,被拒绝,超时的时候,都会进入到降级方法中。但进入降级方法并不意味着断路器已经被打开。那么如何才能了解断路器中的状态呢? 除了实现容错功能,Hystrix还提供了近乎实时的监控,HystrixCommand和 HystrixObservableCommand在执行时,会生成执行结果和运行指标。比如每秒的请求数量,成功数量等。这些状态会暴露在Actuator提供的/health端点中。只需为项目添加 spring -boot-actuator 依赖,重启项目,访问 注意:接下来使用 Hystrix Actuator的监控,访问/hystrix.stream接口获取的以文字形式展示的信息。 添加@EnableCircuitBreaker注解,监控信息查看需要配置激活hystrix。 暴露所有actuator监控的端点 刚刚讨论了Hystrix的监控,但访问/hystrix.stream接口获取的都是以文字形式展示的信息。很难通过文字直观的展示系统的运行状态,所以Hystrix官方还提供了基于图形化的DashBoard(仪表板)监控平台,界面操作查看比较友好。 Hystrix仪表板可以显示每个断路器(被@HystrixCommand注解的方法)的状态。 在启动类使用@EnableHystrixDashboard注解激活仪表盘项目。 地址: http://localhost:9003/hystrix 输入监控断点展示监控的详细数据地址: http://localhost:9003/actuator/hystrix.stream 在微服务架构体系中,每个服务都需要配置Hystrix DashBoard监控。如果每次只能查看单个实例服务的监控数据,就需要不断切换监控地址,这显然很不方便。要想看各个系统的Hystrix Dashboard数据就需要用到Hystrix Turbine。 Turbine是一个聚合Hystrix 监控数据的工具,他可以将所有相关微服务的Hystrix 监控数据聚合到一起,方便使用。引入Turbine后,整个监控系统架构如下: 新增一个 eureka 相关配置 :指定注册中心地址 turbine 相关配置:指定需要监控的微服务列表 turbine会自动的从注册中心中获取需要监控的微服务,并聚合所有微服务中的 /hystrix.stream 数据,appConfig配置的服务名必须都有配置 /hystrix.stream 数据。 作为一个独立的监控项目,需要配置启动类,开启 HystrixDashboard监控平台,并激活Turbine 浏览器访问 熔断器有三个状态 CLOSED 、 OPEN 、 HALF_OPEN 熔断器默认关闭状态,当触发熔断后状态变更为OPEN ,在等待到指定的时间,Hystrix会放请求检测服务是否开启,这期间熔断器会变为 HALF_OPEN 半开启状态,熔断探测服务可用则继续变更为 CLOSED 关闭熔断器。 Closed :关闭状态(断路器关闭),所有请求都正常访问。代理类维护了最近调用失败的次数,如果某次调用失败,则使失败次数加1。如果最近失败次数超过了在给定时间内允许失败的阈值,则代理类切换到断开(Open)状态。此时代理开启了一个超时时钟,当该时钟超过了该时间,则切换到半断开(Half-Open)状态。该超时时间的设定是给了系统一次机会来修正导致调用失败的错误。 Open :打开状态(断路器打开),所有请求都会被降级。Hystix会对请求情况计数,当一定时间内失败请求百分比达到阈值,则触发熔断,断路器会完全关闭。默认失败比例的阈值是50%,请求次数最少不低于20次。 Half Open :半开状态,open状态不是永久的,打开后会进入休眠时间(默认是5S)。随后断路器会自动进入半开状态。此时会释放1次请求通过,若这个请求是健康的,则会关闭断路器,否则继续保持打开,再次进行5秒休眠计时。 为了能够精确控制请求的成功或失败,我们在 我们准备两个请求窗口: 一个请求: http://localhost:9003/order/buy/1 ,肯定成功 一个请求: http://localhost:9003/order/buy/2 ,注定失败 熔断器的默认触发阈值是20次请求,不好触发。休眠时间时5秒,时间太短,不易观察,为了测试方 便,配置订单模块 解读: requestVolumeThreshold :触发熔断的最小请求次数,默认20 errorThresholdPercentage :触发熔断的失败请求最小占比,默认50% sleepWindowInMilliseconds :熔断多少秒后去尝试请求 当我们疯狂访问id为2的请求时(超过10次),就会触发熔断。断路器会端口,一切请求都会被降级处理。 此时你访问id为1的请求,会发现返回的也是失败,而且失败时间很短,只有20毫秒左右: 微服务使用Hystrix熔断器实现了服务的自动降级,让微服务具备自我保护的能力,提升了系统的稳定性,也较好的解决雪崩效应。 其实现方式目前支持两种策略: 线程池隔离策略: 使用一个线程池来存储当前的请求,线程池对请求作处理,设置任务返回处理超时时间,堆积的请求堆积入线程池队列。这种方式需要为每个依赖的服务申请线程池,有一定的资源消耗,好处是可以应对突发流量(流量洪峰来临时,处理不完可将数据存储到线程池队里慢慢处理);Hystrix 对每个外部依赖用一个单独的线程池,这样的话,如果对那个外部依赖调用延迟很严重则其他线程降级处理或者加入线程池队列,最多就是耗尽那个依赖自己的线程池而已,不会影响其他的依赖调用。 信号量隔离策略: 使用一个原子计数器(或信号量)来记录当前有多少个线程在运行,请求来先断计数器的数值,若超过设置的最大线程个数则丢弃改类型的新请求,若不超过则执行计数操作请求来计数器+1,请求返回计数器-1。这种方式是严格的控制线程且立即返回模式,无法应对突发流量(流量洪峰来临时,处理的线程超过数量,其他的请求会直接返回,不继续去请求依赖的服务) 线程池和型号量两种策略功能支持对比如下: //TODO 感谢itheima提供的材料 SpringCloud学习总结(十一)——服务熔断Hystrix高级 标签:比较 探测 sof row 一起 慢慢 服务架构 图片 中心 原文地址:https://www.cnblogs.com/TvvT-kevin/p/12544709.htmlspring_cloud_hystrix 项目地址:传送门一、Hystrix的监控平台
http://localhost:端口/actuator/hystrix.stream ,即可看到实时的监控数据: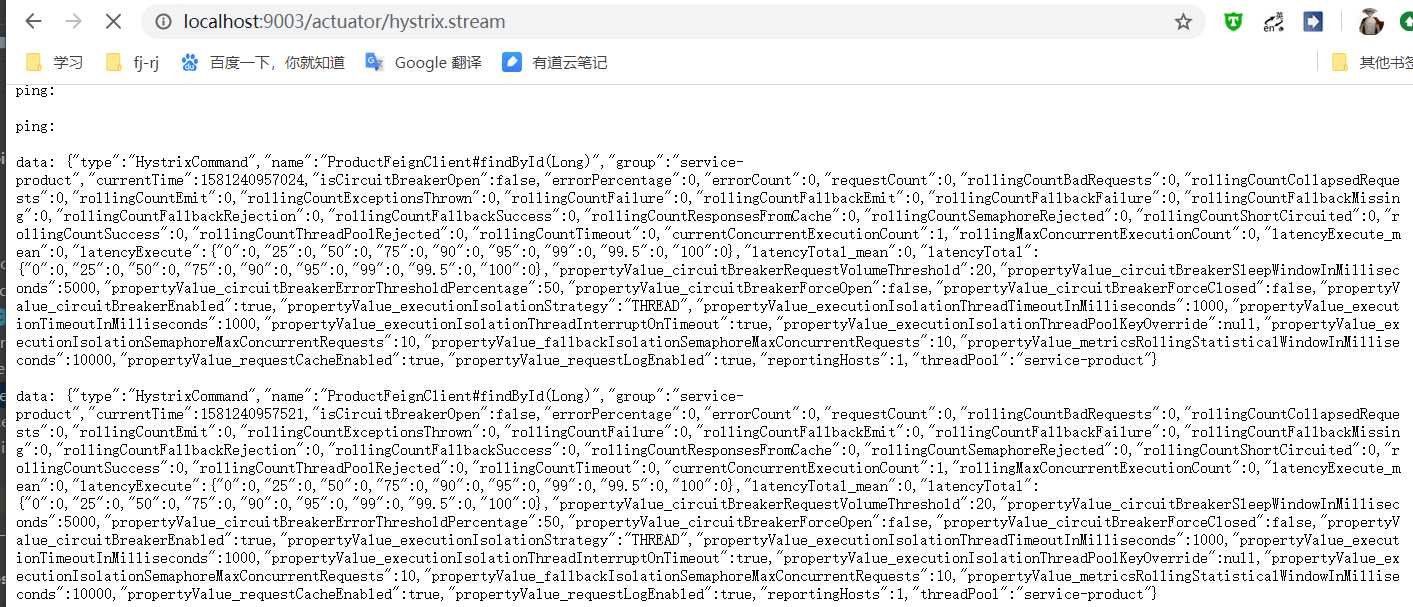
order_service_feign模块来讲解。1、搭建Hystrix Actuator监控
(1)导入依赖
dependency>
groupId>org.springframework.bootgroupId>
artifactId>spring-boot-starter-actuatorartifactId>
dependency>
dependency>
groupId>org.springframework.cloudgroupId>
artifactId>spring-cloud-starter-netflix-hystrixartifactId>
dependency>
dependency>
groupId>org.springframework.cloudgroupId>
artifactId>spring-cloud-starter-netflix-hystrix-dashboardartifactId>
dependency>
(2)配置启动类
@SpringBootApplication
@EntityScan("cn.hzp.order.domain")
//激活Feign
@EnableFeignClients
//激活hystrix
@EnableCircuitBreaker
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class,args);
}
?
(3)配置application.yml
management:
endpoints:
web:
exposure:
include: ‘*‘
2 、搭建Hystrix DashBoard监控
(1)导入依赖
dependency>
groupId>org.springframework.bootgroupId>
artifactId>spring-boot-starter-actuatorartifactId>
dependency>
dependency>
groupId>org.springframework.cloudgroupId>
artifactId>spring-cloud-starter-netflix-hystrixartifactId>
dependency>
dependency>
groupId>org.springframework.cloudgroupId>
artifactId>spring-cloud-starter-netflix-hystrix-dashboardartifactId>
dependency>
(2)配置启动类
@SpringBootApplication
@EntityScan("cn.hzp.order.domain")
//激活Feign
@EnableFeignClients
//激活hystrix
@EnableCircuitBreaker
//激活hytrix的web监控平台
@EnableHystrixDashboard
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class,args);
}
?
(3)访问测试

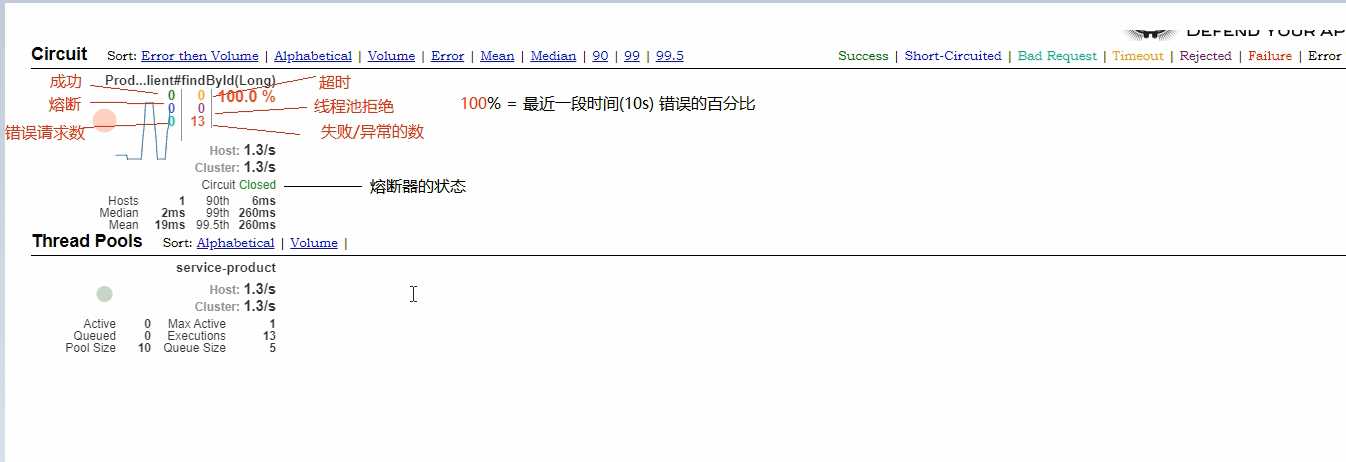
3、断路器聚合监控Turbine
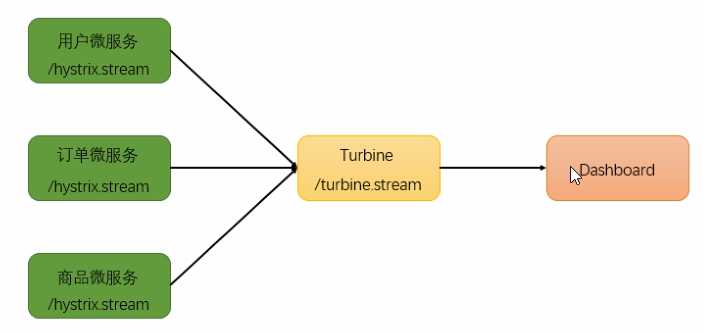
(1) 搭建TurbineServer
hystrix_turbine工程模块,引入相关坐标
dependencies>
dependency>
groupId>org.springframework.cloudgroupId>
artifactId>spring-cloud-starter-netflix-turbineartifactId>
dependency>
dependency>
groupId>org.springframework.cloudgroupId>
artifactId>spring-cloud-starter-netflix-hystrixartifactId>
dependency>
dependency>
groupId>org.springframework.cloudgroupId>
artifactId>spring-cloud-starter-netflix-hystrix-dashboardartifactId>
dependency>
dependencies>
(2) 配置多个微服务的hystrix监控
server:
port: 8031
spring:
application:
name: hystrix-turbine
eureka:
client:
service-url:
defaultZone: http://localhost:9000/eureka/
instance:
prefer-ip-address: true
turbine:
# 要监控的微服务列表,多个用,分隔;并且这些服务都有配置 /hystrix.stream 数据
appConfig: service-order
clusterNameExpression: "‘default‘"
(3)配置启动类
@SpringBootApplication
//trubin配置
@EnableTurbine
@EnableHystrixDashboard
public class TurbinAppliation {
?
public static void main(String[] args) {
SpringApplication.run(TurbinAppliation.class,args);
}
}
(4) 测试
http://localhost:8031/hystrix 展示HystrixDashboard。并在url位置输入 http://localhost:8031/turbine.stream ,动态根据turbine.stream数据展示多个微服务的监控数据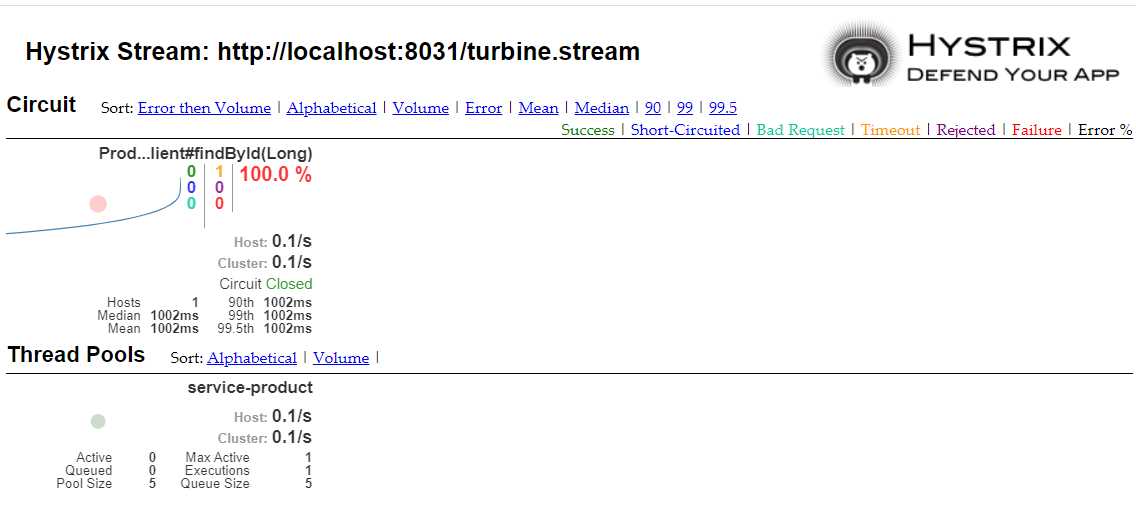
二、熔断器的状态
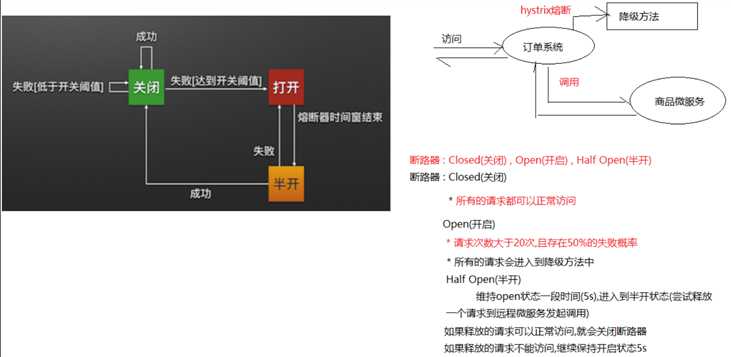
配置熔断策略
1、商品服务添加报错逻辑
product_service模块ProductController类的调用业务中加入一段逻辑:id不为1就抛出异常,这样订单服务如果访问id不为1就会报错,从而模拟订单服务的熔断降级策略。@RestController
@RequestMapping("/product")
public class ProductController {
@Autowired
private ProductService productService;
@RequestMapping(value = "/{id}",method = RequestMethod.GET)
public Product findById(@PathVariable Long id) {
//id不为1就抛出异常
if(id != 1) {
throw new RuntimeException("服务器异常");
}
Product product = productService.findById(id);
return product;
}
}
2、订单服务配置熔断策略配置
order_service_feign的yml配置修改熔断策略:#hystrix熔断策略配置
hystrix:
command:
default:
execution:
thread:
timeoutInMilliseconds: 3000 #默认的连接超时时间1秒,若1秒没有返回数据,自动的触发降级逻辑
circuitBreaker:
requestVolumeThreshold: 5 #触发熔断的最小请求次数10秒5次,默认10秒20次
sleepWindowInMilliseconds: 10000 #熔断多少秒后去尝试请求 默认5s打开状态的时间
errorThresholdPercentage: 50 #触发熔断的失败请求最小占比,默认50%
3、测试熔断效果
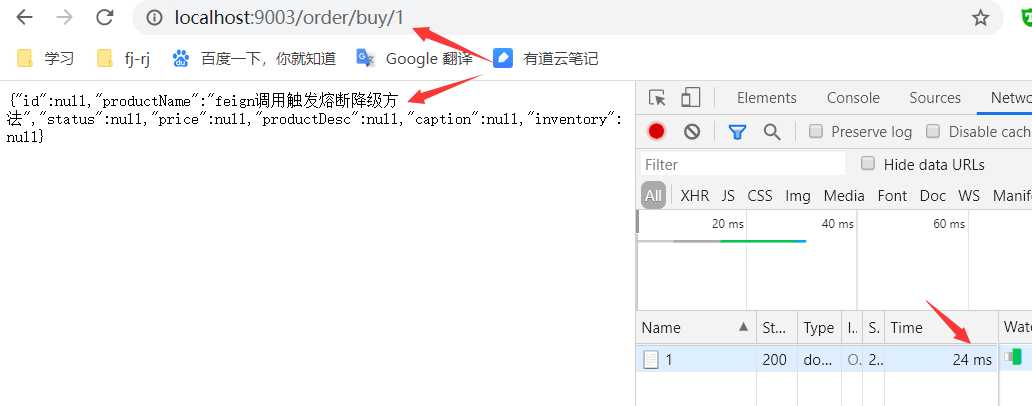
三、熔断器的隔离策略

hystrix.command.default.execution.isolation.strategy : 配置隔离策略
ExecutionIsolationStrategy.SEMAPHORE 信号量隔离ExecutionIsolationStrategy.THREAD 线程池隔离hystrix.command.default.execution.isolation.maxConcurrentRequests : 最大信号量上限hystrix:
command:
default:
execution:
isolation:
strategy: ExecutionIsolationStrategy.SEMAPHORE #信号量隔离
#strategy: ExecutionIsolationStrategy.THREAD 线程池隔离
四、Hystrix的核心源码

上一篇:异常——python基础篇
下一篇:python-拆包、交换变量的值
文章标题:SpringCloud学习总结(十一)——服务熔断Hystrix高级
文章链接:http://soscw.com/essay/80474.html