Python | 自然语言处理 (一)
2021-06-22 11:03
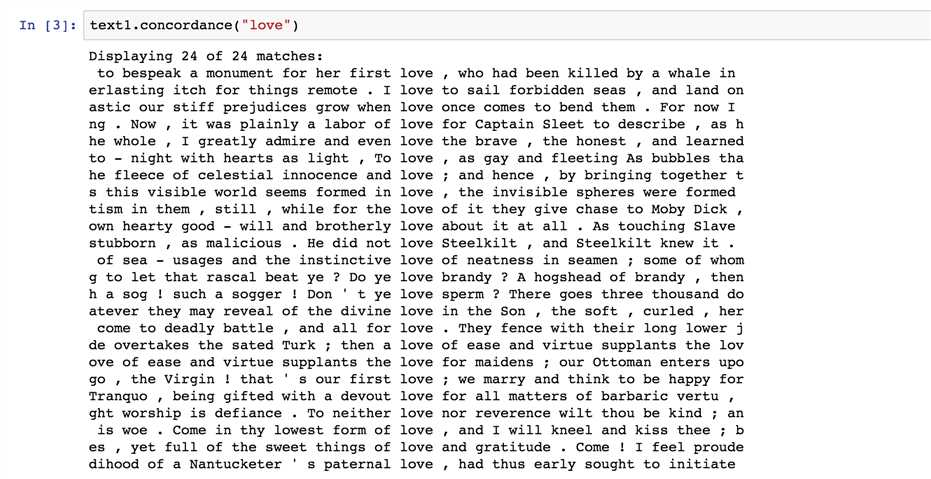
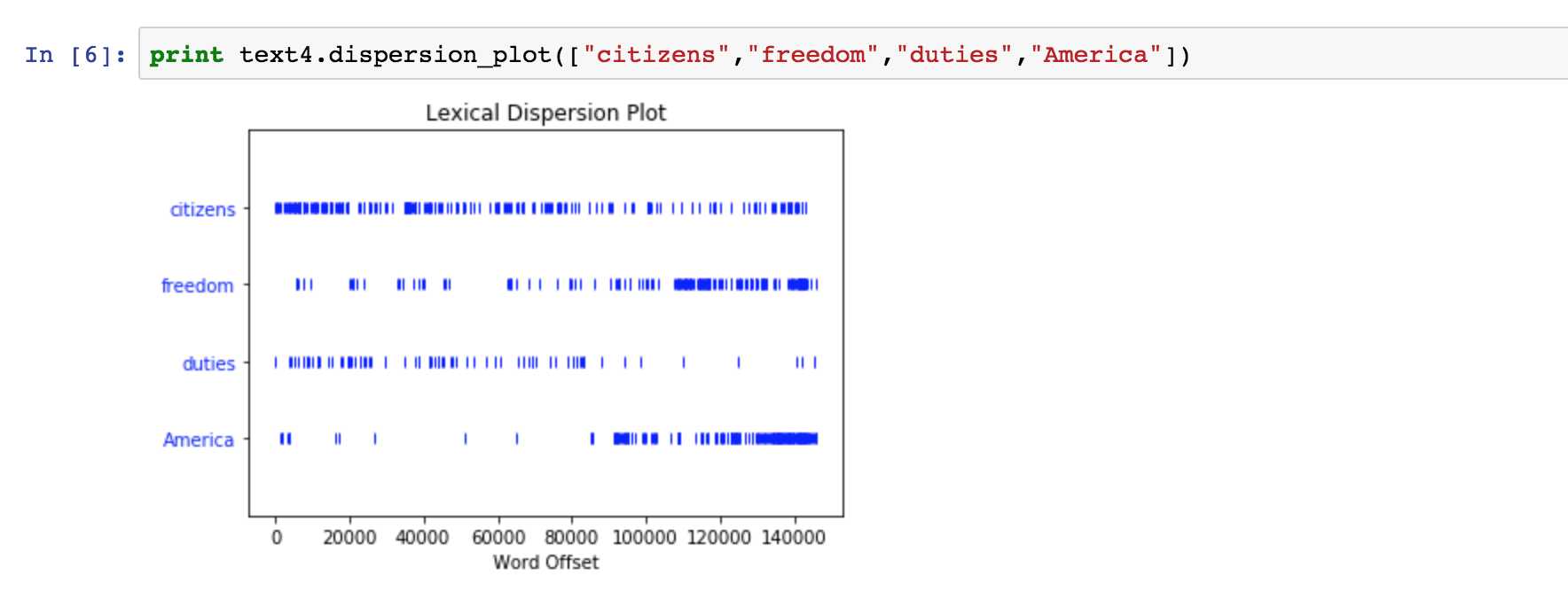
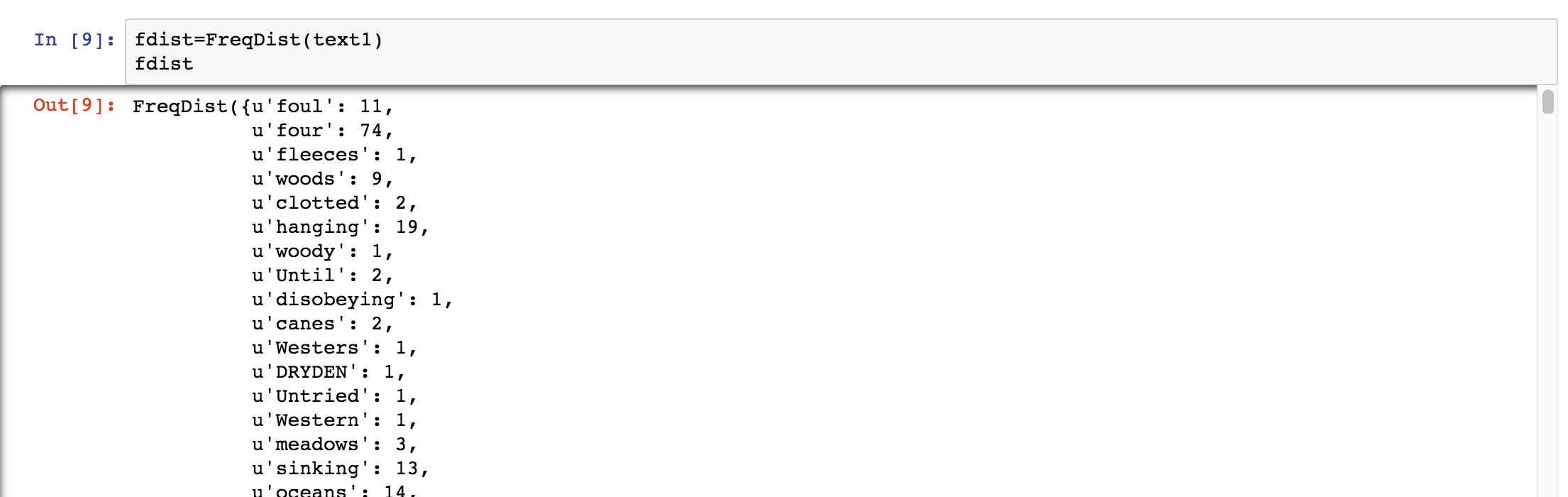
标签:次数 person from load code 文本 height 出现 结果 小白博主最近想参加一个关于NLP的比赛,于是入坑自然语言处理,想借博客一边学习,一边整理 首先安装库nltk,直接pip install nltk即可 这样,证明库已安装,接下来便可以开始我们的学习了: 搜索文本 1.关键词索引:text1.concordance("words") 从文中找到该word 2.用离散图表示词语出现的位置及频繁程度: 计算语言:简单的统计 1.频率分布 从输出结果来看,可以得知fdist为字典类型,键为字符,值为出现的次数 至此,我们先了解了一下ntlk库,和一些基础函数~ 继续加油! Python | 自然语言处理 (一) 标签:次数 person from load code 文本 height 出现 结果 原文地址:https://www.cnblogs.com/Virtual-Z/p/9678511.html1 from nltk.book import *
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: ‘texts()‘ or ‘sents()‘ to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908