高并发第八弹:J.U.C起航(java.util.concurrent)
2021-06-21 11:06
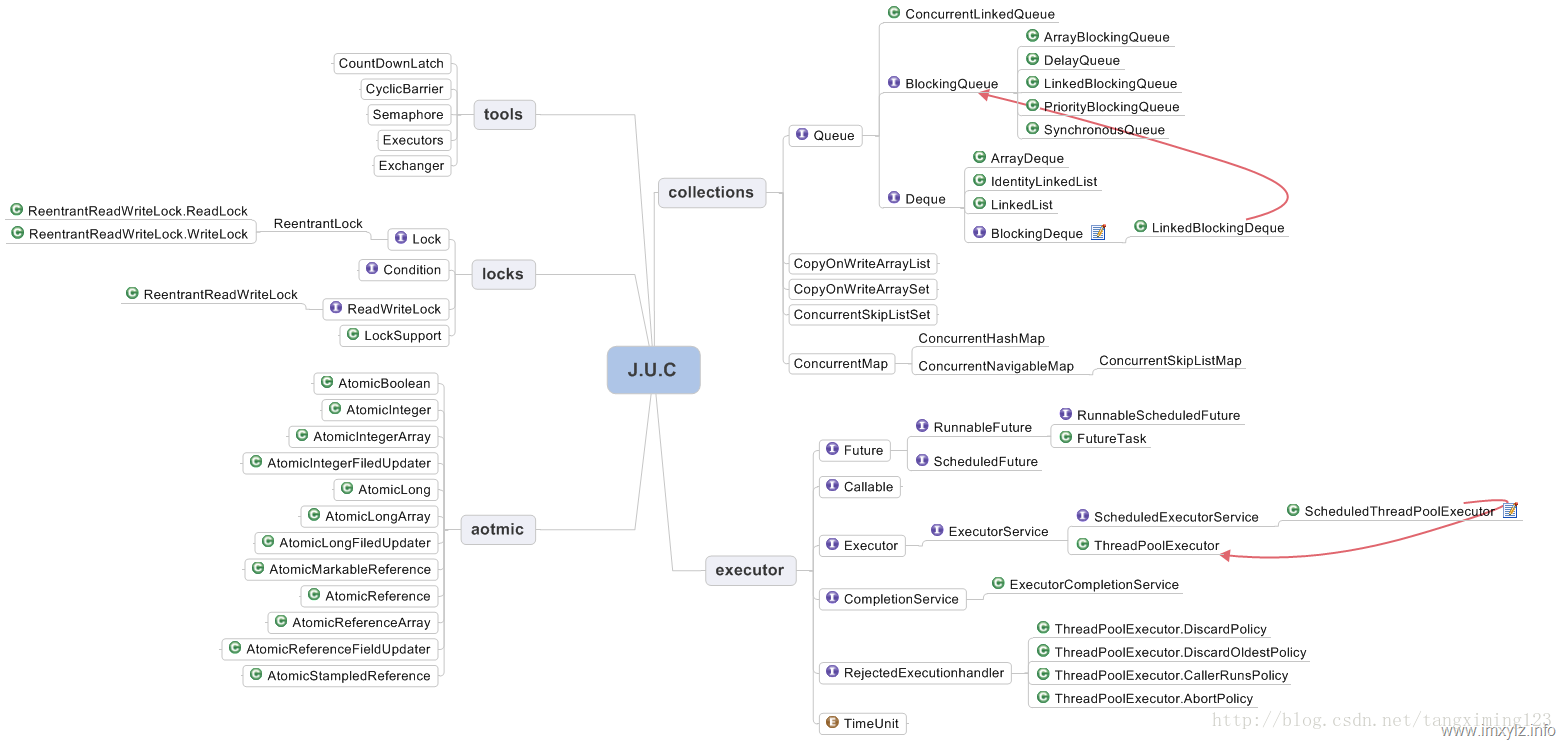
标签:分离 syn 基础 情况下 共享 设计 turn aot 包含 java.util.concurrent是JDK自带的一个并发的包主要分为以下5部分: 我们今天就说说 并发集合,除开 Queue,放在线程池的时候讲 先介绍以下 CopyOnWrite: Copy-On-Write简称COW,是一种用于程序设计中的优化策略。其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容Copy出去形成一个新的内容然后再改,这是一种延时懒惰策略。从JDK1.5开始Java并发包里提供了两个使用CopyOnWrite机制实现的并发容器,它们是CopyOnWriteArrayList和CopyOnWriteArraySet。CopyOnWrite容器非常有用,可以在非常多的并发场景中使用到 . CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。 下面这篇文章验证了CopyOnWriteArrayList和同步容器的性能: http://blog.csdn.net/wind5shy/article/details/5396887 下面这篇文章简单描述了CopyOnWriteArrayList的使用: http://blog.csdn.net/imzoer/article/details/9751591 因为 网友总结的优缺点是: 缺点: 设计思想: 这个还真是主要是针对 读多的条件.毕竟写一个就要开辟一个空间.太耗资源了.其实还是建议用手动的方式来控制集合的并发. 它相当于线程安全的ArrayList。和ArrayList一样,它是个可变数组;但是和ArrayList不同的时,它具有以下特性: 它是线程安全的无序的集合,可以将它理解成线程安全的HashSet。有意思的是,CopyOnWriteArraySet和HashSet虽然都继承于共同的父类AbstractSet;但是,HashSet是通过“散列表(HashMap)”实现的,而CopyOnWriteArraySet则是通过“动态数组(CopyOnWriteArrayList)”实现的,并不是散列表。 介绍的很详细 https://blog.csdn.net/sunxianghuang/article/details/52221913 更优秀的 :https://www.cnblogs.com/skywang12345/p/3498556.html 总结起来就是: 传统意义的单链表是一个线性结构,向有序的链表中插入一个节点需要O(n)的时间,查找操作需要O(n)的时间 跳表查找的复杂度为O(n/2)。跳跃表其实也是一种通过“空间来换取时间”的一个算法,通过在每个节点中增加了向前的指针,从而提升查找的效率。 先以数据“7,14,21,32,37,71,85”序列为例,来对跳表进行简单说明。 跳表分为许多层(level),每一层都可以看作是数据的索引,这些索引的意义就是加快跳表查找数据速度。每一层的数据都是有序的,上一层数据是下一层数据的子集,并且第一层(level 1)包含了全部的数据;层次越高,跳跃性越大,包含的数据越少。 情况1:链表中查找“32”节点 需要4步(红色部分表示路径)。 情况2:跳表中查找“32”节点 忽略索引垂直线路上路径的情况下,只需要2步(红色部分表示路径)。 先以数据“7,14,21,32,37,71,85”序列为例,来对跳表进行简单说明。 跳表分为许多层(level),每一层都可以看作是数据的索引,这些索引的意义就是加快跳表查找数据速度。每一层的数据都是有序的,上一层数据是下一层数据的子集,并且第一层(level 1)包含了全部的数据;层次越高,跳跃性越大,包含的数据越少。 情况1:链表中查找“32”节点 需要4步(红色部分表示路径)。 情况2:跳表中查找“32”节点 忽略索引垂直线路上路径的情况下,只需要2步(红色部分表示路径)。 下面说说Java中ConcurrentSkipListMap的数据结构。 源码我也没精力去详勘了.就总结一下 (01) ConcurrentSkipListSet继承于AbstractSet。因此,它本质上是一个集合。 (4)同其他set集合,是基于map集合的(基于ConcurrentSkipListMap),在多线程环境下,里面的contains、add、remove操作都是线程安全的。 (5)多个线程可以安全的并发的执行插入、移除、和访问操作。但是对于批量操作addAll、removeAll、retainAll和containsAll并不能保证以原子方式执行,原因是addAll、removeAll、retainAll底层调用的还是 contains、add、remove方法,只能保证每一次的执行是原子性的,代表在单一执行操纵时不会被打断,但是不能保证每一次批量操作都不会被打断。在使用批量操作时,还是需要手动加上同步操作的。 (6)不允许使用null元素的,它无法可靠的将参数及返回值与不存在的元素区分开来。 不好意思 虎头蛇尾了.实在扛不住了 高并发第八弹:J.U.C起航(java.util.concurrent) 标签:分离 syn 基础 情况下 共享 设计 turn aot 包含 原文地址:https://www.cnblogs.com/aihuxi/p/9683805.html
public class CopyOnWriteArrayList
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();//获取当前数组数据
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1); //复制当前数组并且扩容+1
newElements[len] = e;
setArray(newElements);//将原来的数组指向新的数组
return true;
} finally {
lock.unlock();
}
}
1.写操作时复制消耗内存,如果元素比较多时候,容易导致young gc 和full gc。
2.不能用于实时读的场景.由于复制和add操作等需要时间,故读取时可能读到旧值。
能做到最终一致性,但无法满足实时性的要求,更适合读多写少的场景。
如果无法知道数组有多大,或者add,set操作有多少,慎用此类,在大量的复制副本的过程中很容易出错。
1.读写分离
2.最终一致性
3.使用时另外开辟空间,防止并发冲突1. ArrayList –> CopyOnWriteArrayList
1. 它最适合于具有以下特征的应用程序:List 大小通常保持很小,只读操作远多于可变操作,需要在遍历期间防止线程间的冲突。
2. 它是线程安全的。
3. 因为通常需要复制整个基础数组,所以可变操作(add()、set() 和 remove() 等等)的开销很大。
4. 迭代器支持hasNext(), next()等不可变操作,但不支持可变 remove()等操作。
5. 使用迭代器进行遍历的速度很快,并且不会与其他线程发生冲突。在构造迭代器时,迭代器依赖于不变的数组快照。 2. HashSet –> CopyOnWriteArraySet
和CopyOnWriteArrayList类似,CopyOnWriteArraySet具有以下特性:
1. 它最适合于具有以下特征的应用程序:Set 大小通常保持很小,只读操作远多于可变操作,需要在遍历期间防止线程间的冲突。
2. 它是线程安全的。
3. 因为通常需要复制整个基础数组,所以可变操作(add()、set() 和 remove() 等等)的开销很大。
4. 迭代器支持hasNext(), next()等不可变操作,但不支持可变 remove()等 操作。
5. 使用迭代器进行遍历的速度很快,并且不会与其他线程发生冲突。在构造迭代器时,迭代器依赖于不变的数组快照。SkipList 跳表:先介绍这个吧
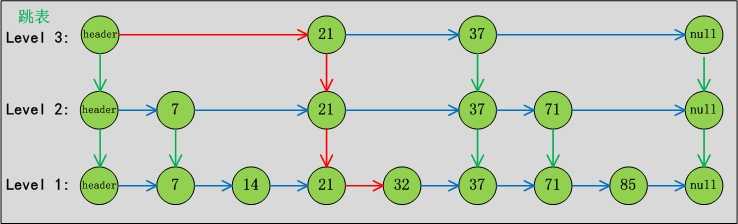
跳表包含一个表头,它查找数据时,是从上往下,从左往右进行查找。现在“需要找出值为32的节点”为例,来对比说明跳表和普遍的链表。
路径如下图1-02所示:![]()
路径如下图1-03所示:
跳表包含一个表头,它查找数据时,是从上往下,从左往右进行查找。现在“需要找出值为32的节点”为例,来对比说明跳表和普遍的链表。
路径如下图1-02所示:![]()
路径如下图1-03所示:3. TreeMap –> ConcurrentSkipListMap
(01) ConcurrentSkipListMap继承于AbstractMap类,也就意味着它是一个哈希表。
(02) Index是ConcurrentSkipListMap的内部类,它与“跳表中的索引相对应”。HeadIndex继承于Index,ConcurrentSkipListMap中含有一个HeadIndex的对象head,head是“跳表的表头”。
(03) Index是跳表中的索引,它包含“右索引的指针(right)”,“下索引的指针(down)”和“哈希表节点node”。node是Node的对象,Node也是ConcurrentSkipListMap中的内部类。 /**
* Special value used to identify base-level header
*/
private static final Object BASE_HEADER = new Object();
/**
* 跳表的最顶层索引
*/
private transient volatile HeadIndex
4. TreeSet –> ConcurrentSkipListSet
(02) ConcurrentSkipListSet实现了NavigableSet接口。因此,ConcurrentSkipListSet是一个有序的集合。
(03) ConcurrentSkipListSet是通过ConcurrentSkipListMap实现的。它包含一个ConcurrentNavigableMap对象m,而m对象实际上是ConcurrentNavigableMap的实现类ConcurrentSkipListMap的实例。ConcurrentSkipListMap中的元素是key-value键值对;而ConcurrentSkipListSet是集合,它只用到了ConcurrentSkipListMap中的key!5. HashMap –> ConcurrentHashMap
安全共享对象策略
文章标题:高并发第八弹:J.U.C起航(java.util.concurrent)
文章链接:http://soscw.com/essay/96880.html