Python 爬虫 + 人脸检测 —— 知乎高颜值图片抓取
2021-06-11 10:03
标签:pos ike 质量 exists idt download options 定义 width 知乎 话题『美女』下所有问题中回答所出现的图片 Python 3,并使用第三方库 Requests、lxml、AipFace,代码共 100 + 行 Mac / Linux / Windows (Linux 没测过,理论上可以。Windows 之前较多反应出现异常,后查是 windows 对本地文件名中的字符做了限制,已使用正则过滤),无需登录知乎(即无需提供知乎帐号密码),人脸检测服务需要一个百度云帐号(即百度网盘 / 贴吧帐号) AipFace,由百度云 AI 开放平台提供,是一个可以进行人脸检测的 Python SDK。可以直接通过 HTTP 访问,免费使用 http://ai.baidu.com/ai-doc/FACE/fk3co86lr 在这里还是要推荐下我自己建的Python开发学习群:
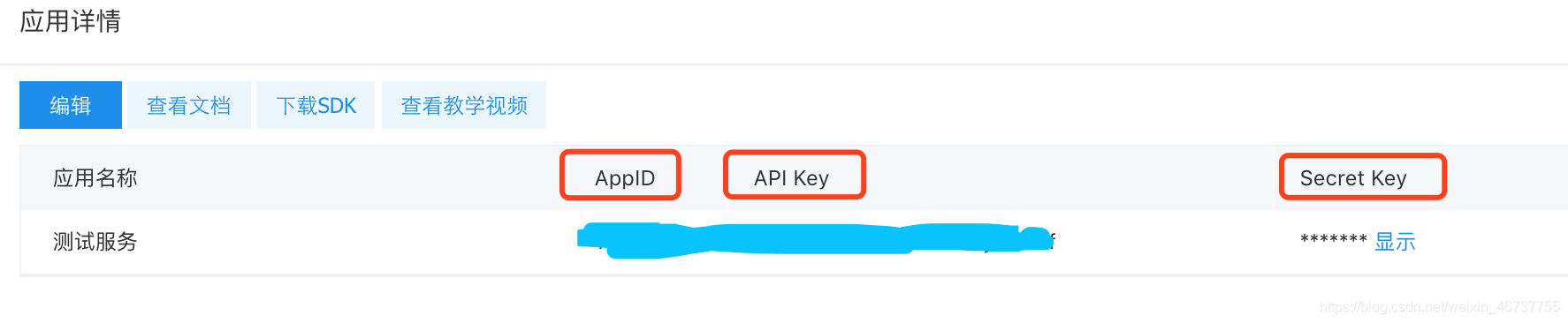
直接存放在文件夹中(angelababy 实力出境)。另外说句,目前抓下来的图片,除 baby 外,88 分是最高分。个人对其中的排序表示反对,老婆竟然不是最高分 8 代码 将 AppID ApiKek SecretKey 填写到 代码 中 Chrome 浏览器;找一个知乎链接点进去,打开开发者工具,查看 HTTP 请求 header;无需登录 因是人脸检测,所以可能有些福利会被筛掉。百度图像识别 API 还有一个叫做色情识别。这个 API 可以识别不可描述以及性感指数程度,可以用这个 API 来找福利 https://cloud.baidu.com/product/imagecensoring 在这里还是要推荐下我自己建的Python开发学习群: Python 爬虫 + 人脸检测 —— 知乎高颜值图片抓取 标签:pos ike 质量 exists idt download options 定义 width 原文地址:https://www.cnblogs.com/peig/p/14225338.html1 数据源
2 抓取工具
3 必要环境
4 人脸检测库
5 检测过滤条件
8107354036 实现逻辑
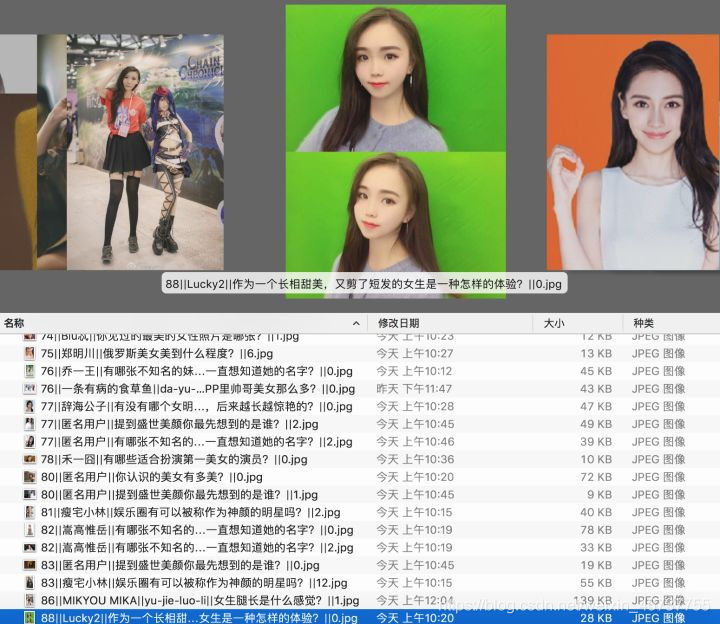
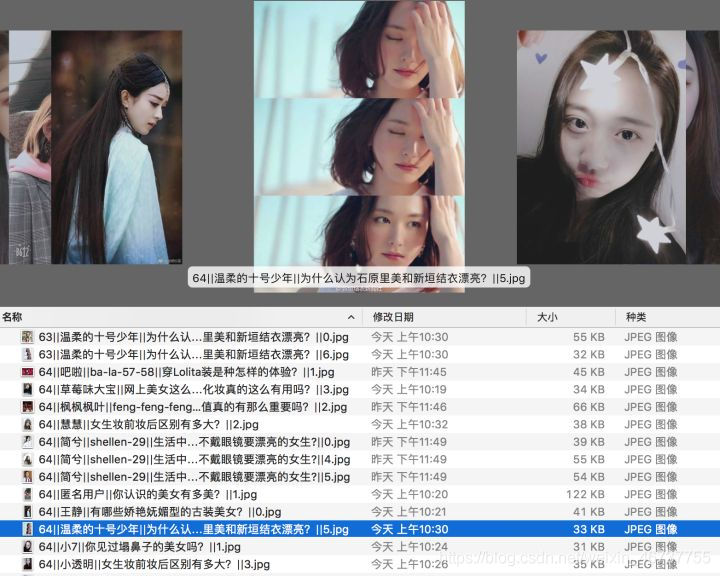
7 抓取结果


SDK 或使用这个直接构造 HTTP 版本) 1 #coding: utf-8
2
3 import time
4 import os
5 import re
6
7 import requests
8 from lxml import etree
9
10 from aip import AipFace
11
12 #百度云 人脸检测 申请信息
13 #唯一必须填的信息就这三行
14 APP_ID = "xxxxxxxx"
15 API_KEY = "xxxxxxxxxxxxxxxxxxxxxxxx"
16 SECRET_KEY = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
17
18 # 文件存放目录名,相对于当前目录
19 DIR = "image"
20 # 过滤颜值阈值,存储空间大的请随意
21 BEAUTY_THRESHOLD = 45
22
23 #浏览器中打开知乎,在开发者工具复制一个,无需登录
24 #如何替换该值下文有讲述
25 AUTHORIZATION = "oauth c3cef7c66a1843f8b3a9e6a1e3160e20"
26
27 #以下皆无需改动
28
29 #每次请求知乎的讨论列表长度,不建议设定太长,注意节操
30 LIMIT = 5
31
32 #这是话题『美女』的 ID,其是『颜值』(20013528)的父话题
33 SOURCE = "19552207"
34
35 #爬虫假装下正常浏览器请求
36 USER_AGENT = "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.55.3 (KHTML, like Gecko) Version/5.1.5 Safari/534.55.3"
37 #爬虫假装下正常浏览器请求
38 REFERER = "https://www.zhihu.com/topic/%s/newest" % SOURCE
39 #某话题下讨论列表请求 url
40 BASE_URL = "https://www.zhihu.com/api/v4/topics/%s/feeds/timeline_activity"
41 #初始请求 url 附带的请求参数
42 URL_QUERY = "?include=data%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Danswer%29%5D.target.is_normal%2Ccomment_count%2Cvoteup_count%2Ccontent%2Crelevant_info%2Cexcerpt.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cvoteup_count%2Ccomment_count%2Cvoting%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dtopic_sticky_module%29%5D.target.data%5B%3F%28target.type%3Dpeople%29%5D.target.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%3F%28target.type%3Danswer%29%5D.target.author.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Darticle%29%5D.target.content%2Cauthor.badge%5B%3F%28type%3Dbest_answerer%29%5D.topics%3Bdata%5B%3F%28target.type%3Dquestion%29%5D.target.comment_count&limit=" + str(LIMIT)
43
44 #指定 url,获取对应原始内容 / 图片
45 def fetch_image(url):
46 try:
47 headers = {
48 "User-Agent": USER_AGENT,
49 "Referer": REFERER,
50 "authorization": AUTHORIZATION
51 }
52 s = requests.get(url, headers=headers)
53 except Exception as e:
54 print("fetch last activities fail. " + url)
55 raise e
56
57 return s.content
58
59 #指定 url,获取对应 JSON 返回 / 话题列表
60 def fetch_activities(url):
61 try:
62 headers = {
63 "User-Agent": USER_AGENT,
64 "Referer": REFERER,
65 "authorization": AUTHORIZATION
66 }
67 s = requests.get(url, headers=headers)
68 except Exception as e:
69 print("fetch last activities fail. " + url)
70 raise e
71
72 return s.json()
73
74 #处理返回的话题列表
75 def process_activities(datums, face_detective):
76 for data in datums["data"]:
77
78 target = data["target"]
79 if "content" not in target or "question" not in target or "author" not in target:
80 continue
81
82 #解析列表中每一个元素的内容
83 html = etree.HTML(target["content"])
84
85 seq = 0
86
87 #question_url = target["question"]["url"]
88 question_title = target["question"]["title"]
89
90 author_name = target["author"]["name"]
91 #author_id = target["author"]["url_token"]
92
93 print("current answer: " + question_title + " author: " + author_name)
94
95 #获取所有图片地址
96 images = html.xpath("//img/@src")
97 for image in images:
98 if not image.startswith("http"):
99 continue
100 s = fetch_image(image)
101
102 #请求人脸检测服务
103 scores = face_detective(s)
104
105 for score in scores:
106 filename = ("%d--" % score) + author_name + "--" + question_title + ("--%d" % seq) + ".jpg"
107 filename = re.sub(r‘(?u)[^-\w.]‘, ‘_‘, filename)
108 #注意文件名的处理,不同平台的非法字符不一样,这里只做了简单处理,特别是 author_name / question_title 中的内容
109 seq = seq + 1
110 with open(os.path.join(DIR, filename), "wb") as fd:
111 fd.write(s)
112
113 #人脸检测 免费,但有 QPS 限制
114 time.sleep(2)
115
116 if not datums["paging"]["is_end"]:
117 #获取后续讨论列表的请求 url
118 return datums["paging"]["next"]
119 else:
120 return None
121
122 def get_valid_filename(s):
123 s = str(s).strip().replace(‘ ‘, ‘_‘)
124 return re.sub(r‘(?u)[^-\w.]‘, ‘_‘, s)
125
126 import base64
127 def detect_face(image, token):
128 try:
129 URL = "https://aip.baidubce.com/rest/2.0/face/v3/detect"
130 params = {
131 "access_token": token
132 }
133 data = {
134 "face_field": "age,gender,beauty,qualities",
135 "image_type": "BASE64",
136 "image": base64.b64encode(image)
137 }
138 s = requests.post(URL, params=params, data=data)
139 return s.json()["result"]
140 except Exception as e:
141 print("detect face fail. " + url)
142 raise e
143
144 def fetch_auth_token(api_key, secret_key):
145 try:
146 URL = "https://aip.baidubce.com/oauth/2.0/token"
147 params = {
148 "grant_type": "client_credentials",
149 "client_id": api_key,
150 "client_secret": secret_key
151 }
152 s = requests.post(URL, params=params)
153 return s.json()["access_token"]
154 except Exception as e:
155 print("fetch baidu auth token fail. " + url)
156 raise e
157
158 def init_face_detective(app_id, api_key, secret_key):
159 # client = AipFace(app_id, api_key, secret_key)
160 # 百度云 V3 版本接口,需要先获取 access token
161 token = fetch_auth_token(api_key, secret_key)
162 def detective(image):
163 #r = client.detect(image, options)
164 # 直接使用 HTTP 请求
165 r = detect_face(image, token)
166 #如果没有检测到人脸
167 if r is None or r["face_num"] == 0:
168 return []
169
170 scores = []
171 for face in r["face_list"]:
172 #人脸置信度太低
173 if face["face_probability"] :
174 continue
175 #颜值低于阈值
176 if face["beauty"] BEAUTY_THRESHOLD:
177 continue
178 #性别非女性
179 if face["gender"]["type"] != "female":
180 continue
181 scores.append(face["beauty"])
182
183 return scores
184
185 return detective
186
187 def init_env():
188 if not os.path.exists(DIR):
189 os.makedirs(DIR)
190
191 init_env()
192 face_detective = init_face_detective(APP_ID, API_KEY, SECRET_KEY)
193
194 url = BASE_URL % SOURCE + URL_QUERY
195 while url is not None:
196 print("current url: " + url)
197 datums = fetch_activities(url)
198 url = process_activities(datums, face_detective)
199 #注意节操,爬虫休息间隔不要调小
200 time.sleep(5)
201
202
203 # vim: set ts=4 sw=4 sts=4 tw=100 et:
9 运行准备
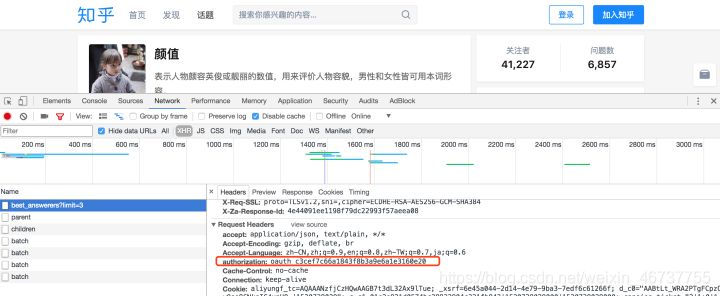
AUTHORIZATION,可从开发者工具中获取(如下图,换了几个浏览器,目前没登录情况该值都是一样的。知乎对爬虫的态度比较开放,不知道后续是否会更换)1 {
2 "error": {
3 "message": "ZERR_NO_AUTH_TOKEN",
4 "code": 100,
5 "name": "AuthenticationInvalidRequest"
6 }
7 }
1 - 运行 ^*^
10 结语
下,代码里有很多地方可以很容易的修改,从最简单的数据源话题变更、抓取数据字段增加和删除到图片过滤条件修改都很容易。如果再稍微花费时间,变更为抓取某人动态(比如轮子哥,数据质量很高)、探索
HTTP 请求中哪些 header 和 query
是必要的,文中代码都只需要非常局部性的修改。至于人脸探测,或者其他机器学习接口,可以提供非常多的功能用于数据过滤,但哪些过滤是具备高可靠性,可信赖的且具备可用性,这个大概是经验和反复试验,这就是额外的话题了;顺便希望大家有良好的编码习惯810735403,群里都是学Python开发的,如果你正在学习Python ,欢迎你加入,大家都是软件开发党,不定期分享干货(只有Python软件开发相关的),包括我自己整理的一份2020最新的Python进阶资料和高级开发教程,欢迎进阶中和进想深入Python的小伙伴!
上一篇:python 异常获取方法
文章标题:Python 爬虫 + 人脸检测 —— 知乎高颜值图片抓取
文章链接:http://soscw.com/essay/93539.html