Why GraphQL is Taking Over APIs
2021-06-18 16:20
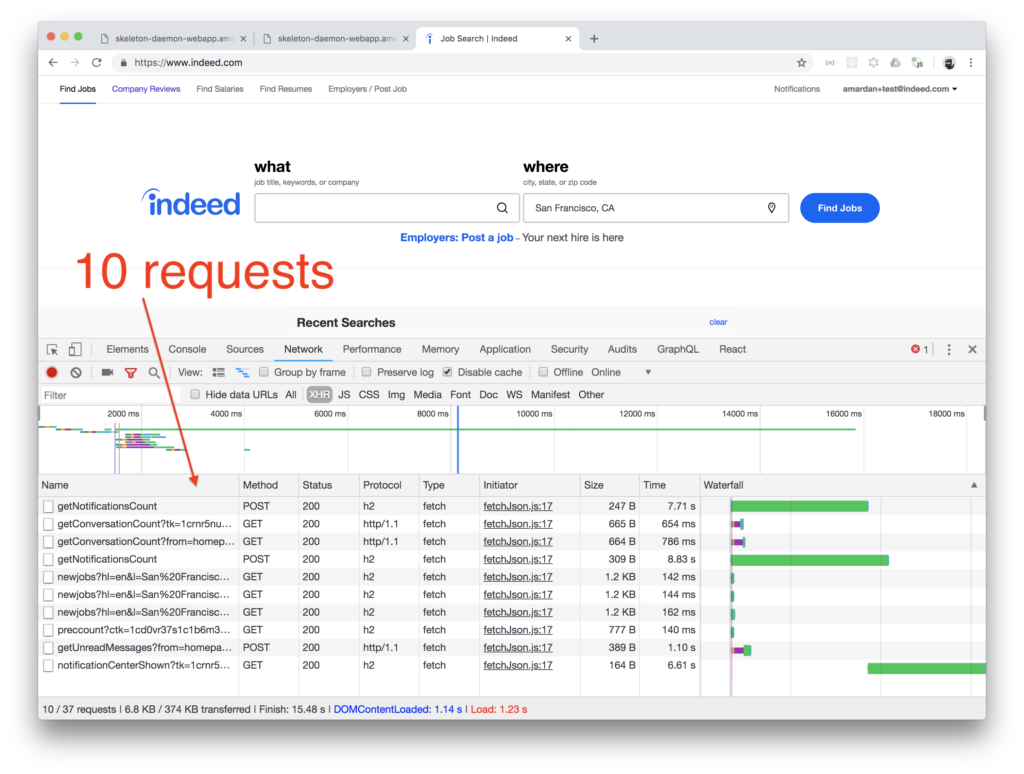
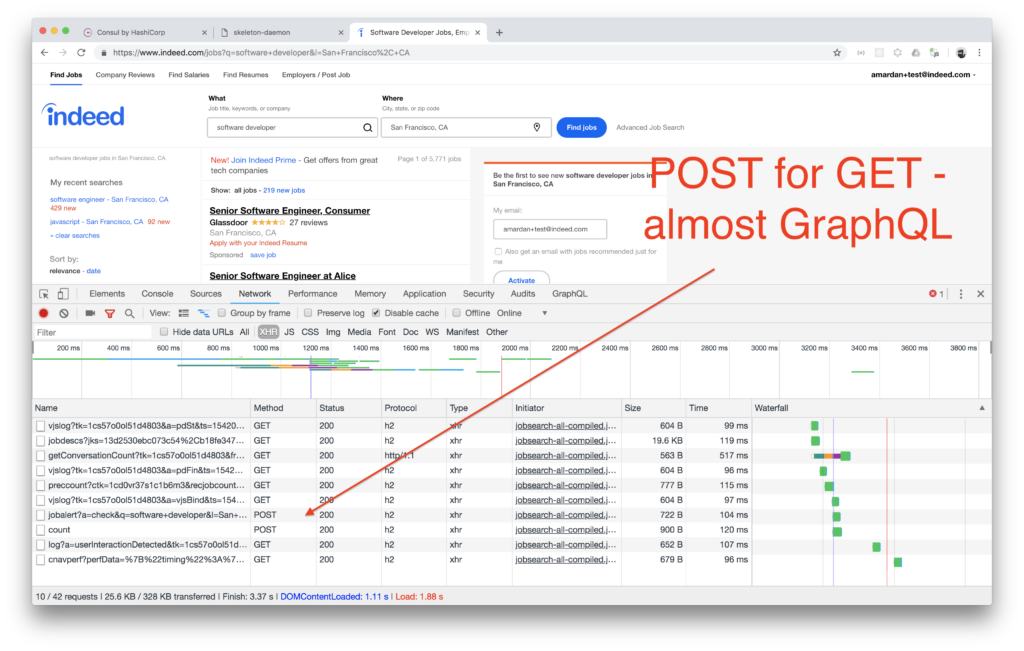
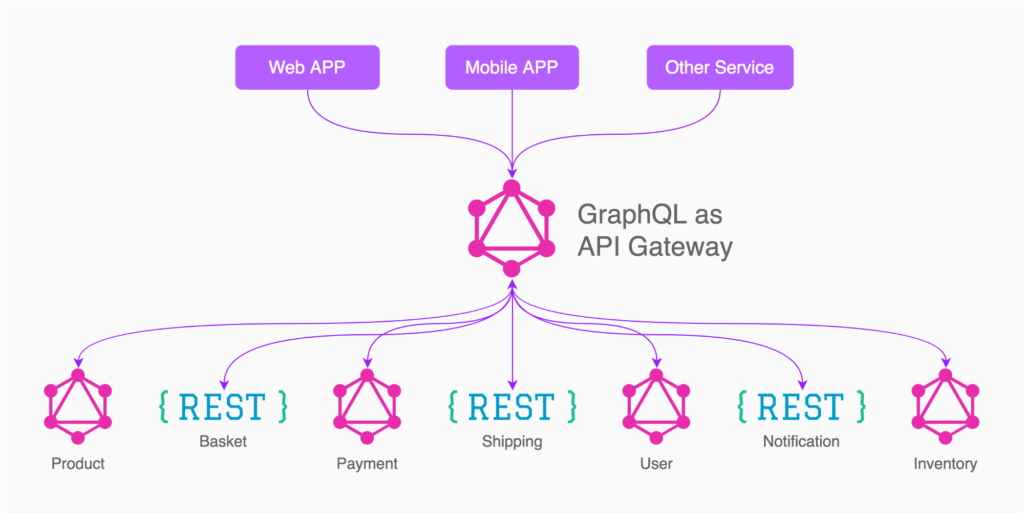
标签:dir pattern component backend set clojure multiple rac mos A few years ago, I managed a team at DocuSign that was tasked with re-writing the main DocuSign web app which was used by tens of millions of users. The APIs didn’t exist yet to support our new shiny front-end app because since the beginning the web app was a .NET monolith. The API team in Seattle was taking the monolith apart and exposing RESTful APIs slowly. This API team consisted of just two engineers and had a release cycle of one month. Our front-end team in San Francisco released every week. The API team release cycle was so long because a lot of (almost all) the functionality had to be tested manually. That’s understandable. It was a monolith without proper automated test coverage after all—when they modified one part, they never knew what can go wrong in other parts of the application. I remember one situation when our front-end team was under pressure to deliver in time for the conference and we forgot to follow up on one important API change. It wasn’t included in the up-coming API release. That was as bad, bad, bad. It was like forgetting to buy a Christmas present for your mom. We had to wait and miss the deadline or beg someone to drop a priority so our change can be included instead of theirs. Luckily, we got the change included in the API release and shipped the new front-end app in time for the conference. I really wish we had something like GraphQL then. It would have removed the hard dependency on the external team and their longer release cycle. In this and following posts I’ll share benefits of GraphQL why it became so popular. Full disclaimer: I’m absolutely biased in favor of GraphQL in part because I had good experience working with it and in part because I authored a course Learning Clientside GraphQL with Apollo. A lot of companies switched from RESTful to GraphQL APIs for internal usage: IBM, Twitter, Walmart Labs, The New York Times, Intuit, Coursera, and the list goes on an on. They claim they like it and they like very much. Other companies switched not only internal but their external APIs to GraphQL: AWS, Yelp, GitHub, Facebook, and Shopify among others. GitHub went so far as not even bothering with REST API. Their v4 is GraphQL-only. Why all the fuss? Is GraphQL only a hyped up buzzword or a real game changer? Interestingly, most companies that I listed prior, which benefited form GraphQL, have these things in common: These are the motivations from the words of the GitHub engineering: “Using GraphQL on the frontend and backend eliminates the gap between what we release and what you can consume. We really look forward to making more of these simultaneous releases. If you are not familiar with GraphQL or never heard of it, GraphQL is an open-source query language and the protocol for APIs. Think about GraphQL as SQL but only for APIs instead of databases. This blog post assumes most readers are somewhat familiar with the main GraphQL concepts. This post will have some code examples but mostly highlight advantages and differences between GraphQL and RESTful APIs. You can read more about GraphQL at https://graphql.org or play with Start Wars queries. My anecdotal claim is that GraphQL speeds up development, improves developer experience and offers better tooling. I’m not claiming this is absolute truth but I’ll do my best to convey arguments and whys of GraphQL vs. REST. Onward! I work as a software engineering leader at Indeed (the world’s #1 job search site), so let’s take a look at the Indeed.com home page and the job search result page. They make 10 and 11 XHR requests respectively. Let’s set aside the fact that for the page browsing, POST is being used which is not exactly how REST should work. :) [Sidenote] Reading blog posts is good, but watching video courses is even better because they are more engaging. A lot of developers complained that there is a lack of affordable quality video material on Node. It‘s distracting to watch to YouTube videos and insane to pay $500 for a Node video course! Go check out Node University which has FREE video courses on Node: node.university. [End of sidenote] Here are some of the calls: With GraphQL, the Indeed requests listed prior can be substituted by this single query and one request: The resulting GraphQL response has this structure: Generally, it’s way more convenient and efficient to make a single call instead of multiple calls because it requires less code and less network overhead. More support for increased velocity and developer experience follow in respective sections. PayPal experience also confirms that a lot of UI work is actually not UI work but other tasks such as making frontend and backend talk to each other: “When we took a closer look, we found that UI developers were spending less than 1/3 of their time actually building UI. The rest of that time spent was figuring out where and how to fetch data, filtering/mapping over that data and orchestrating many API calls. Sprinkle in some build/deploy overhead. Now, building UI is a nice-to-have or an afterthought.” — GraphQL: A success story for PayPal Checkout, PayPal Engineering It’s worth noting that there may be valid reasons to make multiple requests such as separate requests can get different data quickly and asynchronously/independently; they add flexibility in deployment if used with microservices; and they give multiple points of failure instead of one. (See When Not to Use GraphQL at the end.) Additionally, in case a page content is developed by multiple teams, there is a feature in GraphQL that allows to break down queries called fragments. More on code organization later. Looking at a bigger picture, the main use case for GraphQL API is an API gateway where it provide a layer of abstraction over other APIs which means this API is between clients and other services. Microservices are great but they have some problems of their own. GraphQL can help. Here’s IBM’s experience using GraphQL for microservices: “All in all, development and deployment of the GraphQL microservice was extremely quick. They started development in May and it was in production in July. The main reason for this was they didn’t ask for permission and just built it. He highly recommends this approach. It is far better than meetings.” — GraphQL at massive scale: GraphQL as the glue in a microservice architecture, Jason Lengstorf (@jlengstorf) of IBM Next, let’s discuss each of the GraphQL benefits one by one. As I demonstrated in the previous section, GraphQL allows to make fewer requests. It’s much easier to make a single call POST /graphql to fetch exactly the data that is needed instead of implementing multiple requests. This speeds up the development because from an engineer’s perspective. There are more reasons behind increased velocity described later, such as code organization (see Improved Developer Experience). Right now I want to zoom in on another aspect. Backend and client teams need to work closely together to define API contacts, test them and make changes. Client teams such as front end, mobile, IoT (e.g., Alexa), and so on constantly iterate on features and experiment with UX and design. Their data requirements change frequently and the backend team(s) has to keep up. It’s less of a problem if client and backend code owned by the same team. And most of Indeed engineering teams are full stack but not all. For non-fullstack teams, client team is very often slowed down by the dependence on the backend team. When I rotated on the Job Seeker API team, the mobile team depended on our progress. There was a lot of communication and going back and forth about parameters, response fields and testing. With GraphQL, client engineers have all the control and don’t need to depend on anyone, because they dictate to the backend what they need and what the response structure must be. They use GraphQL queries for that. Queries tell APIs what to provide. This is truly liberating. Client engineers don’t have to spend time to ask the API team to add or modify something. GraphQL is self-documenting which means less time trying to figure out how to use an undocumented API. I’m sure most of us can relate to time wasted trying to find out exact request parameters. The GraphQL protocol and its community offer tools that help a lot with documentations. In some cases, the documentation can be generated automatically from the schemas. Other times, just using GraphiQL web interface is enough to write a query (which is enough to make the request as I showed with CURL and fetch examples). Let’s see what one of the adopters of GraphQL, New York Times engineer, says about not having to make multiple changes after their transition to GraphQL and Relay: “As we transition away from using REST APIs, we no longer have to query the canonical representation of an article, when all we really need in some display modes is five to seven fields… My favorite use case for GraphQL is when a company already have most of the API in GraphQL and someone comes up with a new product idea. It’s faster to implement this prototype with already existing GraphQL API instead of calling various REST endpoints (which will give too little or too much data) or building a new REST API just for this new app. The velocity of development is closely related to improved developer experience. GraphQL offers a better developer experience (DX). With GraphQL, engineers need to think less about data fetching. They simply declare data alongside their UI as in the case of Apollo. The data is right next to UI which makes it easier to read and write code. This is amazingly convenient. Generally UI development involves jumping from UI templates, to client code, to UI styles. GraphQL allows engineers to develop UIs on the client with less friction because engineers don’t need to switch from file to file when they implement or make changes. If you’re familiar with React, here’s a good metaphor: GraphQL is to data what React is to UI. Next is an abbreviated example that shows the convenience of having UI with property names
GraphQL represents a massive leap forward for API development. Type safety, introspection, generated documentation, and predictable responses benefit both the maintainers and consumers of our platform. We’re looking forward to our new era of a GraphQL-backed platform, and we hope that you do, too!” – The GitHub GraphQL API, GitHub EngineeringThe Ultimate Data Aggregator
query HomePage {
getConversationCount(...) {
...
}
jobdescs(...) {
...
}
vjslog(...) {
...
}
preccount(...) {
…
}
jobalert(...) {
…
}
count(...) {
…
}
}
{
"data": {
"getConversationCount": [
{
...
}
],
"vjslog": [...],
"preccount": [...],
"jobalert": [...],
"count": {}
},
"errors": []
}
Increased Velocity of Development
When we want to update our design across all products, we will no longer have to make changes across several codebases. This is the reality we are moving towards. We think Relay and GraphQL are the perfect tools to take us there.” — React, Relay and GraphQL: Under the Hood of The Times Website Redesign, Times OpenImproved Developer Experience
launch.name and launch.rocket.name right in the same file as the query.const GET_LAUNCHES = gql`
query launchList($after: String) {
launches(after: $after) {
launches {
id
name
isBooked
rocket {
id
name
}
}
}
}
`;
export default function Launches() {
return (
Query query={GET_LAUNCHES}>
{({ data, loading, error }) => {
if (loading) return Loading />;
if (error) return p>ERRORp>;
return (
div>
{data.launches.launches.map(launch => (
div
key={launch.id}
>{launch.name}br/>
Rocket: {launch.rocket.name}
div>
))}
div>
);
}}
Query>
);
};
With this approach, it’s very easy to modify or add a new field to UI (render) and/or to the query (gql). React components become more portable because they describe all the data that they need.
As mentioned prior, the documentation is better and there’s a query playground called GraphiQL:
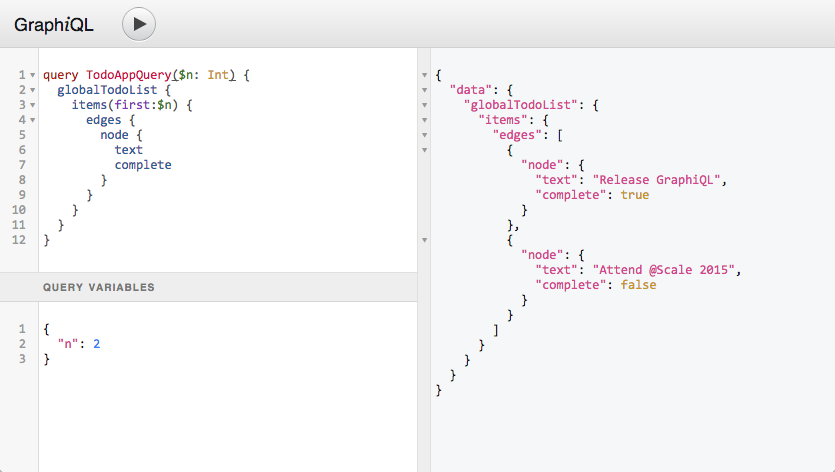
Front-end Engineers like GraphiQL a lot. Here’s a quote from one of them.
“I think one of the best parts of the dev experience is being able to interactively explore a schema with GraphiQL. To me, this is a much more productive way of figuring out what query to write as compared to typical API docs” — Sr. Software Engineer at Indeed
Another great GraphQL feature is fragments because it allows to reuse queries at a higher component level. Caching and pagination are easy with Apollo or Relay Modern clients.
These features improve developer experience which in turn makes developers happier and less prone to JavaScript fatigue.
Next post, I’ll cover the improved performance of GraphQL apps.
Improved Performance
Engineers are not the only people benefiting from GraphQL. Users benefit too because performance (real or perceived) can improve due to the following:
- Reduced payload (clients request only things they need without modifications on the backend)
- Multiple requests combined into one which reduces network overhead
- Client caching and backend batching&caching made easier with tooling
- Prefetching (e.g., Apollo prefetching)
- Optimistic UI updates
Don’t just take my word on it. PayPal re-engineered their Checkout with GraphQL. This is what they have to say about improved app performance from the user point of view:
“ REST’s principles don’t consider the needs of Web and Mobile apps and their users. This is especially true in an optimized transaction like Checkout. Users want to complete their checkout as fast as possible. If your applications are consuming atomic REST APIs, you’re often making many round trips from the client to the server to fetch data. With Checkout, we’ve found that every round trip costs at least 700ms in network time (at the 99th percentile), not counting the time processing the request on the server. Every round trip results in slower rendering time, more user frustration and lower Checkout conversion. Needless to say, round trips are evil!” — GraphQL: A success story for PayPal Checkout, PayPal Engineering
One of the items in my performance list was “Multiple requests combined into one which reduced network overhead”. This is very true for HTTP/1 which doesn’t have multiplexing unlike HTTP/2. That’s why front-end engineers concatenate assets. While HTTP/2 multiplexing helps with optimizing independent requests, it is not useful for graph traversal (fetching related or nested objects). Let’s see how REST and GraphQL deal with nested objects and other complex requests next.
Standardized and Simplified Complex APIs
Often clients need to make complex requests to request ordered, sorted, filtered data, sub set (for pagination) or request nested objects. GraphQL supports nested data and other queries that are very hard to implement and consume with standard REST API resources (a.k.a. endpoints, a.k.a. routes).
For example, say there are three resources: users, subscriptions and resumes. Engineers need to make two separate calls sequentially (which slows down performance) to retrieve a user resume based on the resume ID which first needs to be retrieved from the call to the user resource. Same applies to subscriptions.
- GET /users/123: response contains ID of a resume and a list of job alert subscriptions IDs
- GET /resumes/ABC: response contains the resume text — WAITS for request 1.
- GET /subscriptions/XYZ: response contains what and where for the job alert — WAITS for request 1.
The example above is bad for many reasons: clients will probably get too much data and have to wait for sequential dependent requests to resolve. Moreover, clients implement fetching of the sub-resources such as resume or subscription as well as filtering.
Imagine, one client needs only the what and where of the first subscription and the current job title from the resume. Then another client needs the list of all subscriptions and entire resume. The first client will be at a disadvantage if it tries to use the REST API as-is.
Another example: the user table has user first and last names, email, resume, address, phone, SSN, password (salted of course) and other private information. Not every client needs all the fields. Some apps need to have only user email. Sending SSN to these apps when they don’t need it is bad security.
It’s impractical to create a new endpoint for every client such as /api/v1/users and /api/v1/usersMobile. In fact, very often various clients have different data needs: /api/v1/userPublic, /api/v1/userByName, /api/v1/usersForAdmin. The problem gets exponential.
GraphQL lets clients ask APIs for fields they want, and this will make the backend work so much easier: /api/gql —that’s all clients need.
Note: The backend will need to verify access-control level in both cases: REST and GraphQL.
Alternatively, a lot of what GraphQL brings to the table can be achieved with good old REST. But at what cost? A backend can support a complex RESTful request, so that clients can call with fields and nested objects:
GET /users/?fields=name,address&include=resumes,subscriptions
The request above will be a better version than making multiple REST requests for nested objects, but it’s not as standardized, not supported by client libraries and harder for engineers to compose than GraphQL. In almost all relatively complex APIs, engineers will end up with something resembling GraphQL using their own convention of query string parameters as a query. Why design your own query convention around REST when GraphQL already provides the standard and the libraries to do so with much less effort?
Contrast the complex REST endpoint with the following nested GraphQL query that has even more additional filters such as “give me only the first X objects” and “order by the timestamp in ascending order” (unlimited filter options can be implemented):
{
user (id: 123) {
id
firstName
lastName
address {
city
country
zip
}
resumes (first: 1, orderBy: time_ASC) {
text
title
blob
time
}
subscriptions(first: 10) {
what
where
time
}
}
}
}
With GraphQL, we can keep nesting objects in the query and for each object we will get precisely the data that we need, not more, not less. GraphQL engineers use terms over-fetching and under-fetching.
The data shape of the response payload will mirror the request query with something like this:
{
"data": {
"user": {
"id": 123,
"firstName": "Azat",
"lastName": "Mardan",
"address": {
"city": "San Francisco",
"country": "US",
"zip": "94105"
},
"resumes" [
{
"text": "some text here...",
"title": "My Resume",
"blob": "",
"time": "2018-11-13T21:23:16.000Z"
},
],
"subscriptions": [ ]
},
"errors": []
}
An added benefit of using GraphQL over complex REST endpoints is improved security. That’s because URLs are often logged and RESTful GET endpoints rely on query strings (part of URLs). This can expose sensitive data making RESTful GET requests less secure than GraphQL’s POST requests. I bet that’s why Indeed home page makes POST requests for “reading” a page.
Crucial features like pagination are easier to implement with GraphQL because of its queries and the standard used across BaaS providers, backend implementations and client libraries.
Improved Security, Strong Types and Validation
GraphQL schemas are defined in a language-agnostic way. Extending the previous example, we may define the Address type in the schema as:
type Address {
city: String!
country: String!
zip: Int
}
String and Int are built in scalar types. ! indicates a non-nullable field.
Validation against the schema is part of the GraphQL specification, thus a query like this will return an error, since name and phone are not fields of the Address object type:
{
user (id: 123) {
address {
name
phone
}
}
}
While we’re on the subject of types, we can build a complex GraphQL schema using our types. For example, the User type may be utilize our Address, Resumeand Subscription types like so:
type User {
id: ID!
firstName: String!
lastName: String!
address: Address!
resumes: [Resume]
subscriptions: [Subscription]
}
A large number of Indeed objects and types are already defined in ProtoBuf (that Boxcar and gRPC successfully use). Typed data is nothing new and the benefits of typed data are well known. What’s good about GraphQL comparing to inventing a new JSON-typed standard is that there are already libraries that allow automatic conversion from ProtoBufs to GraphQL. Even if one of these libraries (rejoiner?) won’t work, it’s possible to write our own converter so that we have the single truth for types and don’t duplicate work.
GraphQL offers enhanced security over JSON RESTful APIs for two main reasons: a strongly typed schema (e.g., data validation and no SQL injections due to a wrong type) and an ability to define precisely the data clients need (no unintentionally leaked data).
Static validation is another plus that saves engineers time and increase confidence during refactoring. Tools such as eslint-plugin-graphql test GraphQL queries against schemas to warn engineers of any changes on the backend, and for backend engineers to be sure they didn’t break any client code (which happened to me more than several times).
Keeping the contract between frontend and backend is important. REST APIs have to worry about not breaking any clients’ code because clients don’t have any control over the response. Conversely, GraphQL gives the control to the client so GraphQL can update often without introducing breaking changes via new types. GraphQL is a version-less API thanks to schemas.
Next post, I’ll cover the GraphQL implementation and when not to use GraphQL.
GraphQL Implementation
When selecting a platform to implement GraphQL API, Node is a popular environment because initially GraphQL was used for web apps / frontend and Node is a natural choice for web apps because it’s JavaScript. When using Node, GraphQL is very easy to implement (assuming the schema is provided). In fact, with Express or Koa, it’s just a few lines of code:
const Koa = require(‘koa‘);
const Router = require(‘koa-router‘); // koa-router@7.x
const graphqlHTTP = require(‘koa-graphql‘);
const app = new Koa();
const router = new Router();
router.all(‘/graphql‘, graphqlHTTP({
schema: schema,
graphiql: true
}));
app.use(router.routes()).use(router.allowedMethods());
The schemas are defined using types from npm’s graphql. Query and Mutation are special schema type.
 title
title
The bulk of the implementation of a GraphQL API lies in the schemas and resolvers. Resolvers can have any code but most common are the following five main categories:
- Calls to Thrift, gRPC or other RPC services
- Calls to HTTP REST APIs (when it’s not a priority to rewrite existing REST APIs)
- Calls to data stores directly
- Calls to other GraphQL schema queries or services
- Calls to external APIs
The actual code of what to do is either goes into root or in a type in resolvers. Here’s an example (tutorial):
const schema = makeExecutableSchema({
typeDefs: [rootTypeDefs, userTypeDefs],
resolvers: userResolvers,
});
Node is amazing, but at Indeed we use mostly Java. A lot of languages including Java have support for GraphQL and if they lack a library or two, are catching up quickly to Node (https://github.com/graphql-go and https://github.com/graphql-python).
Since Java is the most popular language at Indeed, here’s a Java GraphQL example that uses graphql-java. (The full code is at https://github.com/howtographql/graphql-java.) It defines the /graphqlendpoint:
import com.coxautodev.graphql.tools.SchemaParser;
import javax.servlet.annotation.WebServlet;
import graphql.servlet.SimpleGraphQLServlet;
@WebServlet(urlPatterns = "/graphql")
public class GraphQLEndpoint extends SimpleGraphQLServlet {
public GraphQLEndpoint() {
super(SchemaParser.newParser()
.file("schema.graphqls") //parse the schema file created earlier
.build()
.makeExecutableSchema());
}
}
GraphQL schemas are defined in POJOs. The GraphQL endpoint class uses LinkRepository POJO. The actual code for what to do (e.g., fetch links) is in resolvers:
@WebServlet(urlPatterns = "/graphql")
public class GraphQLEndpoint extends SimpleGraphQLServlet {
public GraphQLEndpoint() {
super(buildSchema());
}
private static GraphQLSchema buildSchema() {
LinkRepository linkRepository = new LinkRepository();
return SchemaParser.newParser()
.file("schema.graphqls")
.resolvers(new Query(linkRepository))
.build()
.makeExecutableSchema();
}
}
In many cases, GraphQL schemas can be generated automatically from other types of schemas such as gRPC, Boxcar, ProtoBuf or ORM/ODM schemas.
GraphQL does NOT require a client. A simple GraphQL request is a regular POST HTTP request with the query in the body. It can be made using any HTTP agent library such as CURL, axios, fetch, superagent and so on. For example, the following works in a terminal:
curl -X POST -H "Content-Type: application/json" --data ‘{ "query": "{ posts { title } }" }‘ https://1jzxrj179.lp.gql.zone/graphql
The following works in any modern browser (to avoid CORS, go to launchpad.graphql.com)
fetch(‘https://1jzxrj179.lp.gql.zone/graphql‘, {
method: ‘POST‘,
headers: { ‘Content-Type‘: ‘application/json‘ },
body: JSON.stringify({ query: ‘{ posts { title } }‘ }),
})
.then(res => res.json())
.then(res => console.log(res.data));
Constructing GraphQL requests is easy, but a lot of things such as caching need to be implemented because caching can greatly improve the user experience. Building client caching is tricky. Luckily, libraries such as Apollo and Relay Modern provide client caching right out of the box.
When Not to Use GraphQL
Of course, there’s no perfect solution (although GraphQL comes close to it). There are valid concerns such as:
- Does it have a single point of failure?
- Can it scale? Does it perform poorly?
- Who owns it?
Conveniently, the answers to some of these concerns already exist: Five Common Problems in GraphQL Apps (And How to Fix Them) and GraphQL at massive scale: GraphQL as the glue in a microservice architecture.
Finally, Here are my own list of the top reasons when GraphQL might not be a good choice:
- When clients needs are simple: if your API is simple, for example /users/resumes/123, then GraphQL will just an unnecessary abstraction
- When resources can and need to be loaded asynchronously for faster loading
- When there are no plans on creating new products using existing APIs instead of building new API specifically for new products
- When there are no plans on exposing APIs to public
- When there are no plans on making UI and other client changes
- When the product is not in active development
- When some other JSON schema or serialization format is used
Wrap Up
In the end, GraphQL is a protocol and a query language. GraphQL API can access data stores directly but for most use cases GraphQL API is a data aggregator and an abstraction layer. The layer that improves velocity of development, decreases maintenance and makes developers happier. For these reasons, GraphQL makes even more sense for a public API. Companies are adopting GraphQL in droves. IBM, PayPal and GitHub claim a big success with GraphQL. If GraphQL is the future, can we already stop building outdated and clunky REST APIs and tap into the convenient awesomeness of GraphQL? Do you want to improve performance of your apps? Do you want you and your engineers to develop faster?
PS: If you are interested in learning Clientside GraphQL with Apollo, then take my short but effective Manning liveVideo course or sign up for Node University.
Why GraphQL is Taking Over APIs
标签:dir pattern component backend set clojure multiple rac mos
原文地址:https://www.cnblogs.com/dadadechengzi/p/10299511.html
下一篇:C#写的window服务内存溢出
文章标题:Why GraphQL is Taking Over APIs
文章链接:http://soscw.com/essay/95560.html