在AWS Glue中使用Apache Hudi
2021-05-29 05:12
标签:并发控制 multipart 存储 是的 lse mit href pack details AWS Glue是Amazon Web Services(AWS)云平台推出的一款无服务器(Serverless)的大数据分析服务。对于不了解该产品的读者来说,可以用一句话概括其实质:Glue是一个无服务器的全托管的Spark运行环境,只需提供Spark程序代码即可运行Spark作业,无需维护集群。 Apache Hudi最早由Uber设计开发,后提交给Apache孵化器,2020年5月,Hudi正式升级为Apache的顶级项目。Hudi是一个数据湖平台,支持增量数据处理,其提供的更新插入和增量查询两大操作原语很好地弥补了传统大数据处理引擎(如Spark、Hive等)在这方面的缺失,因而受到广泛关注并开始流行。此外,Hudi在设计理念上非常注意与现有大数据生态的融合,它能以相对透明和非侵入的方式融入到Spark、Flink计算框架中,并且支持了流式读写,有望成为未来数据湖的统一存储层(同时支持批流读写)。 鉴于Hudi的日益流行,很多正在使用Glue或者为搭建无服务器数据湖进行技术选型的团队对Glue与Hudi的集成非常关心,如果两者可以成功地集成在一起,团队就可以建设出支持增量数据处理的无服务器架构的新一代数据湖。 但是,AWS Glue的产品团队从未就支持Hudi给出过官方保证,虽然从“Glue内核是Spark”这一事实进行推断,理论上Glue是可以与Hudi集成的,但由于Glue没有使用Hive的Metastore,而是依赖自己的元数据存储服务Glue Catalog,这会让Glue在同步Hudi元数据时遇到不小的麻烦。 本文将在代码验证的基础之上,详细介绍如何在Glue里使用Hudi,对集成过程中发现的各种问题和错误给出解释和应对方案。我们希望通过本文的介绍,给读者在数据湖建设的技术选型上提供新的灵感和方向。无论如何,一个支持增量数据处理的无服务器架构的数据湖是非常吸引人的! 注:本文讨论和编写的程序代码基于的都是 现在,我们来演示如何在Glue中创建并运行一个基于Hudi的作业。我们假定读者具有一定的Glue使用经验,因此不对Glue的基本操作进行解释。 在开始之前,我们把本文使用的各类资源汇总如下,便于读者统一下载。 为配合本文的讲解,我们专门编写了一个示例程序并存放在Github上,详情如下: 运行程序需要使用到Hudi和Spark的两个Jar包,由于包文件较大,无法存放在Github的Repository里,建议大家从Maven的中心库下载,以下是链接信息: 根据Hudi官方给出的集成原生Spark的方式(链接:https://hudi.apache.org/docs/quick-start-guide.html#setup-spark-shell): 可知,将Hudi加载到Spark运行环境中需要完成两个关键动作: 由此,不难推理出Glue集成Hudi的方法,即以Glue的方式实现上述两个操作。下面我们进入实操环节。 首先,在S3上创建一个供本示例使用的桶,取名 接下来,进入Glue控制台,添加一个作业,在“添加作业”向导中进行如下配置: 如下图所示: 然后向下滚动进入到“安全配置、脚本库和作业参数(可选)”环节,在“从属JAR路径”的输入框中将前面上传到桶里的两个依赖Jar包的S3路径(记住,中间要使用逗号分隔): 粘贴进去。如下图所示: 这里是前文提及的集成Hudi的两个关键性操作中的第一个:将Hudi的Jar包引入到Glue的类路径中。这与在spark-shell命令行中配置package参数效果是等价的: 再接下来,在“作业参数”环节,添加一个作业参数: 如下图所示: 我们需要把S3桶的名称以“作业参数”的形式传给示例程序,以便其可以拼接出Hudi数据集的完整路径,这个值会在读写Hudi数据集时使用,因为Hudi数据集会被写到这个桶里。 最后,在“目录选项”中勾选 全部操作完成后,点击“下一步”,再点击“保存并编辑脚本”就会进入到脚本编辑页面,页面将会展示上传的 接下来,我们从编程角度看一下如何在Glue中使用Hudi,具体就是以 首先,需要我们得先了解一下 作为一份示例性质的代码, 以下是 该处代码正是前文提及的集成Hudi的第二个关键性操作:在Spark中配置Hudi需要的Kyro序列化器: 下面,我们要把关注重点放在Glue是如何读写Hudi数据集的,也就是 因为代码中设置了 所以该方法使用的是Hudi最简单也是最常用的一种读取方式:快照读取,即:读取当前数据集最新状态的快照。关于读取Hudi数据集的更多内容,请参考Hudi官方文档:https://hudi.apache.org/docs/querying_data.html 。接下来是写操作: 写操作中大部分的代码都是在对Hudi进行一些必要的配置,这些配置包括: 这些都是Hudi的基本配置,本文不再一一解释,请读者参考Hudi的官方文档:https://hudi.apache.org/docs/writing_data.html 上述读写操作并没有同步元数据,在实际应用中,大多数情况下,开发者会开启Hudi的Hive Sync功能,让Hudi将其元数据映射到Hive Metastore中,自动创建Hive表,这是一个很有用的操作。不过,对于Glue来说,这个问题就比较棘手了,基于笔者的使用经历,早期遇到的大部分问题都出在了同步元数据上,究其原因,主要是因为Glue使用了自己的元数据服务Glue Catalog,而Hudi的元数据同步是面向Hive Metastore的。那这是否意味着Hudi就不能把元数据同步到Glue上呢?幸运的是,在经过各种尝试和摸索之后,我们还是顺利地完成了这项工作,这为Hudi在Glue上的应用铺平了道路。 在介绍具体操作之前,我们先了解一下Hudi同步元数据到Hive的基本操作。根据官方文档: https://hudi.apache.org/docs/configurations.html#hive-sync-options给出的说明,标准的Hudi Hive Sync配置应该是这样的: 首先是最基本的三项: 这三项很容易理解,就是告诉Hudi要开启Hive Sync,同时指定同步到Hive的什么库里的什么表。如果你要同步的是一张分区表,还需要追加以下几项: 这些配置项主要在告诉Hudi数据集的分区信息,以便Hudi能正确地将分区相关的元数据也同步到Hive Metastore中。现在,我们看一下在Glue中要怎样实现元数据同步,也就是示例代码中的 该方法的实现在 是前面没有提到的,而这一项配置是在Glue下同步元数据至关重要的。如果不进行此项配置,我们一定会遇到这样一个错误: 这是因为:Hudi的Hive Sync默认是通过JDBC连接HiveServer2执行建表操作的,而 那为什么在禁用JDBC方式连接Hive Metastore之后,就可以同步了呢?通过查看Hudi的源代码可知,当 而在Glue这一侧,由于其使用了自己的Metastore:Glue Catalog,为了和上层Hive相关的基础设施进行兼容,Glue提供了一个自己的 该类实现了 从Github AwsLab释出的Glue Catalog的部分源码中,可以找到这个类的实现(地址:https://github.com/awslabs/aws-glue-data-catalog-client-for-apache-hive-metastore/blob/master/aws-glue-datacatalog-spark-client/src/main/java/com/amazonaws/glue/catalog/metastore/AWSGlueDataCatalogHiveClientFactory.java): 和我们的猜测完全一致。所以,梳理下来整件事情是这样的:当禁用Hive JDBC之后,Hudi会转而使用一个客户端(即某个 最后,让我们来运行一下这个作业,看一看输出的日志和同步出的数据表。回到Glue控制台,在前面停留的“脚本编辑”页面上,点击“运行作业”按钮,即可执行作业了。在作业运行结束后,可以在“日志”Tab页看到程序打印的信息,如下图所示: 其中 以及列信息: 它的输入/输出格式以及5个 该问题在3.2节已经提及,是由于没有配置 该问题在3.3节已经提及,须在Hudi中禁用Hive JDBC,请参考前文。 这是一个非常棘手的问题,笔者曾在这个问题上耽误了不少时间,并研究了Hudi同步元数据的大部分代码,坦率地说,目前它的触发机制还不是非常确定,主要原因是在Glue这种无服务器环境下不方便进行远程DEBUG,只能通过日志进行分析。一个大概率的怀疑方向是:在整个SparkSession的上下文中,由于某一次Hudi的读写操作没能正确地关闭并释放 这一操作非常有效,它主动销毁了绑定在当前线程上的 关于这一问题更深入的分析和研究,可参考笔者的另一篇文章《AWS Glue集成Apache Hudi同步元数据深度历险(各类错误的填坑方案)》 该问题与上一个问题是一样的,只是处在异常堆栈的不同位置上,解决办法同上。 虽然本文篇幅较长,但是从 关于作者:耿立超,架构师,15年IT系统开发和架构经验,对大数据、企业级应用架构、SaaS、分布式存储和领域驱动设计有丰富的实践经验,热衷函数式编程。对Hadoop/Spark 生态系统有深入和广泛的了解,参与过Hadoop商业发行版的开发,曾带领团队建设过数个完备的企业数据平台,个人技术博客:https://laurence.blog.csdn.net/ 作者著有《大数据平台架构与原型实现:数据中台建设实战》一书,该书已在京东和当当上线。 在AWS Glue中使用Apache Hudi 标签:并发控制 multipart 存储 是的 lse mit href pack details 原文地址:https://www.cnblogs.com/leesf456/p/14749099.html1. Glue与Hudi简介
2. 集成的可行性分析
Glue 2.0(基于Spark 2.4.3)和Hudi 0.8.0,两者均为当前(2021年4月)各自的最新版本。3. 在Glue作业中使用Hudi
3.1. 资源列表
3.1.1. 示例程序
项目名称
Repository地址
glue-hudi-integration-example
https://github.com/bluishglc/glue-hudi-integration-example
3.1.2. 依赖JAR包
Jar包
下载链接
hudi-spark-bundle_2.11-0.8.0.jar
https://search.maven.org/remotecontent?filepath=org/apache/hudi/hudi-spark-bundle_2.11/0.8.0/hudi-spark-bundle_2.11-0.8.0.jar
spark-avro_2.11-2.4.3.jar
https://search.maven.org/remotecontent?filepath=org/apache/spark/spark-avro_2.11/2.4.3/spark-avro_2.11-2.4.3.jar
3.2. 创建基于Hudi的Glue作业
spark-shell --packages org.apache.hudi:hudi-spark-bundle_2.11:0.8.0,org.apache.spark:spark-avro_2.11:2.4.3 --conf ‘spark.serializer=org.apache.spark.serializer.KryoSerializer‘
hudi-spark-bundle_2.11-0.8.0.jar和spark-avro_2.11-2.4.3.jar
spark.serializer=org.apache.spark.serializer.KryoSerializer
3.2.1. 创建桶并上传程序和依赖包
glue-hudi-integration-example。要注意的是:为避免桶名冲突,你应该定义并使用自己的桶,并在后续操作中将所有出现glue-hudi-integration-example的配置替换为自己的桶名。然后,从Github检出专门为本文编写的Glue读写Hudi的示例程序(地址参考3.1.1节),将项目中的GlueHudiReadWriteExample.scala文件上传到新建的桶里。同时,下载hudi-spark-bundle_2.11-0.8.0.jar和spark-avro_2.11-2.4.3.jar两个Jar包(地址参考3.1.2节),并同样上传到新建的桶里。操作完成后,S3上的glue-hudi-integration-example桶应该包含内容: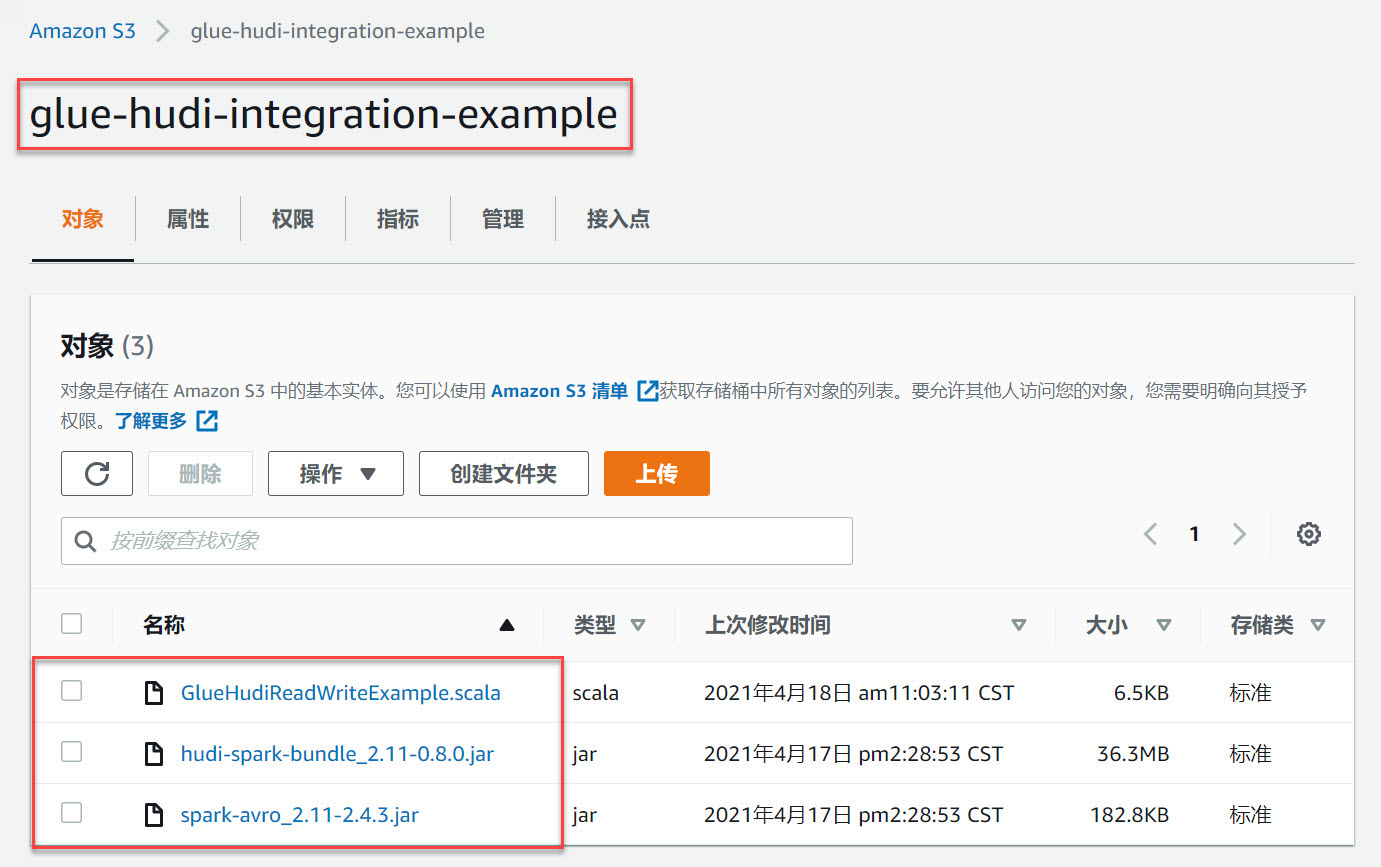
3.2.2. 添加作业
glue-hudi-integration-example;glue-hudi-integration-example桶和访问Glue服务的权限,如果没有现成的合适角色,需要去IAM控制台创建一个,本处不再赘述;com.github.GlueHudiReadWriteExample和s3://glue-hudi-integration-example/GlueHudiReadWriteExample.scala;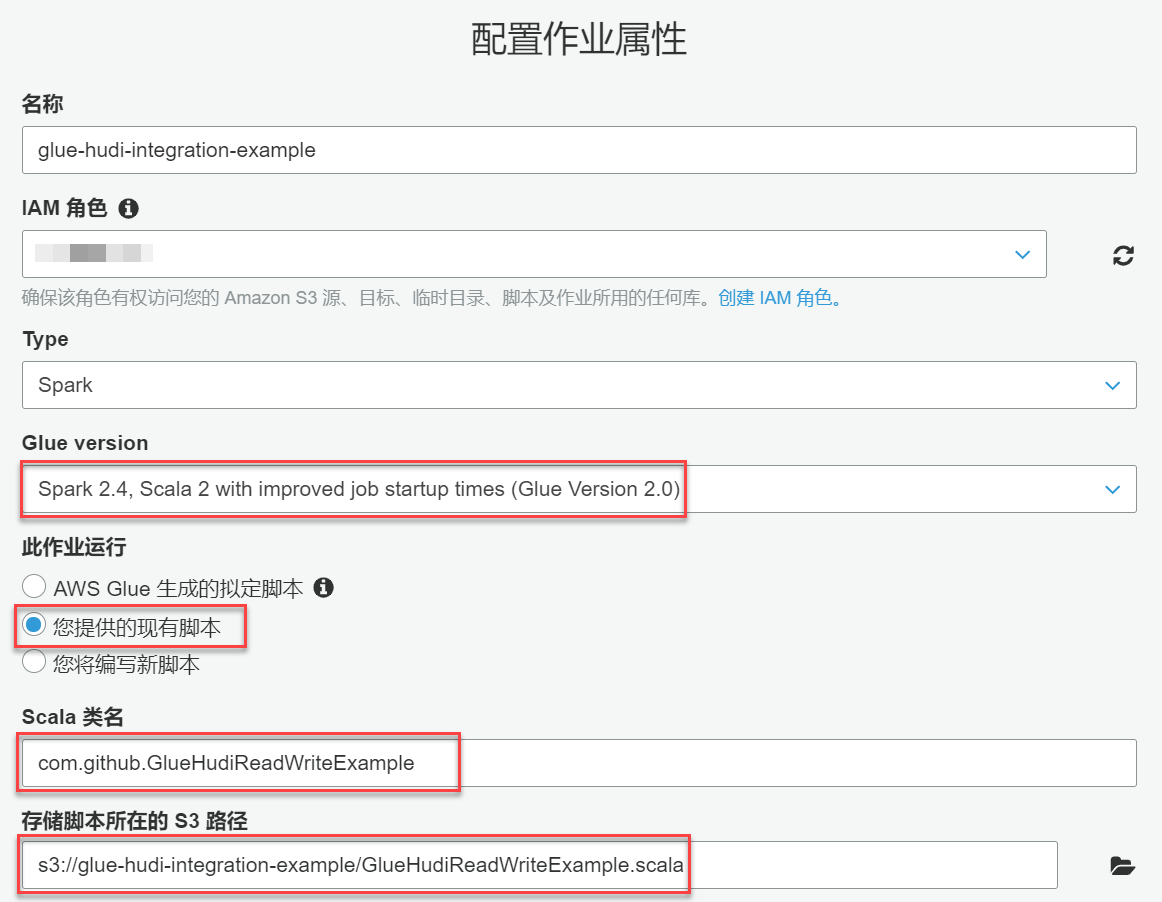
s3://glue-hudi-integration-example/hudi-spark-bundle_2.11-0.8.0.jar,s3://glue-hudi-integration-example/spark-avro_2.11-2.4.3.jar

--packages org.apache.hudi:hudi-spark-bundle_2.11:0.8.0,org.apache.spark:spark-avro_2.11:2.4.3
键名
取值
--bucketName
glue-hudi-integration-example
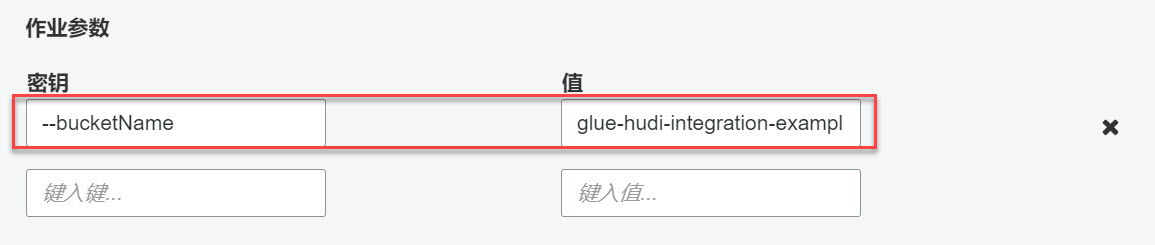
Use Glue data catalog as the Hive metastore,启用Glue Catalog:
GlueHudiReadWriteExample.scala这个类的源代码。3.3. 在Glue作业中读写Hudi数据集
GlueHudiReadWriteExample.scala这个类的实现为主轴,介绍几个重要的技术细节。GlueHudiReadWriteExample.scala这个类的主线逻辑,即main方法中的操作:def main(sysArgs: Array[String]): Unit = {
init(sysArgs)
val sparkImplicits = spark.implicits
import sparkImplicits._
// Step 1: build a dataframe with 2 user records, then write as
// hudi format, but won‘t create table in glue catalog
val users1 = Seq(
User(1, "Tom", 24, System.currentTimeMillis()),
User(2, "Bill", 32, System.currentTimeMillis())
)
val dataframe1 = users1.toDF
saveUserAsHudiWithoutHiveTableSync(dataframe1)
// Step 2: read just saved hudi dataset, and print each records
val dataframe2 = readUserFromHudi()
val users2 = dataframe2.as[User].collect().toSeq
println("printing user records in dataframe2...")
users2.foreach(println(_))
// Step 3: append 2 new user records, one is updating Bill‘s age from 32 to 33,
// the other is a new user whose name is ‘Rose‘. This time, we will enable
// hudi hive syncing function, and a table named `user` will be created on
// default database, this action is done by hudi automatically based on
// the metadata of hudi user dataset.
val users3 = users2 ++ Seq(
User(2, "Bill", 33, System.currentTimeMillis()),
User(3, "Rose", 45, System.currentTimeMillis())
)
val dataframe3 = users3.toDF
saveUserAsHudiWithHiveTableSync(dataframe3)
// Step 4: since a table is created automatically, now, we can query user table
// immediately, and print returned user records, printed messages should show:
// Bill‘s is updated, Rose‘s record is inserted, this demoed UPSERT feature of hudi!
val dataframe4 = spark.sql("select * from user")
val users4 = dataframe4.as[User].collect().toSeq
println("printing user records in dataframe4...")
users4.foreach(println(_))
commit()
}
main方法的逻辑是“为了演示”而设计的,一共分成了四步操作:
User数据的Dataframe,取名dataframe1,然后将其以Hudi格式保存到S3上,但并不会同步元数据(也就是不会自动建表);dataframe2,此时它应该包含前面创建的两条User数据;dataframe2的基础上再追加两条User数据,一条是针对现有数据Bill用户的更新数据,另一条Rose用户的是新增数据,进而得到第三个dataframe3,然后将其再次以Hudi格式写回去,但是与上次不同的是,这一次程序将使用Hudi的元数据同步功能,将User数据集的元数据同步到Glue Catalog,一张名为user的表将会被自动创建出来;user表,得到第四个Dataframe:dataframe4,其不但应该包含数据,且更新和插入数据都必须是正确的。main方法的具体实现:def main(sysArgs: Array[String]): Unit = {
init(sysArgs)
val sparkImplicits = spark.implicits
import sparkImplicits._
// Step 1: build a dataframe with 2 user records, then write as
// hudi format, but won‘t create table in glue catalog
val users1 = Seq(
User(1, "Tom", 24, System.currentTimeMillis()),
User(2, "Bill", 32, System.currentTimeMillis())
)
val dataframe1 = users1.toDF
saveUserAsHudiWithoutHiveTableSync(dataframe1)
// Step 2: read just saved hudi dataset, and print each records
val dataframe2 = readUserFromHudi()
val users2 = dataframe2.as[User].collect().toSeq
println("printing user records in dataframe2...")
users2.foreach(println(_))
// Step 3: append 2 new user records, one is updating Bill‘s age from 32 to 33,
// the other is a new user whose name is ‘Rose‘. This time, we will enable
// hudi hive syncing function, and a table named `user` will be created on
// default database, this action is done by hudi automatically based on
// the metadata of hudi user dataset.
val users3 = users2 ++ Seq(
User(2, "Bill", 33, System.currentTimeMillis()),
User(3, "Rose", 45, System.currentTimeMillis())
)
val dataframe3 = userS3.toDF
saveUserAsHudiWithHiveTableSync(dataframe3)
// Step 4: since a table is created automatically, now, we can query user table
// immediately, and print returned user records, printed messages should show:
// Bill‘s is updated, Rose‘s record is inserted, this demoed UPSERT feature of hudi!
val dataframe4 = spark.sql("select * from user")
val users4 = dataframe4.as[User].collect().toSeq
println("printing user records in dataframe4...")
users4.foreach(println(_))
commit()
}
main在开始时调用了一个init函数,改函数会完成一些必要初始化工作,如:解析并获取作业参数,创建GlueContext和SparkSession实例等。其中有一处代码需要特别说明,即类文件的第90-92行,也就是下面代码中的第10-12行:/**
* 1. Parse job params
* 2. Create SparkSession instance with given configs
* 3. Init glue job
*
* @param sysArgs all params passing from main method
*/
def init(sysArgs: Array[String]): Unit = {
...
val conf = new SparkConf()
// This is required for hudi
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
...
}
spark.serializer=org.apache.spark.serializer.KryoSerializer。如果没有配置该项,程序将会报出如下错误:org.apache.hudi.exception.HoodieException : hoodie only support org.apache.spark.serializer.KryoSerializer as spark.serializer
readUserFromHudi和saveUserAsHudiWithoutHiveTableSync两个方法的实现。首先看一下较为简单的读取操作:/**
* Read user records from Hudi, and return a dataframe.
*
* @return The dataframe of user records
*/
def readUserFromHudi(): DataFrame = {
spark
.read
.format("hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_SNAPSHOT_OPT_VAL)
.load(userTablePath)
}
option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_SNAPSHOT_OPT_VAL)
/**
* Save a user dataframe as hudi dataset, but WON‘T SYNC its metadata to glue catalog,
* In other words, no table will be created after saving.
*
* @param dataframe The dataframe to be saved
*/
def saveUserAsHudiWithoutHiveTableSync(dataframe: DataFrame) = {
val hudiOptions = Map[String, String](
HoodieWriteConfig.TABLE_NAME -> userTableName,
DataSourceWriteOptions.OPERATION_OPT_KEY -> DataSourceWriteOptions.UPSERT_OPERATION_OPT_VAL,
DataSourceWriteOptions.TABLE_TYPE_OPT_KEY -> DataSourceWriteOptions.COW_TABLE_TYPE_OPT_VAL,
DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY -> userRecordKeyField,
DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY -> userPrecombineField,
DataSourceWriteOptions.KEYGENERATOR_CLASS_OPT_KEY -> classOf[NonpartitionedKeyGenerator].getName
)
dataframe
.write
.format("hudi")
.options(hudiOptions)
.mode(SaveMode.Append)
.save(userTablePath)
}
RECORDKEY_FIELD_OPT_KEY和PRECOMBINE_FIELD_OPT_KEY;3.4. 将Hudi元数据同步到Glue Catalog
DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY -> "true"
DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY -> "your-target-database"
DataSourceWriteOptions.HIVE_TABLE_OPT_KEY -> "your-target-table"
DataSourceWriteOptions.KEYGENERATOR_CLASS_OPT_KEY -> classOf[ComplexKeyGenerator].getName
DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY -> classOf[MultiPartKeysValueExtractor].getName
DataSourceWriteOptions.HIVE_STYLE_PARTITIONING_OPT_KEY -> "true"
DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY -> "your-partition-path-field"
DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY -> "your-hive-partition-field"
saveUserAsHudiWithHiveTableSync方法:/**
* Save a user dataframe as hudi dataset, but also SYNC its metadata to glue catalog,
* In other words, after saving, a table named `default.user` will be created automatically by hudi hive sync
* tool on Glue Catalog!
*
* @param dataframe The dataframe to be saved
*/
def saveUserAsHudiWithHiveTableSync(dataframe: DataFrame) = {
val hudiOptions = Map[String, String](
HoodieWriteConfig.TABLE_NAME -> userTableName,
DataSourceWriteOptions.OPERATION_OPT_KEY -> DataSourceWriteOptions.UPSERT_OPERATION_OPT_VAL,
DataSourceWriteOptions.TABLE_TYPE_OPT_KEY -> DataSourceWriteOptions.COW_TABLE_TYPE_OPT_VAL,
DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY -> userRecordKeyField,
DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY -> userPrecombineField,
DataSourceWriteOptions.KEYGENERATOR_CLASS_OPT_KEY -> classOf[NonpartitionedKeyGenerator].getName,
DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY -> classOf[NonPartitionedExtractor].getName,
// Register hudi dataset as hive table (sync meta data)
DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY -> "true",
DataSourceWriteOptions.HIVE_USE_JDBC_OPT_KEY -> "false", // For glue, it is required to disable sync via hive jdbc!
DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY -> "default",
DataSourceWriteOptions.HIVE_TABLE_OPT_KEY -> userTableName
)
dataframe
.write
.format("hudi")
.options(hudiOptions)
.mode(SaveMode.Append)
.save(userTablePath)
}
saveUserAsHudiWithoutHiveTableSync的基础之上,追加了四个与同步元数据相关的配置项,基中三项是前面提到的必填项,唯独:DataSourceWriteOptions.HIVE_USE_JDBC_OPT_KEY -> "false"
Cannot create hive connection jdbc:hive2://localhost:10000/
jdbc:hive2://localhost:10000/是Hudi配置的默认Hive JDBC连接字符串(这个字符串当然是可修改的,对应配置项为hive_sync.jdbc_url)。由于在Glue里没有Hive Metastore和HiverServer2,所以报错是必然的。HIVE_USE_JDBC_OPT_KEY被置为false时,Hudi会转而使用一个专职的IMetaStoreClient去与对应的Metastore进行交互。在Hudi同步元数据的主要实现类org.apache.hudi.hive.HoodieHiveClient中,维护着一个私有成员变量private IMetaStoreClient client,Hudi就是使用这个Client去和Metastore交互的,在HoodieHiveClient中有多处代码都是先判断是否开启了JDBC,如果是true,则通过JDBC做交互,如果是false,就使用Client,例如org.apache.hudi.hive.HoodieHiveClient#getTableSchema方法就是依此逻辑实现的:public class HoodieHiveClient extends AbstractSyncHoodieClient {
...
private IMetaStoreClient client;
...
public MapIMetaStoreClient实现用于与Glue Catalog交互,这个实现就是com.amazonaws.glue.catalog.metastore.AWSCatalogMetastoreClient(参考:https://github.com/awslabs/aws-glue-data-catalog-client-for-apache-hive-metastore/blob/master/aws-glue-datacatalog-hive2-client/src/main/java/com/amazonaws/glue/catalog/metastore/AWSCatalogMetastoreClient.java):public class AWSCatalogMetastoreClient implements IMetaStoreClient {
...
}
IMetaStoreClient接口。所以只要使用的是AWSCatalogMetastoreClient这个客户端,就能用Hive Metastore的交互方式和Glue Catalog进行交互(这得感谢Hive设计了IMetaStoreClient这个接口,而不是给出一个实现类)。在Spark中,有spark.hadoop.hive.metastore.client.factory.class这样一项配置,顾名思义,这一配置就是告诉Spark使用哪一个工厂类来生产Hive Metastore的Client了,所以你应该大概率猜到了,在Glue里,这个配置应该是被修改了,配置的应该是某个Glue自己实现的工厂类,用于专门生产AWSCatalogMetastoreClient。是的,的确如此,在Glue里这一项是这样配置的:spark.hadoop.hive.metastore.client.factory.class=com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory
public class AWSGlueDataCatalogHiveClientFactory implements HiveMetaStoreClientFactory {
@Override
public IMetaStoreClient createMetaStoreClient(
HiveConf conf,
HiveMetaHookLoader hookLoader
) throws MetaException {
AWSCatalogMetastoreClient client = new AWSCatalogMetastoreClient(conf, hookLoader);
return client;
}
}
IMetaStoreClient接口的实现类)与Metastore进行交互,而在Glue环境里,Glue提供了一个遵循IMetaStoreClient接口规范,但却是与Glue Catalog 进行交互的客户端类AWSCatalogMetastoreClient。这样,Hudi就能通过这个客户端与Glue Catalog进行透明交互了!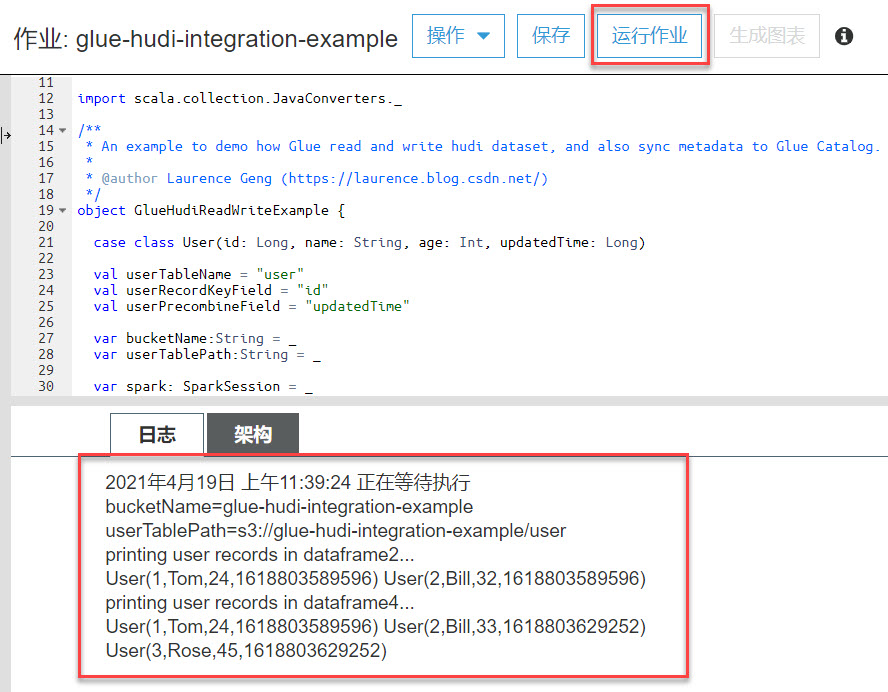
dataframe4的数据很好地体现了Hudi的UPSERT能力,程序按照我们期望的逻辑执行出了结果:Bill的年龄从32更新为了33,新增的Rose用户也出现在了结果集中。于此同时,在Glue控制台的Catalog页面上,也会看到同步出来的user表: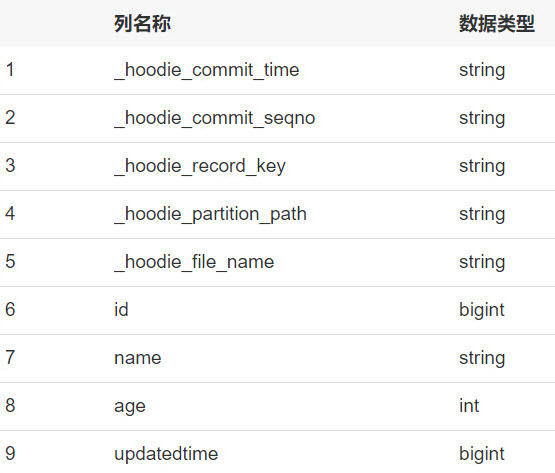
_hoodie开头的列名清楚地表明这是一张基于Hudi元数据映射出来的表。5. 常见错误
5.1.
hoodie only support KryoSerializer as spark.serializer
spark.serializer=org.apache.spark.serializer.KryoSerializer所致,请参考前文。5.2.
Cannot create hive connection jdbc:hive2://localhost:10000/
5.3.
Got runtime exception when hive syncing ...
IMetaStoreClient实例,导致后面需要再使用该Client同步元数据时,其已经不可用。不过,相比尚不确定的起因,其解决方案是非常清晰和确定的,即:在出错的位置前追加一行代码:Hive.closeCurrent()
org.apache.hadoop.hive.ql.metadata.Hive实例,该类的实例是存放在一个ThreadLocal变量里的,而它本身又会包含一个IMetaStoreClient实例,所以Hive实例中的Metastore客户端也是一个线程只维护一个实例。而上述代码显式地关闭并释放了当前的Client(即主动关闭并释放已经无法再使用的Client实例),这会促使Hudi在下一次同步元数据时重建新的Client实例。5.4.
Failed to check if database exists ...
6. 结语
GlueHudiReadWriteExample.scala这个类的实现上不难看出,只要一次性做好几处关键配置,在Glue中使用Hudi其实与在Spark原生环境中使用Hudi几乎是无异的,这意味着两者可以平滑地集成并各自持续升级。如此一来,Glue + Hudi的技术选型将非常具有竞争力,前者是一个无服务器架构的Spark计算环境,主打零运维和极致的成本控制,后者则为新一代数据湖提供更新插入、增量查询和并发控制等功能性支持,两者的成功结合是一件令人激动的事情,我想再次引用文章开始时使用的一句话作为结尾:无论如何,一个支持增量数据处理的无服务器架构的数据湖是非常吸引人的!

下一篇:js 字符串转json对象