python实现城市和省份字典(根据城市判断属于哪个省份)
2021-05-16 12:29
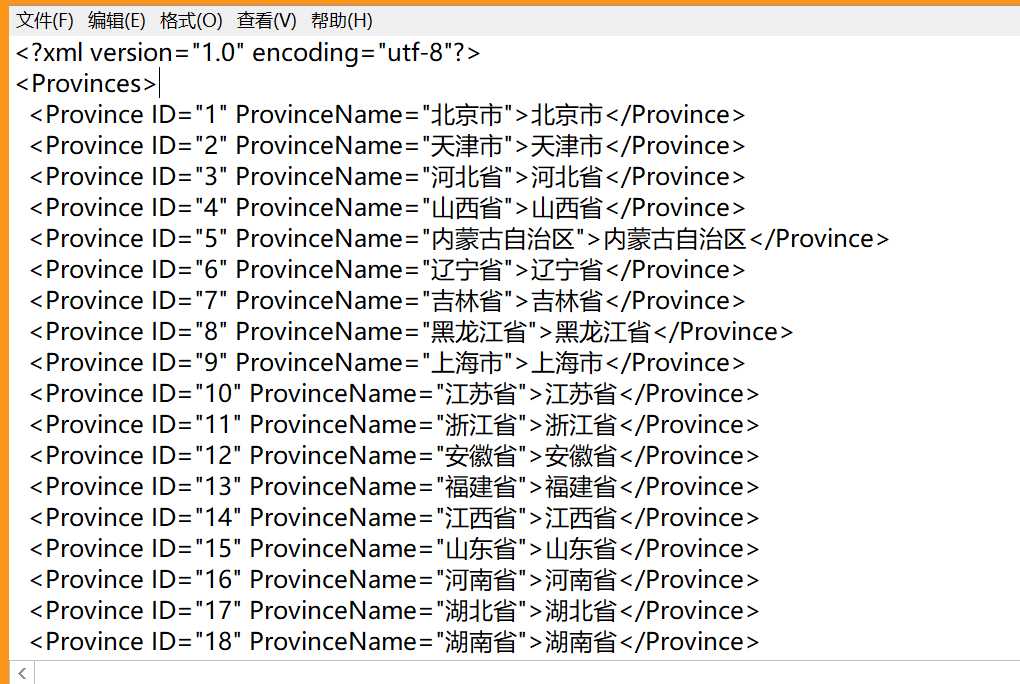
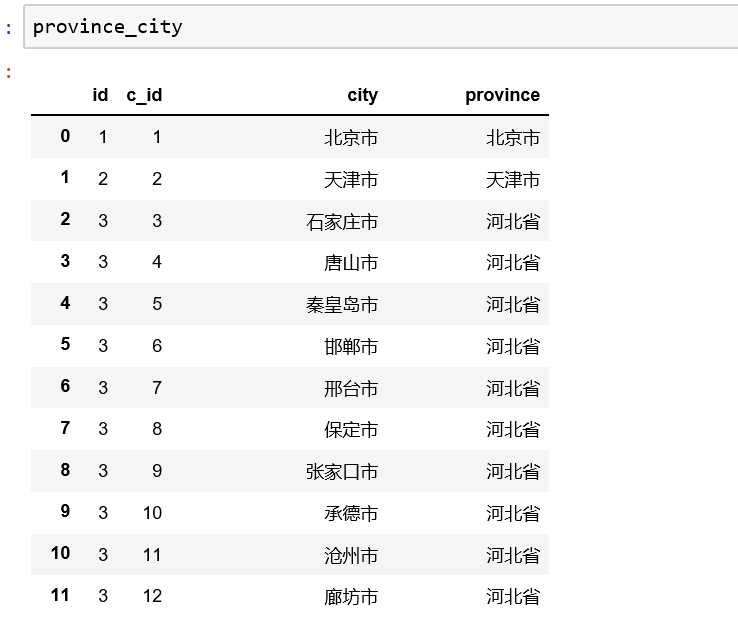
标签:dict 改变 pandas 创建 数据导入 das 去掉 def end 首先,在网上拿到一份数据,省份和城市的对应表: 第一张图是省份以及对应的ID 第二张图是省份和城市,以及分别对应的ID 基本的思路是:实现一个字典,省份作为键,省份包含的城市作为值,举个例子:{“江苏省”:“南京市”,“苏州市”,··· “徐州市”}。 下面用代码实现: 1. 改变工作目录 2.1 导入省份数据(也就是图1) 3.1 合并省份数据 2.2 导入省份和城市数据(图2) 3.2 合并城市和省份数据 4. 将上面两份数据merge在一起 得到的输出结果如下图: 5. 1 因为本人想要处理的数据里面没有“省”,“市”的后缀,所以把后缀去掉 5.2 同样,把自治区的后缀去掉 6 保存数据 7. 转为字典格式 8. 看一下初步的输出结果 到此为止,跟我们预想的完全一样 9. 接下来,我们把字典格式结果保存,方便以后 10. 看一下输出结果 python实现城市和省份字典(根据城市判断属于哪个省份) 标签:dict 改变 pandas 创建 数据导入 das 去掉 def end 原文地址:https://www.cnblogs.com/dataandmoon/p/9749322.html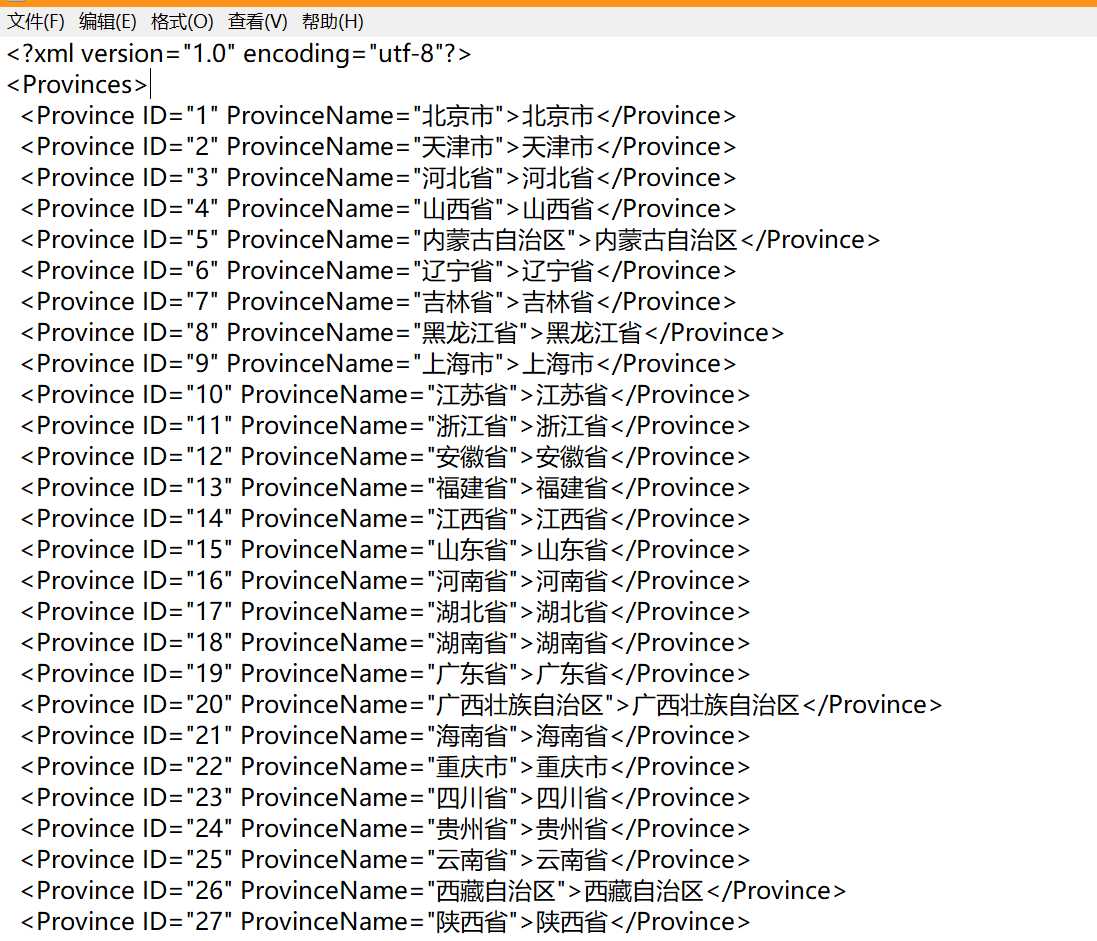
1 import os
2 import pandas as pd
3 os.chdir(r‘D:\inde\machineLearning\python\Province_city\xml‘)
with open(‘Provinces.txt‘,‘r‘,encoding=‘utf-8‘) as f:
file = f.read().strip().split(‘\n‘)
num=[]
province = []
for fi in file[2:36]:
str1 = fi.split(‘"‘)
m = str1[1]
n = str1[3]
num.append(m)
province.append(n)
province = pd.concat([pd.DataFrame(num),pd.DataFrame(province)],axis=1)
province.columns = [‘id‘,‘province‘]
province.head(2)
p_id = []
c_id = []
c_name = []
with open(‘Cities.txt‘,‘r‘,encoding=‘utf-8‘) as f:
file = f.read().strip().split(‘\n‘)
for fi in file[2:347]:
str2 = fi.split(‘"‘)
m = str2[1]
c = str2[3]
i = str2[5]
p_id.append(i)
c_id.append(m)
c_name.append(c)
city = pd.concat([pd.DataFrame(p_id),pd.DataFrame(c_id),pd.DataFrame(c_name)],axis=1)
city.columns = [‘id‘,‘c_id‘,‘city‘]
city.head(2)
province_city=pd.merge(city,province,on=‘id‘,how=‘left‘)
def delete_postfix1(s,str,zizhi=None):
if s[-1]==str:
return s[0:-1]
else:
return s
province_city.city = province_city.city.apply(lambda s:delete_postfix1(s,‘市‘))
province_city.province = province_city.province.apply(lambda s:delete_postfix1(s,‘省‘))
province_city.province = province_city.province.apply(lambda s:delete_postfix1(s,‘市‘))
def delete_postfix2(s,str):
if s[0]==‘内‘:
return s[0:3]
elif s[-3:]==str:
return s[0:2]
else:
return s
province_city.province = province_city.province.apply(lambda s:delete_postfix2(s,‘自治区‘))
province_city.province = province_city.province.apply(lambda s:delete_postfix1(s,‘省‘))
province_city.province = province_city.province.apply(lambda s:delete_postfix1(s,‘市‘))
province_city.to_csv(‘province_city.csv‘,index=0)
dicts = {}
for i in range(len(province.province)):
k=province.province[i]
province.id[i]==province_city.id
v=list(province_city[province.id[i]==province_city.id].city)
dict = {k:v}
dicts.update(dict)

import pickle #导入pickle
pickle_file = open("dicts.pkl", "wb") # 创建一个pickle文件,但是打开方式必须是wb,二进制格式
pickle.dump(dicts,pickle_file ) # 数据导入文件
pickle_file.close()
pickle_file = open("dicts.pkl", "rb")
mylist2 = load(pickle.file)
pickle_file.close()

下一篇:python优雅编程之旅
文章标题:python实现城市和省份字典(根据城市判断属于哪个省份)
文章链接:http://soscw.com/essay/86248.html