J04-Java IO流总结二《 FileReader和FileWriter 》
2021-06-27 17:04
标签:nal static code esc nts 获得 tor 取数据 not FileReader和FileWriter的源码非常简单,下面通过分析它们的源码以更好地进行理解这两个流 FileReader实现了读取底层的字节数据并将其转换为字符数据的功能,转换时依赖的字符集为平台默认的字符集GBK(Windows平台)。 由源码不难看出,FileReader类继承自InputStreamReader类,它自己只提供了几个构造方法,它的构造方法中又通过super来调用父类构造器以构建流对象,它本身没有再提供其他的读取流数据的方法,全部继承它的直接父类InputStreamReader,而InputStreamReader又是继承自Reader类,因此FileReader和InputStreamReader一样,都能使用read()、read(char cbuf[])、read(char cbuf[], int off, int len)方法来读取流数据。 此外,由源码可知,FileReader的读取字符串的功能是通过转换流InputStreamReader类实现的:首先InputStreamReader包装了一个FileInputStream从文件读取字节数据,再将其转换为字符,FileReader继承了InputStreamReader,从而也获得了该功能。我们截取该类的其中一个构造方法的代码出来: 可以看到,在调用父类InputStreamReader转换流的构造方法时,没有显式地指定解码所需的字符集,因此使用的是平台默认字符集来将读到的字节数据转换为字符。因此,FileReader去读取GBK编码的源文件数据时不会出现乱码,而在读取UTF-8等其他字符集编码的文件时就会粗现乱码了。 从该流的API文档同样可以看出这点:FileReader是用来读取字符文件的便捷类。此类的构造方法假定默认字符编码和默认字节缓冲区大小都是适当的。要自己指定这些值,可以先在 FileInputStream 上构造一个 InputStreamReader。 FileReader 用于读取字符流。要读取原始字节流,请考虑使用 FileInputStream。 综上,可知FileReader的本质其实还是字节流! FileReader类使用示例代码: 代码运行效果: 可见,若是使用FileReader从UTF-8文件中读取数据,将会出现乱码,原因我们在上面也说了,是因为FileReader的底层转换流InputStreamReader在将字节数据转换为字符数据时,使用的是平台默认的字符集GBK,与源文件的不一致,由此导致了乱码。 FileWriter实现了将字符数据转换为字节数据的功能。它所依赖的字符集也是平台默认的GBK 。 该流的API文档有如下描述:用来写入字符文件的便捷类。此类的构造方法假定默认字符编码和默认字节缓冲区大小都是可接受的。要自己指定这些值,可以先在 FileOutputStream 上构造一个 OutputStreamWriter。 由FileWriter的源码可以看到,该类的直接父类是转换流OutputStreamWriter,它跟FileReader简直一模一样——自己只提供了几个构造方法,并在它的构造方法中又通过super来调用父类构造器以构建流对象,它本身没有再提供其他的写出流数据的方法,全部继承它的直接父类OutputStreamWriter,而OutputStreamWriter又是继承自Writer类,因此FileWriter和OutputStreamWriter一样,都能使用write(int c)、write(char cbuf[])、write(char cbuf[], int off, int len)、write(String str)、write(String str, int off, int len)方法来写入流数据。 FileWriter流使用示例代码: 代码运行效果: 本次示例中,是将数据写入GBK编码的目标文件中,倘若目标是UTF-8或者其他编码,则写入的数据中文会发生乱码,如下所示: 使用FileReader和FileWriter在两个文件之间相互拷贝文件的操作跟前边的示例差不多,这里不再写了。 FileInputStream、FileOutputStream、FileReader和FileWriter都是跟磁盘文件有关的字节流,但凡需要跟磁盘文件进行I/O操作的,必将使用到它们中的其中一个!需要根据读取的是字节流还是字符流来进行相应的选择。 J04-Java IO流总结二《 FileReader和FileWriter 》 标签:nal static code esc nts 获得 tor 取数据 not 原文地址:https://www.cnblogs.com/suhaha/p/9651484.html1. FileReader
FileReader源码如下:
public class FileReader extends InputStreamReader {
public FileReader(String fileName) throws FileNotFoundException {
super(new FileInputStream(fileName));
}
public FileReader(File file) throws FileNotFoundException {
super(new FileInputStream(file));
}
public FileReader(FileDescriptor fd) {
super(new FileInputStream(fd));
}
}
public FileReader(String fileName) throws FileNotFoundException {
super(new FileInputStream(fileName));
}
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
public class FileReaderTest {
public static void main(String[] args) {
System.out.println("【从GBK文件读取到的内容】:");
test1();
System.out.println("\n\n【从UTF-8文件读取到的内容】:");
test2();
}
////////////////////////////////////////////////////////////
/**
* 使用FileReader从编码为GBK的源文件1.txt中读取数据,能正确读取
*/
private static void test1() {
FileReader fr = null;
try {
fr = new FileReader("./src/res/1.txt");
int value = 0;
while(-1 != (value = fr.read())) { //使用read()方法读取
System.out.print((char)value);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(null != fr) {
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
////////////////////////////////////////////////////////////
/**
* 使用FileReader从编码为utf-8的源文件2.txt中读取数据,将出现乱码
*/
private static void test2() {
FileReader fr = null;
try {
fr = new FileReader("./src/res/2.txt");
int len = 0;
char[] buf = new char[1024]; //注意这里是字符数组!!
while(-1 != (len = fr.read(buf))) { //使用read(char cbuf[])方法读取
System.out.println(new String(buf));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(null != fr) {
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
【从GBK文件读取到的内容】:
hello java hello hello 中国
【从UTF-8文件读取到的内容】:
hello java hello hello 涓浗
2. FileWriter
FileWriter源码如下:
public class FileWriter extends OutputStreamWriter {
public FileWriter(String fileName) throws IOException {
super(new FileOutputStream(fileName));
}
public FileWriter(String fileName, boolean append) throws IOException {
super(new FileOutputStream(fileName, append));
}
public FileWriter(File file) throws IOException {
super(new FileOutputStream(file));
}
public FileWriter(File file, boolean append) throws IOException {
super(new FileOutputStream(file, append));
}
public FileWriter(FileDescriptor fd) {
super(new FileOutputStream(fd));
}
}
import java.io.FileWriter;
import java.io.IOException;
public class FileWriterTest {
public static void main(String[] args) {
FileWriter fw = null;
try {
fw = new FileWriter("./src/res/3.txt");
String str1 = "hello java";
String str2 = "中国";
char[] array = str1.toCharArray();//将字符串转换为字符数组
fw.write(str1, 0, 5); //写入:hello
fw.write(str2); //写入:中国
fw.write(array); //写入:hello java
fw.write(array, 6, 4); //写入:java
} catch (IOException e) {
e.printStackTrace();
} finally {
if(null != fw) {
try {
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
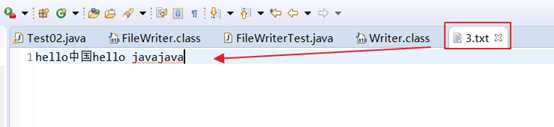
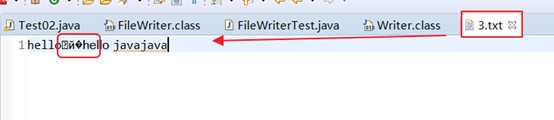
3. 小结
文章标题:J04-Java IO流总结二《 FileReader和FileWriter 》
文章链接:http://soscw.com/essay/98507.html