DataPipeline丨瓜子二手车基于Kafka的结构化数据流
2021-06-06 05:04
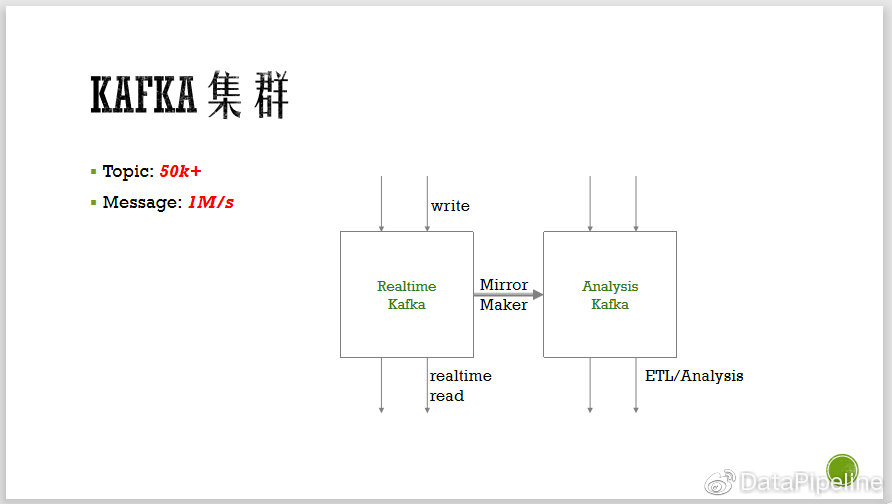
三、Kafka的用户使用问题
1.参数配置问题, Kafka有很多参数需要配置,常用的集群配置,延迟,重要性等,需要封装。
2. 开发测试不方便,使用者通常会有这样的需求:我的数据写进去没,消费没,他写的数据长什么样子,结构化的数据还需自己写代码来解析,等等。这些问题没有工具和平台来解决,会大大降低开发效率。
3. Topic申请不方便,topic是不能开放自己创建的,我们曾在测试环境开放过Topic,发现一周内涨到了好几万,而且参数千奇百怪,有全用默认参数的,有根据文档,时间先来10个9的,也有partition直接来100的。工单方式对管理者很不友好,需要登上服务器敲命令,效率低下,且容易出错。
4. 结构化数据查询不方便,瓜子的结构化使用的是AVRO, 序列化之后的数据很难查看原始数据。
5. 消费异常定位不便,比如消费的数据或者位置不对,如果想要回滚重新消费或跳过脏数据就面临各种问题。从哪个offset开始重新消费呢?或者跳到之后的哪个offset呢?另外就是滚动重启了一个服务,结果发现消费的数据少了一批,很有可能是某一个隐藏的consumer同时在用这个consumer group,但是找了一圈没找到哪个服务还没关掉。
6. 不知道下游,如果写了生产者生产的Topic数据,却不知道有哪些consumer,如果要对Topic信息发生改变时,不知该通知谁,这是很复杂的事情。要么先上,下游出问题了自己叫,要么踌躇不前,先收集下游,当然实际情况一般是前者,经常鸡飞狗跳。
7. 运维复杂,日常运维包括topic partition增加,帮助定位脏数据(因为他们不知道有脏数据),帮助排除配置问题等等。

四、解决方案:Kafka platform
为解决上述问题,瓜子上线了Kafka platform,主要面向用户和管理两方面的功能。
面向用户包括:查看数据,了解消费情况,方便地添加监控报警,以及如果出现问题后,快速查错的工具。
管理方面包括: 权限管理, 申请审批,还有一些常用操作。比如,seek offset, 或是删掉一个Topic,对partitions进行扩容等。

?
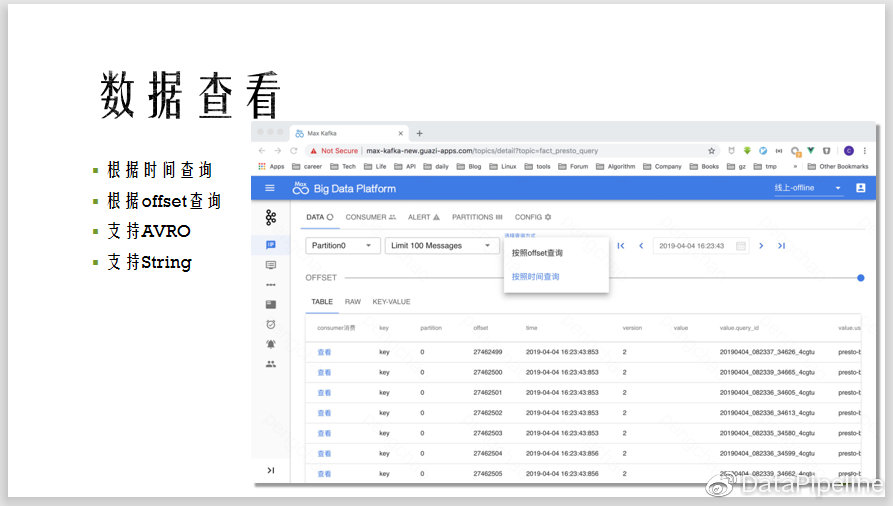
1. 数据查询
可以通过offset查询对应offset的数据,也可以通过进入Kafka的大致时间,查询那段内的数据,可以看到每条信息的partition,offset,入Kafka的时间,AVRO的版本信息等。
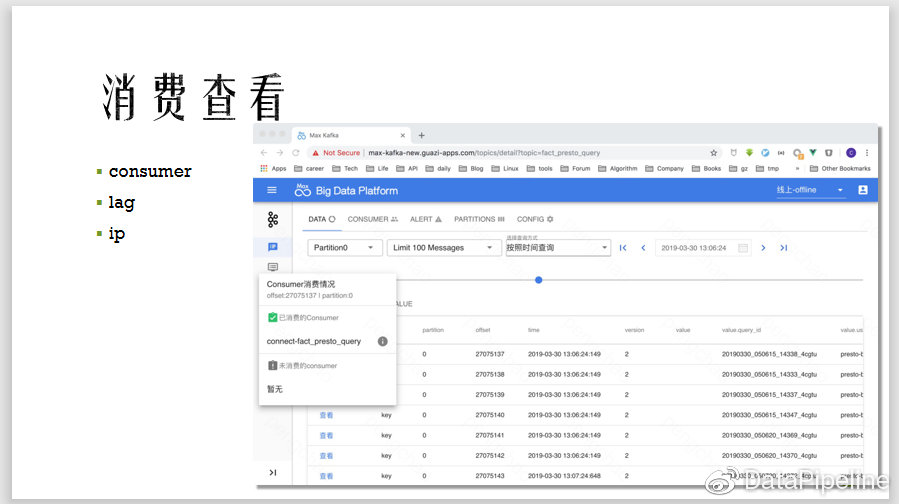
2. 消费查询
通过下图显示的界面可以查看一条消息,了解哪些consumer group已经消费了,哪些没有消费。
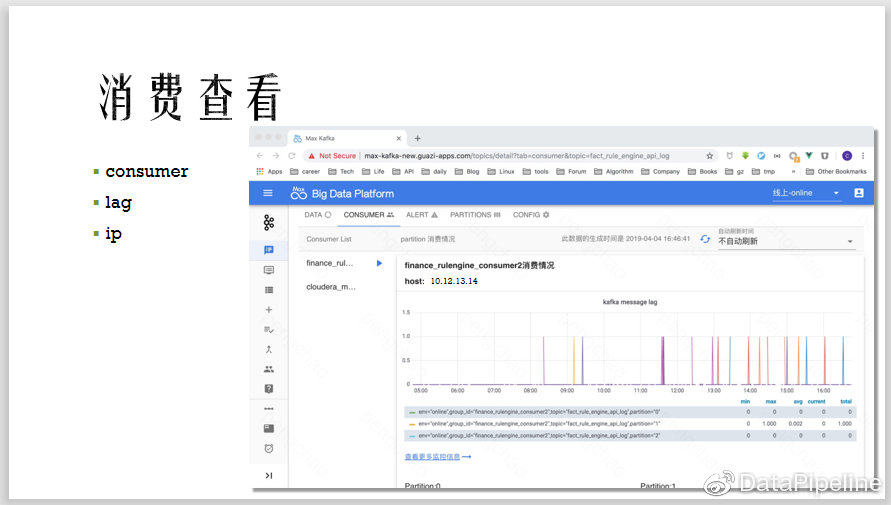
?同时可以查看它现在正在被哪个IP进行消费,这时我们可以方便地定位到有个consumer没有关闭,它是在哪台机器上,这些来自于我们的实践经验。还可以看到每个consumer group的消费延迟情况,精确到条数,partition的延迟。也可以看到partition消息总数,可以排查一些消息不均的问题。
下图为监控报警,可以了解Topic的流入、流出数据,每秒写入多少条消息,多大的size,每秒流出的情况。
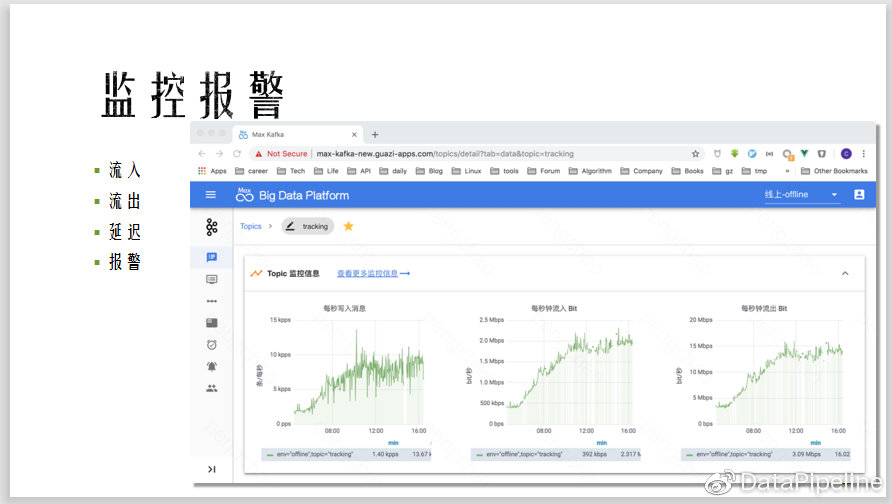
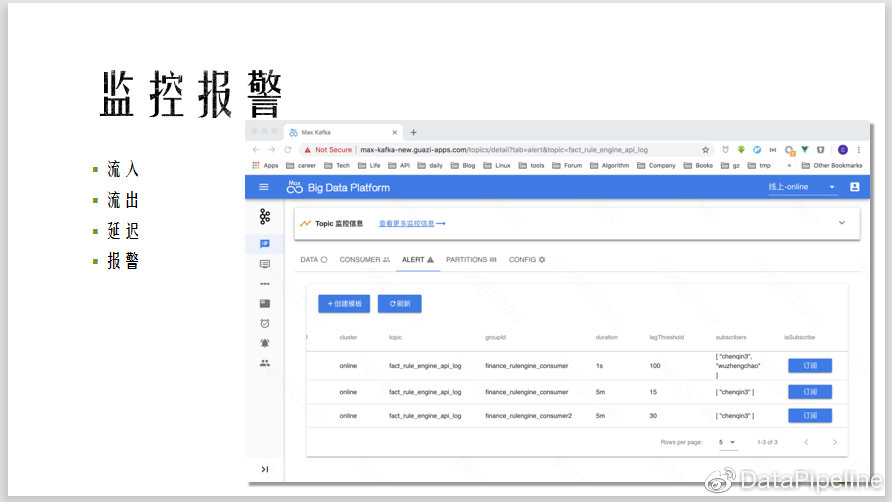
报警是对Topic建一些流量报警,或是一些延迟报警,建好之后只需要订阅一下即可,非常方便。
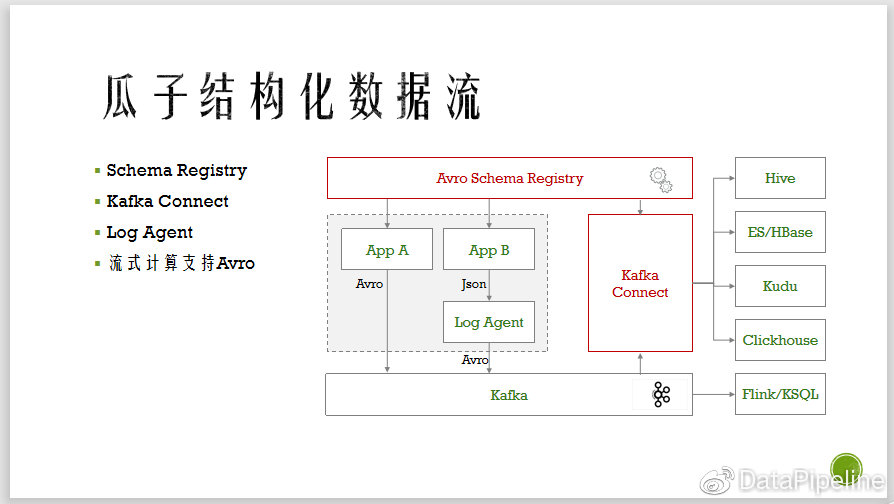
五、瓜子结构化数据流
目前有许多使用场景,比如前端埋点,tracking日志,Mysql数据同步,操作日志,一些诸如服务之间的交换,基于SQL的streaming,APM的数据,还有基于SQL的ETL等,都可以通过结构化将其快速同步到大数据中做后续分析。

?我们是通过confluent提供的一整套解决方案来实现的。其中最主要的两个组件是:Schema Registry和Kafka Connect。Schema Registry用于存储schema信息,Kafka connect用于数据转移。
?
目前,瓜子除日志部分外,90%以上为结构化。为什么选择Avro?因为Avro速度快,并且跨语言支持,所有的Schema AVSC都是用JSON做的,对JSON支持的特别好,如果可能没人想为一个schema定义再学一门语言吧。而且通过JSON无需code generation。
但仅有avro还不够,我们在使用中会面临更多的问题,比如:
- 统一的schema中心,这与配置中心的必要性是一样的道理,没有统一的地方,口口相传,配置乱飞不是我们想看到的。
- 多版本的需求,schema是肯定会有更新需求的,也肯定有回滚需求,也会有兼容需求,所以多版本是需要满足的。
- 版本兼容性检查,设想一下上游改了一个schema的列名,下游写到hive的时候就蒙了,历史数据咋办啊,现在这列数据又怎么处理。所以得有版本兼容,而且最好满足下游所有组件的需求。
- schema得有注释,给人展示的schema最好能有给人读的注释,很多人昨天定义的enum,今天就忘了,这个事情很常见。

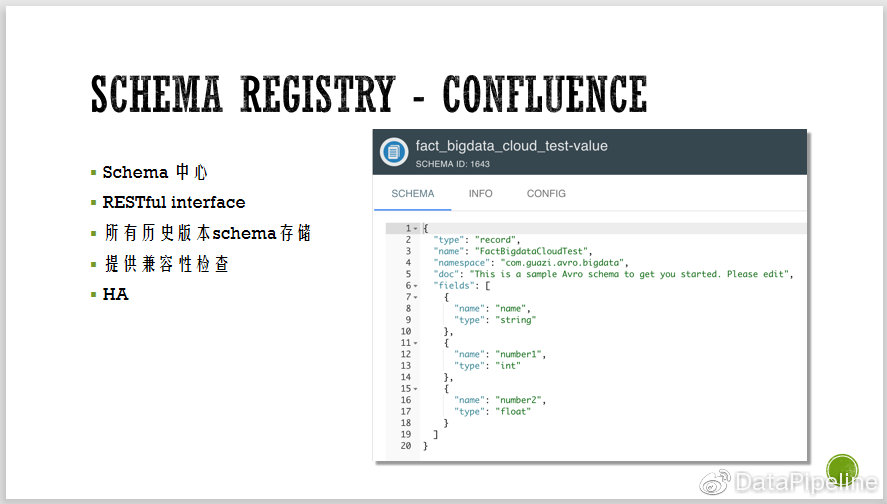
为解决这些问题,我们引入了confluence的Schema Registry。Confluence的Schema registry,通过RESTful接口,提供了类似配置中心的能力,还有完善的UI,支持版本兼容性检查,支持多版本等,完全满足了我们的需求。而且自带HA,通过Kafka存储配置信息,保证一致性。
?五、瓜子的实践
当然,仅有这些还不够,我们在实践中遇到了很多问题,比如schema注册不可能完全开放,历史告诉我们完全的自由意味着混乱。为在实践中利用好avro,我们前后改了两个方案,来保证schema可控。
1. 最初的方案
为实现统一管控,所有schema会通过git来管理,如果需要使用可以fork该git。如果要做一个上线,更新或添加一个schema,可以通过提merge request提交给管理员。管理员检查没有问题后直接通过gitlab-ci自动注册,管理员只需完成确认的操作。
但这样会出现一些问题,首先是上线流程太长,要上线或更新一个schema时,需要提交merge request,要等管理员收到邮件后才可查看,届时如果管理员发现schema写的不对,还需重新再走一次流程,中间可能花一天时间。且回滚复杂,没有权限管理。而且很多人会犯同样的错误,客服表示相当的浪费时间。

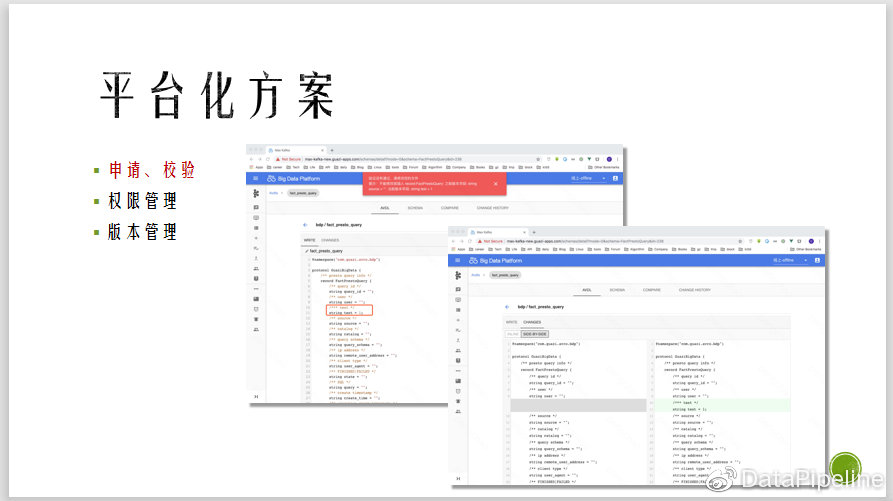
六、平台化解决方案
通过平台化解决方案,我们提供了一个类似于git的页面,可在上面直接提交schema,在下面直接点击校验,在评估新上线的schema是否有问题后,等待后台审批即可。其中可以加诸如权限管理等一些功能。
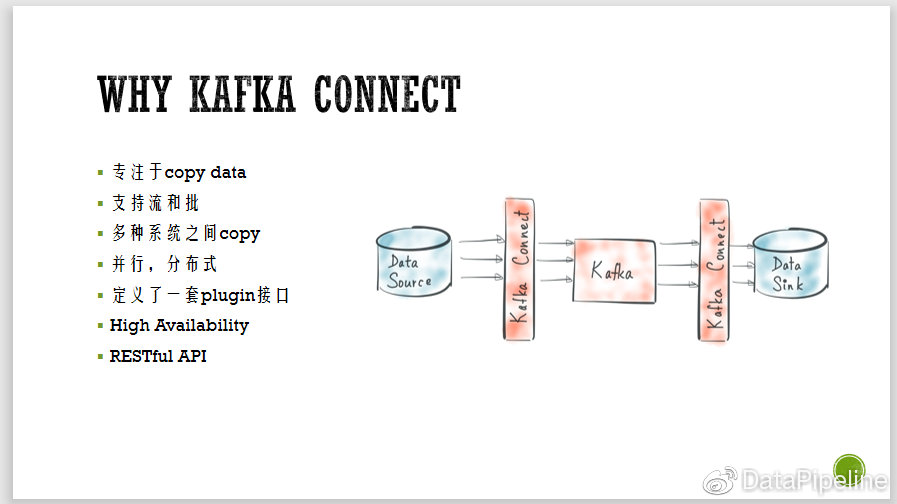
七、为什么用到Kafka connect
Kafka connect专注copy数据,把一个数据从data source转到Kafka,再从Kafka转到其它地方。它支持批和流,同时支持实时和批处理,比如5min同步一次。
另外,它支持多个系统之间互相copy,数据源可能是Mysql、SQL Server 也可能是Oracle 。sink可以是Hbase、Hive等。它自己定义了一套plugin接口,可以自己写很多数据源和不支持的sink。
并且他自己做到了分布式并行,支持完善的HA和load balance,还提供方便的RESTful 接口。
?
在没有Kafka connect之前,运维ETL非常麻烦。拿canal来说,canal有server和client,都需手动部署,如果你有100台canal节点1000个数据库,想想看吧,管理员如何知道哪台机器上跑了哪些库表,新增的任务又放在哪台机来运行。
此外,如果Mysql修改了一个字段,还需要让程序员去机器上看一下那张表是如何修改的,相应的所有下游都需相应的完成表结构修改之后, 才能跑起来,响应速度非常慢。
目前Kafka connect已经解决了这些问题。其具备一个非常重要的特性,如果上游数据根据AVRO兼容性进行的修改,connect会在下游同样做一些兼容性的修改,自动更改下游表结构,减轻了运维负担。

?
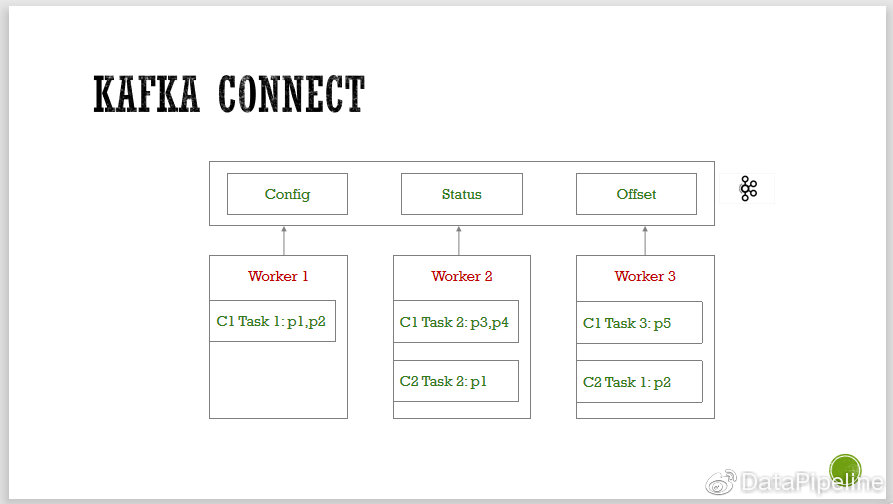
我们来看看Kafka connect 的架构,Kafka connect会把所有信息存到Kafka 中,其中config topic存元数据,Stutas topic指当前哪些节点正在跑什么样的job,offset topic指当前比如某个Topic的某个partitions到底消费到哪条数据。
WorKer都是无状态的,在上面可以跑许多task,同样一个task1,可能对应5个partitions,如果只给它三个并发,它会分布在三台机器上。如果一台机器挂了,这些job都会分配到另外两台机器,而且是实时同步的。
?八、瓜子Plugins
瓜子对Kafka connect的很多plugins做了修改。
1. Maxwell
其中我们把canal通过maxwell替换,并且把maxwell做成了Kafka connect的plugin。
原生的Maxwell不支持AVRO,瓜子通过debezium思想对Maxwell进行了修改,使其支持avro格式,并用Mysql管理meta,并且支持Mysql的数据库切换。
2. HDFS
我们采用的是confluence公司的hdfs插件,但是其本身存在很多问题,比如写入hive的时候会把当做partition的列也写到主表数据中,虽然不影响hive的使用,但是影响presto读取hive,这里我们改了源码,去掉了主表中的这些列。
Hdfs在插件重启时会去hdfs中读取所有文件来确定从哪个offset继续,这里会有两个问题:耗时太长,切换集群时offset无法接续,我们也对他做了修改。
plugin写入hive时支持用Kafka的timestamp做分区,也支持用数据内的某些列做分区,但是不支持两者同时用,我们也修改了一下。
3. HBase
Hbase的plugin只支持最原始的导出,我们会有些特殊的需求,比如对rowkey自定义一下,通常mysql主键是自增ID,hbase不推荐用自增ID做rowkey,我们会有reverse的需求,还有多列联合做rowkey的需求等,这个我们也改了源码,支持通过配置自定义rowkey生成。
原始plugin不支持kerberos,而我们online hbase是带权限的,所以也改了一下
还有一些小功能,比如把所有类型都先转成string再存,支持delete,支持json等。
4. KUDU
我们对kudu的使用很多,kudu开源的plugin有些bug,我们发现后也fix了一下。
Kudu的数据来源都是mysql,但是经常会有mysql刷库的情况,这时量就会很大,kudu sink会有较大的延时,我们改了一下plugin,添加了自适应流量控制,自动扩充成多线程处理,也会在流量小时,自动缩容。
九、瓜子数据库的Data Pipeline
瓜子的数据仓库完全是基于Kafka、AVRO的结构化数据来做的。数据源非常多,需要将多个业务线的几千张表同步到数仓,对外提供服务。
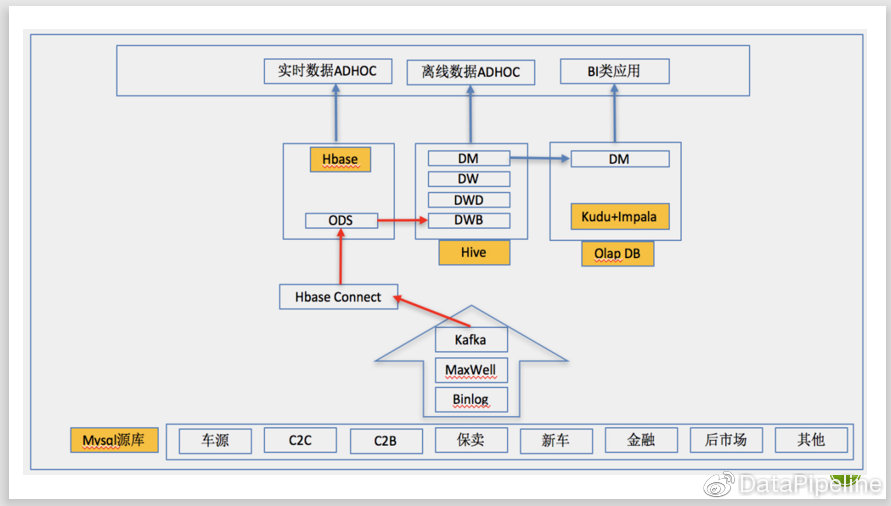
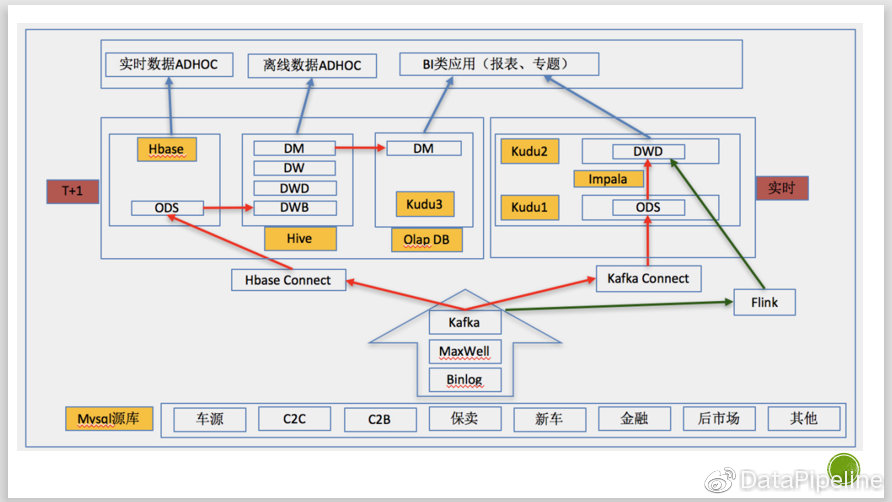
整个数据仓库采用Lambda架构,分为T+1的存量处理和T+0.1的增量处理两个流程。
先说T+1的存量处理部分,目前瓜子将所有mysql表通过Maxwell插件放到Kafka中,再通过Kafka connect写到Hbase里,Hbase每天晚上做一次snapshot(快照),写到hive中,然后经过多轮ETL:DWB-->DWD-->DW-->DM,最后将DM层数据导入Kudu中,对外提供BI分析服务,当然离线olap分析还是通过presto直接访问Hive查询。
?
再说T+0.1的增量流程,同T+1一样,数据通过maxwell进入Kafka,这部分流程共用,然后增量数据会实时通过kudu的插件写入kudu中,再通过impala做ETL,生成数据对外提供T+0.1的查询,对外提供的查询是通过另一套impala来做的。 未来我们还会考虑通过Flink直接读取Kafka中数据来做实时ETL,提高实时性。
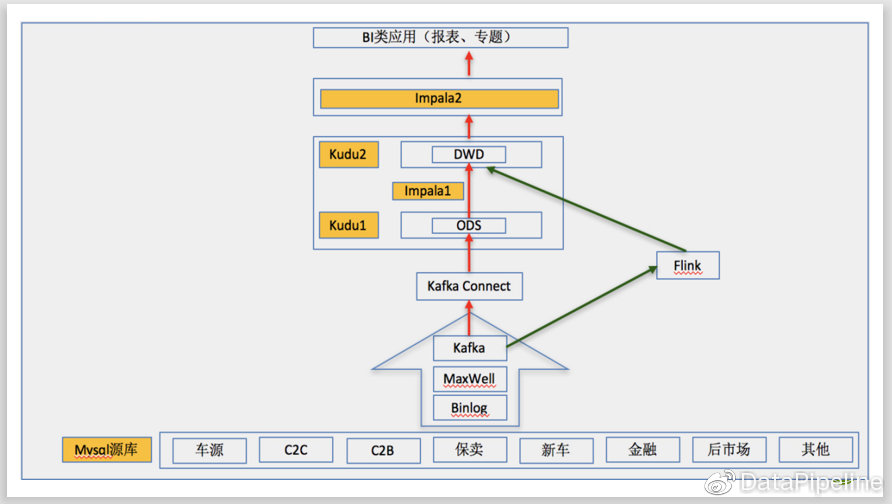
?
这是我们数仓架构的整体架构图
?
????
文章标题:DataPipeline丨瓜子二手车基于Kafka的结构化数据流
文章链接:http://soscw.com/essay/91130.html