Java函数式编程和lambda表达式
2021-05-15 15:28
标签:链式 opera bat 时间戳 demo 类型 新特性 和我 面向 函数式编程更多时候是一种编程的思维方式,是种方法论。函数式与命令式编程的区别主要在于:函数式编程是告诉代码你要做什么,而命令式编程则是告诉代码要怎么做。说白了,函数式编程是基于某种语法或调用API去进行编程。例如,我们现在需要从一组数字中,找出最小的那个数字,若使用用命令式编程实现这个需求的话,那么所编写的代码如下: 而使用函数式编程进行实现的话,所编写的代码如下: 从以上的两个例子中,可以看出,命令式编程需要自己去实现具体的逻辑细节。而函数式编程则是调用API完成需求的实现,将原本命令式的代码写成一系列嵌套的函数调用,在函数式编程下显得代码更简洁、易懂,这就是为什么要使用函数式编程的原因之一。所以才说函数式编程是告诉代码你要做什么,而命令式编程则是告诉代码要怎么做,是一种思维的转变。 说到函数式编程就不得不提一下lambda表达式,它是函数式编程的基础。在Java还不支持lambda表达式时,我们需要创建一个线程的话,需要编写如下代码: 而使用lambda表达式一句代码就能完成线程的创建,lambda强调了函数的输入输出,隐藏了过程的细节,并且可以接受函数当作输入(参数)和输出(返回值): 注:箭头的左边是输入,右边则是输出。 该lambda表达式的作用其实就是返回了Runnable接口的实现对象,这与我们调用某个方法获取实例对象类似,只不过是将实现代码直接写在了lambda表达式里。我们可以做个简单的对比: 1.函数接口,接口只能有一个需要实现的方法,可以使用@FunctionalInterface 注解进行声明。如下: 使用lambda表达式获取该接口的实现实例的几种写法: 2.比较重要的一个接口特性是接口的默认方法,用于提供默认实现。默认方法和普通实现类的方法一样,可以使用this等关键字: 之所以说默认方法这个特性比较重要,是因为我们借助这个特性可以在以前所编写的一些接口上提供默认实现,并且不会影响任何的实现类以及既有的代码。例如我们最熟悉的List接口,在JDK1.2以来List接口就没有改动过任何代码,到了1.8之后才使用这个新特性增加了一些默认实现。这是因为如果没有默认方法的特性的话,修改接口代码带来的影响是巨大的,而有了默认方法后,增加默认实现可以不影响任何的代码。 3.当接口多重继承时,可能会发生默认方法覆盖的问题,这时可以去指定使用哪一个接口的默认方法实现,如下示例: 我们本小节来看看JDK8里自带了哪些重要的函数接口: 运行以上例子,控制台输出如下: 若在这个例子中不使用Function接口的话,则需要自行定义一个函数接口,并且不支持链式操作,如下示例: 然后我们再来看看Predicate接口和Consumer接口的使用,如下示例: 运行以上例子,控制台输出如下: 这些接口一般有对基本类型的封装,使用特定类型的接口就不需要去指定泛型了,如下示例: 运行以上代码,控制台输出如下: 有了以上接口示例的铺垫,我们应该对函数接口的使用有了一个初步的了解,接下来我们演示剩下的函数接口使用方式: 运行以上代码,控制台输出如下: 而BiFunction接口就是比Function接口多了一个输入而已,如下示例: 运行以上代码,控制台输出如下: 在学习了lambda表达式之后,我们通常会使用lambda表达式来创建匿名方法。但有的时候我们仅仅是需要调用一个已存在的方法。如下示例: 在jdk8中,我们可以通过一个新特性来简写这段lambda表达式。如下示例: 这种特性就叫做方法引用(Method Reference)。方法引用的标准形式是:类名::方法名。(注意:只需要写方法名,不需要写括号)。 目前方法引用共有以下四种形式: 下面我们用一个简单的例子来演示一下方法引用的几种写法。首先定义一个实体类: 通过方法引用来调用该实体类中的方法,代码如下: 最后需要说一句的就是能够使用方法引用的地方就尽量不要使用lambda表达式,这样就不会多生成一个类似 通过以上的例子,我们知道之所以能够使用Lambda表达式的依据是必须有相应的函数接口。这一点跟Java是强类型语言吻合,也就是说你并不能在代码的任何地方任性的写Lambda表达式。实际上Lambda的类型就是对应函数接口的类型。Lambda表达式另一个依据是类型推断机制,在上下文信息足够的情况下,编译器可以推断出参数表的类型,而不需要显式指名。 示例代码如下: Lambda表达式类似于实现了指定接口的内部类或者说匿名类,所以在Lambda表达式中引用变量和我们在匿名类中引用变量的规则是一样的。如下示例: 值得一提的是,在JDK1.8之前我们一般会将匿名类里访问的外部变量设置为final,而在JDK1.8里默认会将这个匿名类里访问的外部变量给设置为final。例如我现在改变str变量的值,ide就会提示错误: 下面用一组图片简单演示一下值传递与引用传递的区别。以列表为例,当只是值传递时,匿名类里对外部变量的引用是一个值对象: 在函数式编程中,函数既可以接收也可以返回其他函数。函数不再像传统的面向对象编程中一样,只是一个对象的工厂或生成器,它也能够创建和返回另一个函数。返回函数的函数可以变成级联 lambda 表达式,特别值得注意的是代码非常简短。尽管此语法初看起来可能非常陌生,但它有自己的用途。 级联表达式就是多个lambda表达式的组合,这里涉及到一个高阶函数的概念,所谓高阶函数就是一个可以返回函数的函数,如下示例: 这里的 y -> x + y 是作为一个函数返回给上一级表达式,所以第一级表达式的输出是 y -> x + y这个函数,如果使用括号括起来可能会好理解一些: 级联表达式可以实现函数柯里化,简单来说柯里化就是把本来多个参数的函数转换为只有一个参数的函数,如下示例: 如果大家想学习以上路线内容,在此我向大家推荐一个架构学习交流群。交流学习群号874811168 里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化、分布式架构等这些成为架构师必备的知识体系。还能领取免费的学习资源,目前受益良多 函数柯里化的目的是将函数标准化,函数可灵活组合,方便统一处理等,例如我可以在循环里只需要调用同一个方法,而不需要调用另外的方法就能实现一个数组内元素的求和计算,代码如下: 级联表达式和柯里化一般在实际开发中并不是很常见,所以对其概念稍有理解即可,这里只是简单带过,若对其感兴趣的可以查阅相关资料。 Java函数式编程和lambda表达式 标签:链式 opera bat 时间戳 demo 类型 新特性 和我 面向 原文地址:https://www.cnblogs.com/jajian/p/9745942.html为什么要使用函数式编程
public static void main(String[] args) {
int[] nums = new int[]{1, 2, 3, 4, 5, 6, 7, 8};
int min = Integer.MAX_VALUE;
for (int num : nums) {
if (num public static void main(String[] args) {
int[] nums = new int[]{1, 2, 3, 4, 5, 6, 7, 8};
int min = IntStream.of(nums).min().getAsInt();
System.out.println(min);
}public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("running");
}
}).start();
}public static void main(String[] args) {
new Thread(() -> System.out.println("running")).start();
}public static void main(String[] args) {
Runnable runnable1 = () -> System.out.println("running");
Runnable runnable2 = RunnableFactory.getInstance();
}JDK8接口新特性
@FunctionalInterface
interface Interface1 {
int doubleNum(int i);
}public static void main(String[] args) {
// 最常见的写法
Interface1 i1 = (i) -> i * 2;
Interface1 i2 = i -> i * 2;
// 可以指定参数类型
Interface1 i3 = (int i) -> i * 2;
// 若有多行代码可以这么写
Interface1 i4 = (int i) -> {
System.out.println(i);
return i * 2;
};
}@FunctionalInterface
interface Interface1 {
int doubleNum(int i);
default int add(int x, int y) {
return x + y;
}
}@FunctionalInterface
interface Interface1 {
int doubleNum(int i);
default int add(int x, int y) {
return x + y;
}
}
@FunctionalInterface
interface Interface2 {
int doubleNum(int i);
default int add(int x, int y) {
return x + y;
}
}
@FunctionalInterface
interface Interface3 extends Interface1, Interface2 {
@Override
default int add(int x, int y) {
// 指定使用哪一个接口的默认方法实现
return Interface1.super.add(x, y);
}
}函数接口
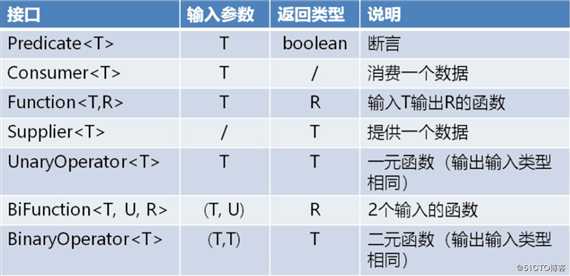
可以看到上表中有好几个接口,而其中最常用的是Function接口,它能为我们省去定义一些不必要的函数接口,减少接口的数量。我们使用一个简单的例子演示一下 Function 接口的使用:import java.text.DecimalFormat;
import java.util.function.Function;
class MyMoney {
private final int money;
public MyMoney(int money) {
this.money = money;
}
public void printMoney(Function我的存款: 人民币 99,999,999import java.text.DecimalFormat;
// 自定义一个函数接口
@FunctionalInterface
interface IMoneyFormat {
String format(int i);
}
class MyMoney {
private final int money;
public MyMoney(int money) {
this.money = money;
}
public void printMoney(IMoneyFormat moneyFormat) {
System.out.println("我的存款: " + moneyFormat.format(this.money));
}
}
public class MoneyDemo {
public static void main(String[] args) {
MyMoney me = new MyMoney(99999999);
IMoneyFormat moneyFormat = i -> new DecimalFormat("#,###").format(i);
me.printMoney(moneyFormat);
}
}public static void main(String[] args) {
// 断言函数接口
Predicatefalse
这是输入的数据public static void main(String[] args) {
// 断言函数接口
IntPredicate intPredicate = i -> i > 0;
System.out.println(intPredicate.test(-9));
// 消费函数接口
IntConsumer intConsumer = (value) -> System.out.println("输入的数据是:" + value);
intConsumer.accept(123);
}false
输入的数据是:123public static void main(String[] args) {
// 提供数据接口
Supplier提供的数据是:11
计算结果为:20
计算结果为:100class MyMoney {
private final int money;
private final String name;
public MyMoney(int money, String name) {
this.money = money;
this.name = name;
}
public void printMoney(BiFunction小明的存款: 99,999,999方法引用
Arrays.sort(stringsArray, (s1, s2) -> s1.compareToIgnoreCase(s2));Arrays.sort(stringsArray, String::compareToIgnoreCase);
类型
示例
代码示例
对应的Lambda表达式
引用静态方法
ContainingClass::staticMethodName
String::valueOf
(s) -> String.valueOf(s)
引用某个对象的实例方法
containingObject::instanceMethodName
x::toString()
() -> this.toString()
引用某个类型的任意对象的实例方法
ContainingType::methodName
String::toString
(s) -> s.toString
引用构造方法
ClassName::new
String::new
() -> new String()
public class Dog {
private String name = "二哈";
private int food = 10;
public Dog() {
}
public Dog(String name) {
this.name = name;
}
public static void bark(Dog dog) {
System.out.println(dog + "叫了");
}
public int eat(int num) {
System.out.println("吃了" + num + "斤");
this.food -= num;
return this.food;
}
@Override
public String toString() {
return this.name;
}
}package org.zero01.example.demo;
import java.util.function.*;
/**
* @ProjectName demo
* @Author: zeroJun
* @Date: 2018/9/21 13:09
* @Description: 方法引用demo
*/
public class MethodRefrenceDemo {
public static void main(String[] args) {
// 方法引用,调用打印方法
Consumerlambda$0这样的函数,能够减少一些资源的开销。类型推断
所以说 Lambda 表达式的类型是从 Lambda 的上下文推断出来的,上下文中 Lambda 表达式需要的类型称为目标类型,如下图所示: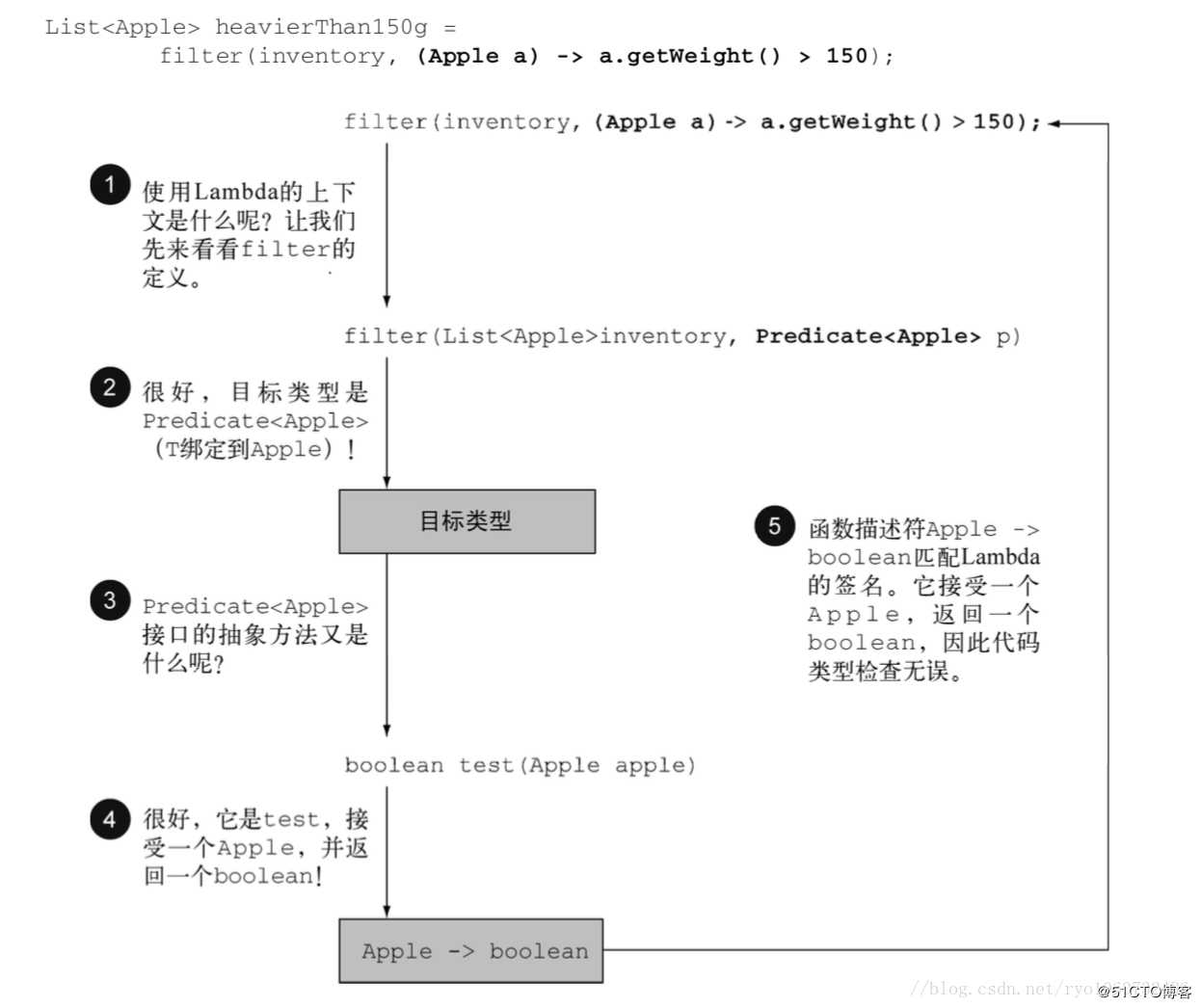
接下来我们使用一个简单的例子,演示一下 Lambda 表达式的几种类型推断,首先定义一个简单的函数接口:@FunctionalInterface
interface IMath {
int add(int x, int y);
}public class TypeDemo {
public static void main(String[] args) {
// 1.通过变量类型定义
IMath iMath = (x, y) -> x + y;
// 2.数组构建的方式
IMath[] iMaths = {(x, y) -> x + y};
// 3.强转类型的方式
Object object = (IMath) (x, y) -> x + y;
// 4.通过方法返回值确定类型
IMath result = createIMathObj();
// 5.通过方法参数确定类型
test((x, y) -> x + y);
}
public static IMath createIMathObj() {
return (x, y) -> x + y;
}
public static void test(IMath iMath){
return;
}
}变量引用
public static void main(String[] args) {
String str = "当前的系统时间戳是: ";
Consumer
至于为什么要将变量设置final,这是因为在Java里没有引用传递,变量都是值传递的。不将变量设置为final的话,如果外部变量的引用被改变了,那么最终得出来的结果就会是错误的。
若此时list变量指向了另一个对象,那么匿名类里引用的还是之前那个值对象,所以我们才需要将其设置为final防止外部变量引用改变:
而如果是引用传递的话,匿名类里对外部变量的引用就不是值对象了,而是指针指向这个外部变量: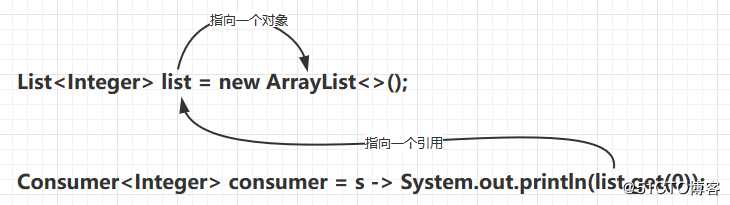
所以就算list变量指向了另一个对象,匿名类里的引用也会随着外部变量的引用改变而改变: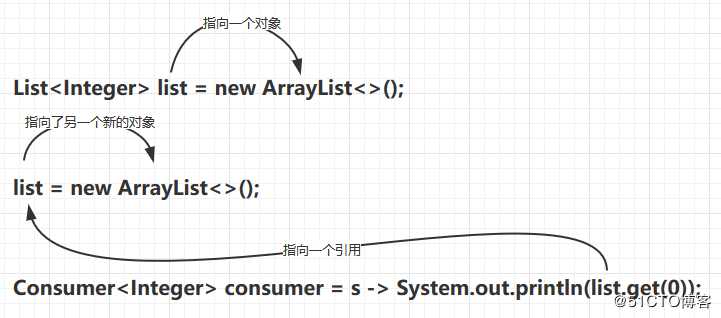
级联表达式和柯里化
// 实现了 x + y 的级联表达式
Functionx -> (y -> x + y)Functionpublic static void main(String[] args) {
Function
参考:developerworks
来源:zero菌
上一篇:Java构造方法
下一篇:Python 快速入门(1)