Python数据挖掘—回归—贝叶斯分类
2021-05-18 00:29
标签:自带 font type 贝叶斯 string ber ast 课程 ike 该方法可以将类别变量转换成新增的虚拟变量/指示变量 下面通过例子来进一步说明get_dummies() 1、首先构造一个数据列 1、两个变量:s为Series、s_1为DataFrame 2、去除第一列 得到: 3、查看dummy_na功能 创建数据 结果为: 结果为: 4、创建数据框 结果为: drop_first后 步骤: 知识点: Categorical Type:什么是categorical Type?不知道确切的英文翻译,但是可以按照字面意思来也就是分类数据,比如皮肤的颜色,可以分为黄色,白色,黑色等等,但是这些数据的均值以及数值计算比如加减的结果是没有意义的;但是我们可以将不同的数据分为这几类,在比如人类的性别,男女也属于categorical 类别; 英文中欧冠也可以称之为Nominal Data. 上述代码:建模,构造伯努利方程,设置自变量和因变量,训练变量,得到训练集 训练: Python数据挖掘—回归—贝叶斯分类 标签:自带 font type 贝叶斯 string ber ast 课程 ike 原文地址:https://www.cnblogs.com/U940634/p/9745737.htmlpandas之get_dummies
方法:pandas.get_dummies(data,prefix=None,prefix_sep="_",dummy_na=False,columns=None,sparse=False,drop_first=False)
参数说明:
data:array-like、Series 、 DataFrame , 输入数据
prefix:string、list of strings、dict of strings ,default为None,get_dummies转换后,列名的前缀
columns:list-like, default为False,指定需要实现类别转换的列名
dummy_na:bool, default为False,增加一列表示空缺值,如果False就忽略空缺值
drop_first:fool,default为False ,获取K中的K-1个类别之,去除第一个
举例:
1 import pandas as pd
2 s=pd.Series(list(‘abca‘))
3
4 s_1=pd.get_dummies(s)
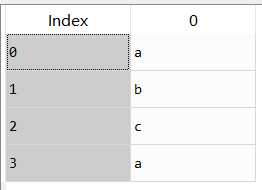 变成→
变成→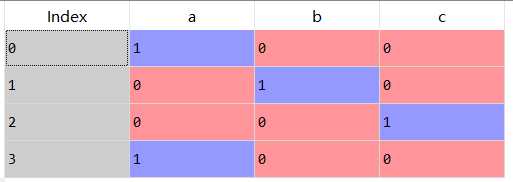
1 b=pd.get_dummies(s,drop_first=True)
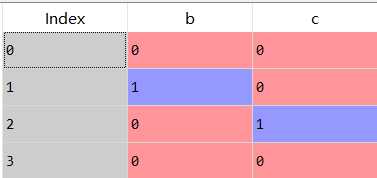
1 import numpy as np
2 s_2=["a","b",np.nan]

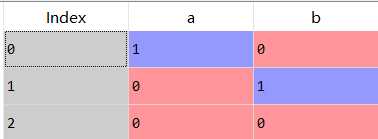
1 pd.get_dummies(s_2,dummy_na=True)
2 pd.get_dummies(s_2,dummy_na=False)
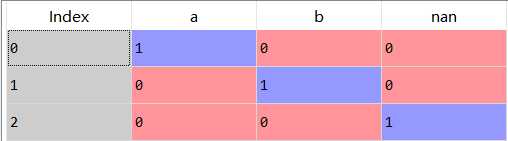 、
、
1 df=pd.DataFrame({
2 "A":["a","b","a"],"B":["b","a","c"],
3 "C":[1,2,3]})
4 pd.get_dummies(df,prefix=["col_1","col_2"])
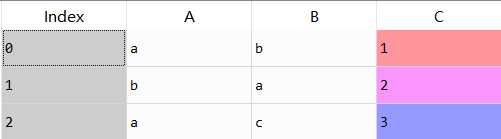 变为→
变为→
实例:
1 import pandas
2
3 data=pandas.read_csv(
4 "C:\\Users\\Jw\\Desktop\\python_work\\Python数据挖掘实战课程课件\\5.2\\data1.csv",
5 encoding=‘utf-8‘)
6
7
8 dummyColumns=[‘症状‘,‘职业‘]
9
10 for column in dummyColumns:
11 data[column]=data[column].astype(‘category‘)
12
13
14 dummiesData=pandas.get_dummies(
15 data,
16 columns=dummyColumns,
17 prefix=dummyColumns,
18 prefix_sep=‘ ‘)
19
20 dummiesData=pandas.get_dummies(
21 data,
22 columns=dummyColumns,
23 prefix=dummyColumns,
24 prefix_sep=‘ ‘,
25 drop_first=True)
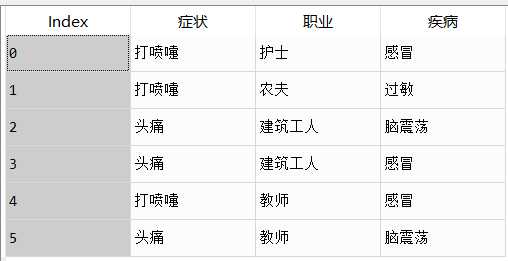 构造虚拟变量
构造虚拟变量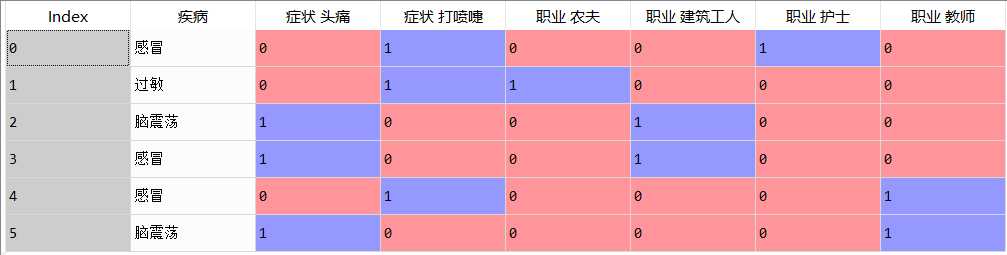
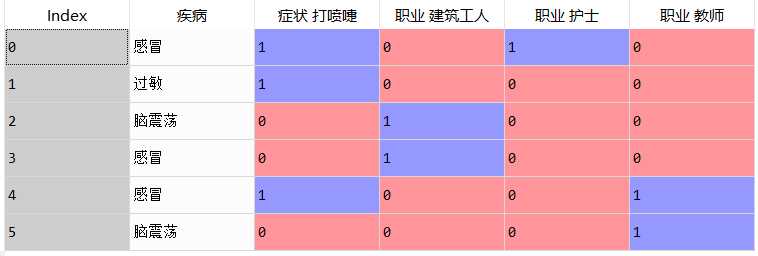
实例
1 import pandas;
2
3 data = pandas.read_csv(
4 "C:\\Users\\Jw\\Desktop\\python_work\\Python数据挖掘实战课程课件\\5.2\\data1.csv",
5 encoding=‘utf8‘
6 )
7
8 dummyColumns = [‘症状‘, ‘职业‘]
9
10 for column in dummyColumns:
11 data[column]=data[column].astype(‘category‘)
12
13 dummiesData = pandas.get_dummies( #调用get_dummyColumns方法进行不可比较大小虚拟变量的转换
14 data,
15 columns=dummyColumns,
16 prefix=dummyColumns,
17 prefix_sep=" "
18 )
19
20 dummiesData = pandas.get_dummies(
21 data,
22 columns=dummyColumns,
23 prefix=dummyColumns,
24 prefix_sep=" ",
25 drop_first=True
26 )
1 #伯努利贝叶斯
2 from sklearn.naive_bayes import BernoulliNB
3 BNBModel = BernoulliNB()
4
5 fNames = [‘症状 打喷嚏‘, ‘职业 建筑工人‘, ‘职业 护士‘, ‘职业 教师‘]
6 tData = dummiesData[‘疾病‘]
7 fData = dummiesData[fNames]
8
9 BNBModel.fit(fData, tData)
1 #病症是打喷嚏的建筑工人
2 newData = pandas.DataFrame({
3 ‘症状‘:[‘打喷嚏‘],
4 ‘职业‘:[‘建筑工人‘]
5 })
6
7 for column in dummyColumns:
8 newData[column] = newData[column].astype(
9 ‘category‘,
10 categories=data[column].cat.categories
11 )
12
13 dummiesNewData = pandas.get_dummies(
14 newData,
15 columns=dummyColumns,
16 prefix=dummyColumns,
17 prefix_sep=" ",
18 drop_first=True
19 )
20
21 pData = dummiesNewData[fNames]
22 BNBModel.predict(pData)
1 #病症是打喷嚏的建筑工人
2 newData=pandas.DataFrame({
3 ‘症状‘:[‘打喷嚏‘],
4 ‘职业‘:[‘建筑工人‘]})
5
6 for column in dummyColumns:
7 newData[column]=newData[column].astype(
8 ‘category‘,
9 categories=data[column].cat.categories
10 )
11
12 dummiesNewData=pandas.get_dummies(
13 newData,
14 columns=dummyColumns,
15 prefix=dummyColumns,
16 prefix_sep=‘ ‘,
17 drop_first=True)
18
19 pData=dummiesNewData[fNames]
20 BNBModel.predict(pData)