HTTP请求流程你了解了么?
2021-05-08 02:29
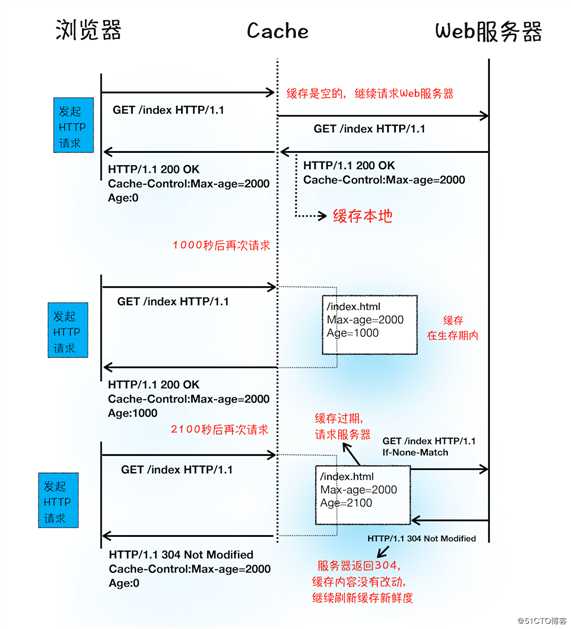
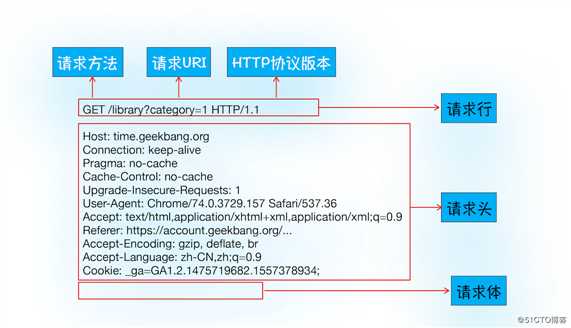
标签:str 物理 数据链路层 接收 服务器错误 出现 telnet location https 前文没有描述到传输和协议直接的层级对应关系,大概补充下网络通信中数据传输对应的协议,首先了解下OSI(开放式系统互联:Open System InterConnection)七层 模式,及其对应不同层次的协议。 了解到HTTP协议是建立在TCP连接基础之上的。HTTP 是一种允许浏览器向服务器获取资源的协议,是 Web 的基础,通常由浏览器发起请求,用来获取不同类型的文件, 例如 HTML 文件、CSS 文件、JavaScript 文件、图片、视频等。此外,HTTP 也是浏览器使用最广的协议。 我们对HTTP不太了解的话都会存在这样的疑惑,为什么再次访问同一站点会比第一次快,登录过一次后的网站再次访问就处于登录状态等,我们 通过对HTTP请求过程的剖析来解开这些谜团。 浏览器输入网址:http://time.geekbang.org/index.html,之后会完成什么步骤呢? 首先,浏览器构建请求行信息,构建好后,浏览器准备发起网络请求。 在真正发起网络请求之前,浏览器会先在浏览器缓存中查询是否有要请求的文件。其中,浏览器缓存是一种在本地保存资源副本,以供下次请求时直接使用的技术。 当浏览器发现请求资源已经存在浏览器缓存中存有副本,则会拦截请求并返回该资源副本结束请求。如果查找缓存失败,则会进入网络请求。所以会有利于: 缓解服务器端压力,提升性能 我们通过开头预备知识和前文也大概了解到了HTTP和TCP的关系。浏览器使用?HTTP 协议作为应用层协议,用来封装请求的文本信息;并使用?TCP/IP 作传输层协议将它发到网络上,所以在 HTTP 工作开始之前,浏览器需要通过 TCP 与服务器建立连接。也就是说 HTTP 的内容是通过 TCP 的传输数据阶段来实现的。 TCP和HTTP的关系示意图: 据此,我们可以知道建立HTTP网络请求就是,通过URL地址来解析获取IP和端口信息,建立服务器和TCP连接。我们通过前文《TCP协议》 说到了数据包都是通过IP地址传输给接收方的。而我们网站一般的地址都是域名,所以需要把域名和IP地址做映射关系,即解析IP地址的系统“域名系统(DNS)”解析出 IP地址,并获取对应端口号获得建立连接的前置条件。换句话说,即浏览器请求DNS返回域名对应的IP,而请求DNS时也会查询DNS数据缓存服务,判断是否域名已解析过, 如果解析过则查询直接使用,拿到IP后则判断URL是否指明端口号,没有则HTTP协议默认时80端口。 Chrome 有个机制,同一个域名同时最多只能建立 6 个 TCP 连接,如果在同一个域名下同时有 10 个请求发生,那么其中 4 个请求会进入排队等待状态,直至进行中的请求完成。当然,如果当前请求数量少于 6,会直接进入下一步,建立 TCP 连接。 队列等待结束后,TCP和服务器实现“三次握手”(前文TCP协议有描述),即客户端和服务器发送三个数据包以确认连接,实现浏览器和服务的连接。 一旦建立了 TCP 连接,浏览器就可以和服务器进行通信了。而 HTTP 中的数据正是在这个通信过程中传输的。 HTTP请求数据格式: 首先浏览器会向服务器发送请求行,它包括了请求方法、请求 URI(Uniform Resource Identifier)和 HTTP 版本协议。 其中请求方式有GET,POST,PUT,Delete等,其中常用的POST会用于发送一些数据给服务器,比如登录网站把用户信息发送给服务器,一般 这些数据会通过请求体发送。 在浏览器发送请求行命令之后,还要以请求头形式发送其他一些信息,把浏览器的一些基础信息告诉服务器。比如包含了浏览器所使用的操作系统、浏览器内核等信息,以及当前请求的域名信息、Cookie等。 通过curl工具(或network面板)我们可以了解到服务器返回的数据格式: 首先服务器会返回响应行,包括协议版本和状态码。 如果出现错误,服务器会通过请求行的状态码来返回对应的处理结果,例如: 最常用的状态码是 200,表示处理成功; 404,表示没有找到页面 正如浏览器会随同请求发送请求头一样,服务器也会随同响应向浏览器发送响应头。响应头包含了服务器自身的一些信息, 比如服务器生成返回数据的时间、返回的数据类型(JSON、HTML、流媒体等类型),以及服务器要在客户端保存的 Cookie 等信息。 响应头之后,服务器会发送响应体数据,通常包含了HTML的实际内容。以上为服务器响应浏览器的过程。 一旦服务器向客户端返回了请求数据,它就要关闭 TCP 连接。不过如果浏览器或者服务器在其头信息中加入了: 则TCP 连接在发送后将仍然保持打开状态,这样浏览器就可以继续通过同一个 TCP 连接发送请求。保持 TCP 连接可以省去下次请求时需要建立连接的时间,提升资源加载速度。?如果一个页面内嵌的图片都来自同一web站点,则初始化一个持久连接则可复用减少TCP的连接。 重定向返回响应行和响应头: 状态 301 就是告诉浏览器,我需要重定向到另外一个网址,而需要重定向的网址正是包含在响应头的 Location 字段中,接下来,浏览器获取 Location 字段中的地址,并使用该地址重新导航,这就是一个完整重定向的执行流程。 通过http请求的完整过程,我们就知道,请求过程中DNS缓缓和页面资源缓存会被浏览器缓存起来,以减少向服务器请求的资源,所以会再次请求站点时速度会快。 浏览器资源缓存处理过程: 从上图的第一次请求可以看出,当服务器返回 HTTP 响应头给浏览器时,浏览器是通过响应头中的 Cache-Control 字段来设置是否缓存该资源。通常,我们还需要为这个资源设置一个缓存过期时长,而这个时长是通过 Cache-Control 中的 Max-age 参数来设置的。 因此在该缓存资源还未过期的情况下, 如果再次请求该资源,会直接返回缓存中的资源给浏览器。 如果缓存过期了,浏览器则会继续发起网络请求,并且在?HTTP 请求头中带上If-None-Match,服务器收到请求头后,会根据 If-None-Match 的值来判断请求的资源是否有更新。 如果没有更新,就返回 304 状态码,相当于服务器告诉浏览器,这个缓存可以继续使用。 登录网站,通过POST方式提交信息给服务器,服务器接收到浏览器提交的信息之后,查询验证信息正确则会生成表面用户身份的字符串写入响应头的Set-Cookie字段里返回浏览器。 浏览器解析响应头,如有Set-Cookie字段则保存在本地,当用户再次访问时,发起HTTP请求前浏览器会读取Cookie数据并写入请求头发送到服务器,服务器再次判断信息,如果 正确则展示用户登录状态及用户信息。 最后总结出浏览器中的HTTP请求从发起到结束一共经历了八个阶段:构建请求、查找缓存、准备 IP 和端口、等待 TCP 队列、建立 TCP 连接、发起 HTTP 请求、服务器处理请求、服务器返回请求和断开连接。 详细HTTP请求流程: HTTP请求流程你了解了么? 标签:str 物理 数据链路层 接收 服务器错误 出现 telnet location https 原文地址:https://blog.51cto.com/14230003/2460797
OSI体系结构
TCP/IP相关协议结构
应用层
HTTP,Telnet,FTP等
表示层
?
会话层
?
传输层
TCP,UDP
网络层
IP
数据链路层
?
物理层
?
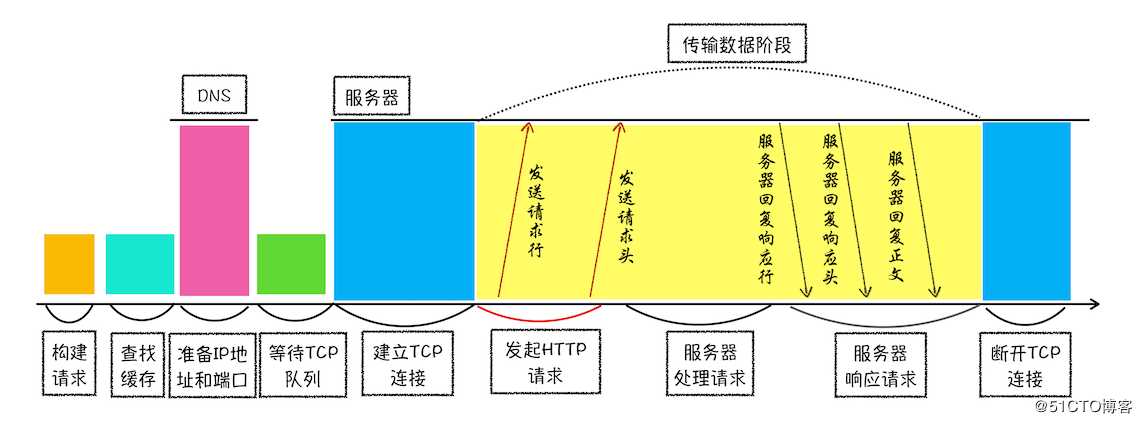
浏览器端发起 HTTP 请求流程
1、构建请求
GET /index.html HTTP1.12、查找缓存
3、准备IP地址和端口
4、等待TCP队列
5、建立TCP连接
6、发送HTTP请求
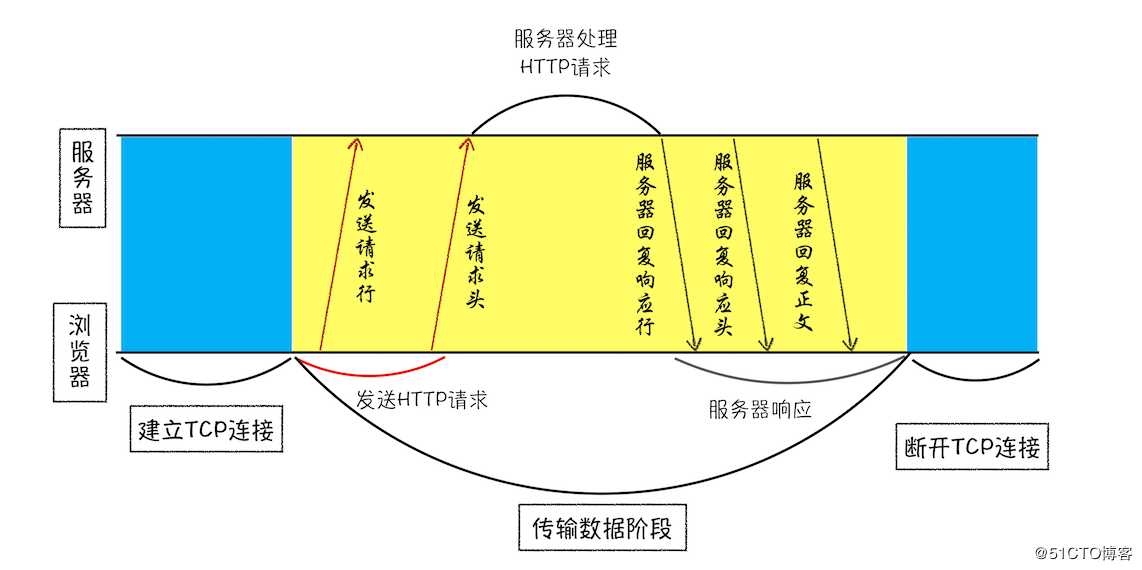
服务器端处理 HTTP 请求流程
1、返回请求
curl -i https://time.geekbang.org/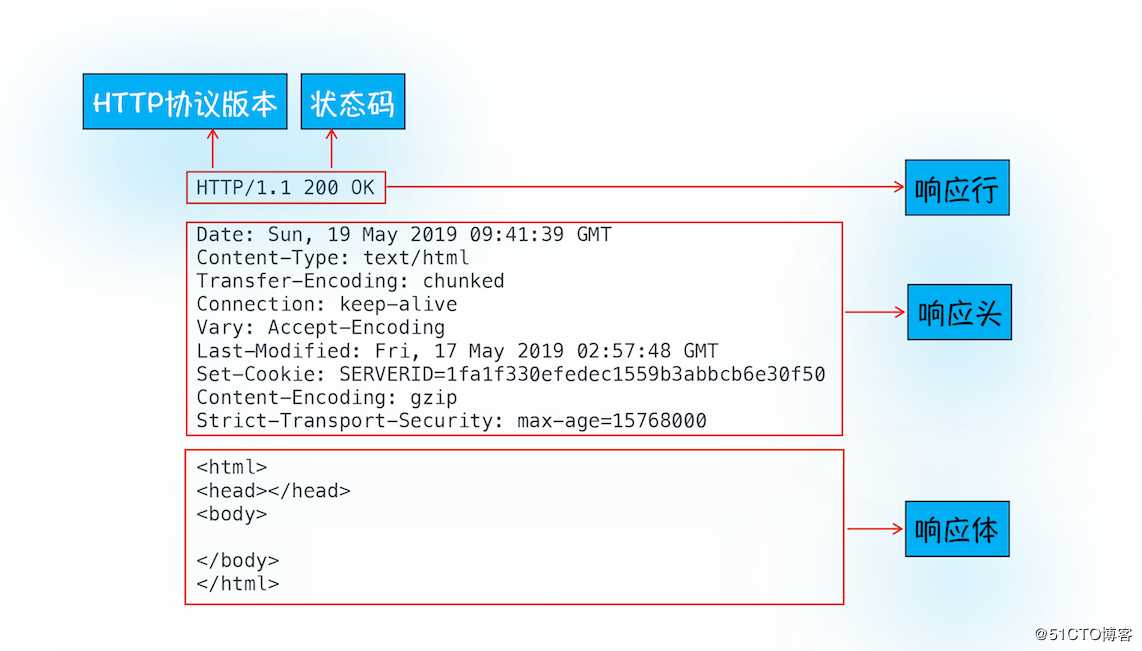
2、断开连接
Connection:Keep-Alive3、重定向

总结