数学建模:2.监督学习--分类分析- KNN最邻近分类算法
2021-06-22 20:03
标签:set frame panda pytho lib strong 分类方法 没有 绘制 分类(Classification)指的是从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术,建立分类模型,对于没有分类的数据进行分类的分析方法。 分类问题的应用场景:分类问题是用于将事物打上一个标签,通常结果为离散值。例如判断一副图片上的动物是一只猫还是一只狗,分类通常是建立在回归之上。 本文主要讲基本的分类方法 ----- KNN最邻近分类算法 KNN最邻近分类算法 ,简称KNN,最简单的机器学习算法之一。 核心逻辑:在距离空间里,如果一个样本的最接近的K个邻居里,绝大多数属于某个类别,则该样本也属于这个类别。 最邻近分类的python实现方法 在距离空间里,如果一个样本的最接近的k个邻居里,绝大多数属于某个类别,则该样本也属于这个类别 电影分类 / 植物分类 数学建模:2.监督学习--分类分析- KNN最邻近分类算法 标签:set frame panda pytho lib strong 分类方法 没有 绘制 原文地址:https://www.cnblogs.com/shengyang17/p/9655737.html 1.分类分析
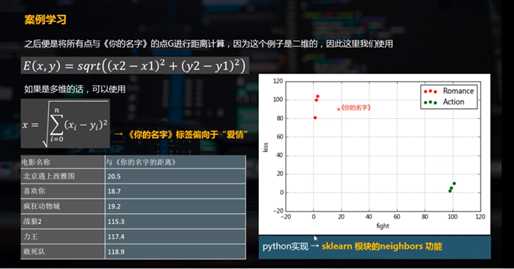
2. KNN最邻近分类的python实现方法
2.1电影分类
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
% matplotlib inline
# 案例一:电影数据分类
from sklearn import neighbors # 导入KNN分类模块
import warnings
warnings.filterwarnings(‘ignore‘)
# 不发出警告
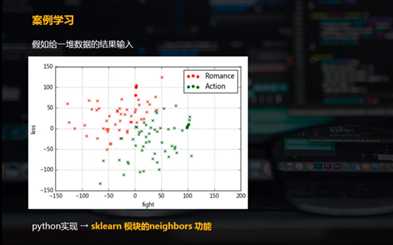
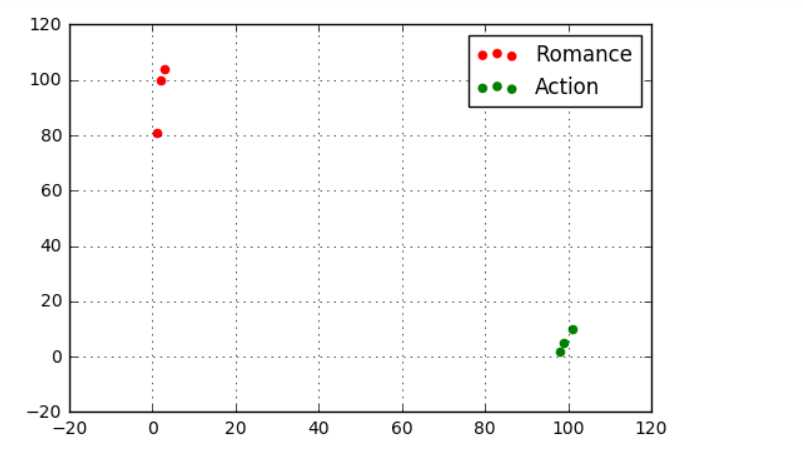
data = pd.DataFrame({‘name‘:[‘北京遇上西雅图‘,‘喜欢你‘,‘疯狂动物城‘,‘战狼2‘,‘力王‘,‘敢死队‘],
‘fight‘:[3,2,1,101,99,98],
‘kiss‘:[104,100,81,10,5,2],
‘type‘:[‘Romance‘,‘Romance‘,‘Romance‘,‘Action‘,‘Action‘,‘Action‘]})
print(data)
print(‘-------‘)
# 创建数据
plt.scatter(data[data[‘type‘] == ‘Romance‘][‘fight‘],data[data[‘type‘] == ‘Romance‘][‘kiss‘],color = ‘r‘,marker = ‘o‘,label = ‘Romance‘)
plt.scatter(data[data[‘type‘] == ‘Action‘][‘fight‘],data[data[‘type‘] == ‘Action‘][‘kiss‘],color = ‘g‘,marker = ‘o‘,label = ‘Action‘)
plt.grid()
plt.legend()
knn = neighbors.KNeighborsClassifier() # 取得knn分类器
knn.fit(data[[‘fight‘,‘kiss‘]], data[‘type‘])

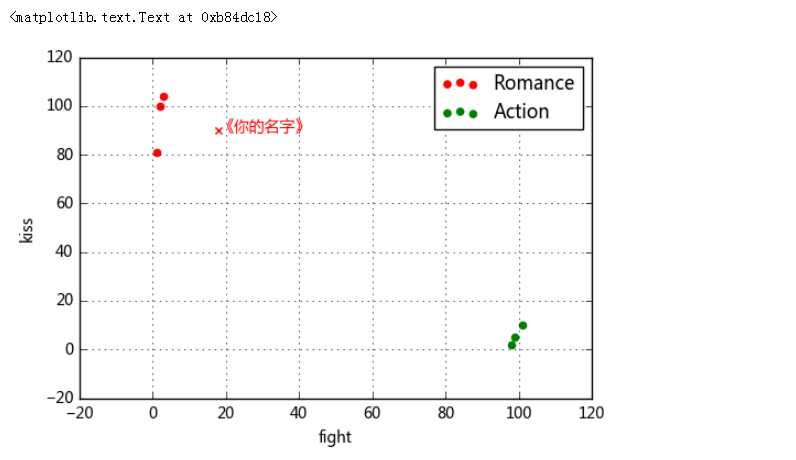
print(‘预测电影类型为:‘, knn.predict([18, 90]))
# 加载数据,构建KNN分类模型
# 预测未知数据

plt.scatter(18,90,color = ‘r‘,marker = ‘x‘,label = ‘Romance‘)
plt.ylabel(‘kiss‘)
plt.xlabel(‘fight‘)
plt.text(18,90,‘《你的名字》‘,color = ‘r‘)
# 绘制图表
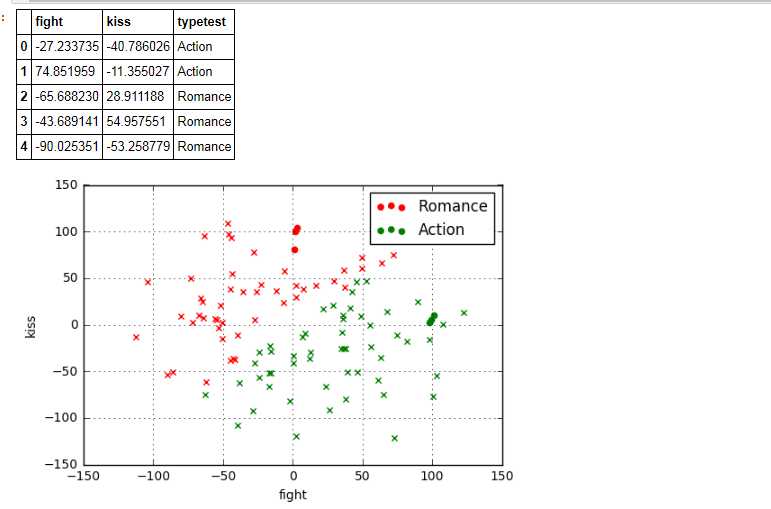
data2 = pd.DataFrame(np.random.randn(100, 2)*50, columns = [‘fight‘, ‘kiss‘])
data2[‘typetest‘] = knn.predict(data2)
plt.scatter(data[data[‘type‘] == ‘Romance‘][‘fight‘],data[data[‘type‘] == ‘Romance‘][‘kiss‘],color = ‘r‘,marker = ‘o‘,label = ‘Romance‘)
plt.scatter(data[data[‘type‘] == ‘Action‘][‘fight‘],data[data[‘type‘] == ‘Action‘][‘kiss‘],color = ‘g‘,marker = ‘o‘,label = ‘Action‘)
plt.grid()
plt.legend() #做一个可视化
plt.scatter(data2[data2[‘typetest‘] == ‘Romance‘][‘fight‘],data2[data2[‘typetest‘] == ‘Romance‘][‘kiss‘],color = ‘r‘,marker = ‘x‘,label = ‘Romance‘)
plt.scatter(data2[data2[‘typetest‘] == ‘Action‘][‘fight‘],data2[data2[‘typetest‘] == ‘Action‘][‘kiss‘],color = ‘g‘,marker = ‘x‘,label = ‘Action‘)
# plt.legend()
plt.ylabel(‘kiss‘)
plt.xlabel(‘fight‘)
# 绘制图表
data2.head()
2.2植物分类
# 案例二:植物分类
from sklearn import datasets
iris = datasets.load_iris()
print(iris.keys())
print(‘数据长度为:%i条‘ % len(iris[‘data‘]))
# 导入数据
print(iris.feature_names)
print(iris.target_names)
#print(iris.target)
print(iris.data[:5])
# 150个实例数据
# feature_names - 特征分类:萼片长度,萼片宽度,花瓣长度,花瓣宽度 → sepal length, sepal width, petal length, petal width
# 目标类别:Iris setosa, Iris versicolor, Iris virginica.
data = pd.DataFrame(iris.data, columns = iris.feature_names)
data[‘target‘] = iris.target
iris.target
data.head()

knn = neighbors.KNeighborsClassifier()
knn.fit(iris.data, iris.target) #构建一个分类模型
prt_data = knn.predict([0.2, 0.1, 0.3, 0.4]) #array([0])
prt_data
ty = pd.DataFrame({‘target‘:[0, 1, 2],
‘target_names‘:iris.target_names})
iris.target
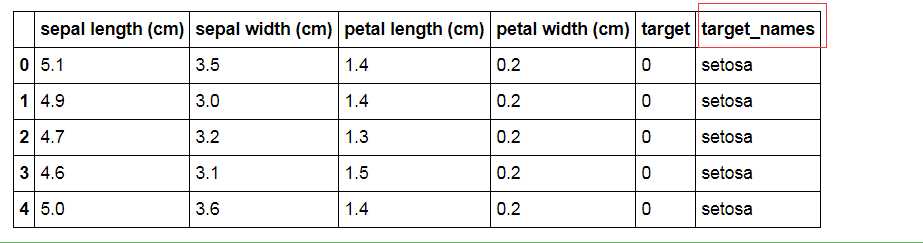
df = pd.merge(data, ty, on = ‘target‘)
df.head()
knn = neighbors.KNeighborsClassifier()
# knn.fit(iris.data, iris.target) #构建一个分类模型
knn.fit(iris.data, df[‘target_names‘]) #监督学习一定要有它的特征量和目标值
prt_data = knn.predict([0.2, 0.1, 0.3, 0.4]) #做预测
prt_data

文章标题:数学建模:2.监督学习--分类分析- KNN最邻近分类算法
文章链接:http://soscw.com/essay/97516.html