八、window搭建spark + IDEA开发环境
2021-06-27 19:05
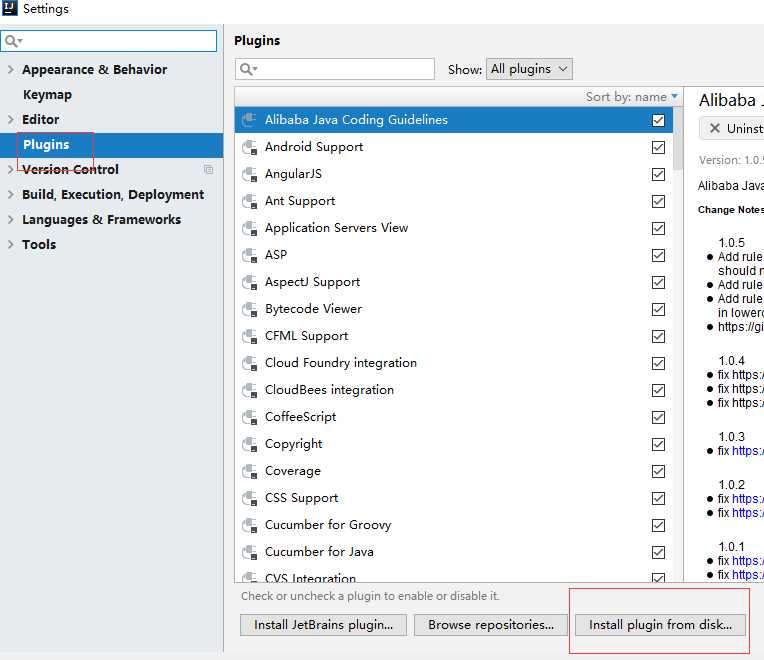
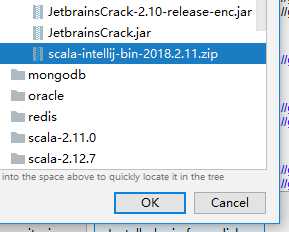
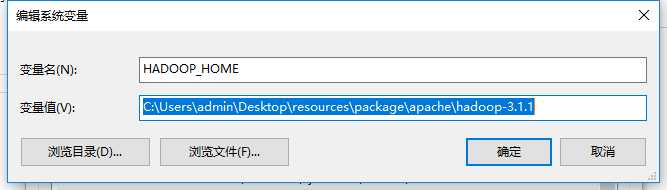
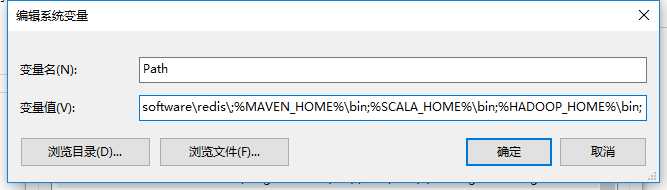
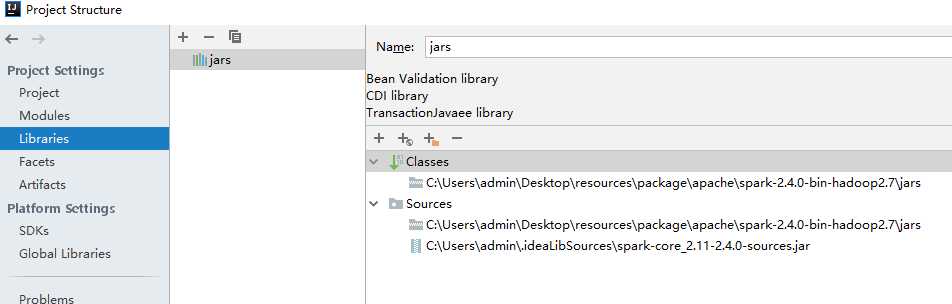
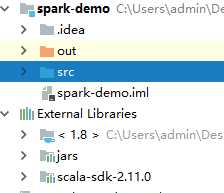
标签:and 文件 java 工具包 intellij this www. get apach 本文将简单搭建一个spark的开发环境,如下: 1)操作系统:window os 2)IDEA开发工具以及scala插件(IDEA和插件版本要对应): 2-1)IDEA2018.2.1:https://www.jetbrains.com/ 2-2)scala-intellij-bin-2018.2.11.zip :http://plugins.jetbrains.com/plugin/1347-scala 3)scala和Java语言的开发包(spark2.4.0对应的可用版本): 5-1)scala2.11 https://www.scala-lang.org/download/2.11.12.html 5-2)JDK1.8 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 4)spark开发包:spark2.4.0 http://spark.apache.org/downloads.html 我这里下载的是pre-built for apache hadoop 2.7 and later的类型,支持hadoop2.7+的版本 5)hadoop以及hadoop在window运行的工具包(hadoop和winutils版本要对应,winutils比较麻烦如果网上找不到对应的版本需要自己编译): 4-1)hadoop3.1.1 https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.1.1/hadoop-3.1.1.tar.gz 4-2)winutils3.1.1 https://files.cnblogs.com/files/lay2017/apache-hadoop-3.1.1-winutils-master.zip 注意:spark开发环境对其相关依赖是有版本要求的 本文默认你已经安装好了IDEA并配置好scala,JDK环境 file -> setting从硬盘安装 找到你下载的scala插件,安装并重启IDEA 我们先把winutils的bin目录下的所有文件覆盖到hadoop的bin目录下,这样hadoop就能支持在windows上运行了。 然后我们把hadoop设置到系统环境变量中,如: 设置HADOOP_HOME 设置PATH 注意:设置hadoop环境变量需要重启计算机 我们直接搭建一个scala的IDEA项目 与一般的其它项目创建步骤一模一样,一步步填写下去 当项目搭建完毕,我们需要把spark的开发包引入项目; 从file -> project structure把spark的所有开发(整个jars文件夹)包引入到项目中;在spark2.0以后原先的一个独立开发包已经被拆分成了很多单独的小包,所以这里引入整个文件夹 这样我们就有了一个简单的spark程序结构,包括了spark包、JDK包、scala的包 我们简单地使用wordCount程序来测试一下spark是否可用 首先,我们在src目录下新建一个cn.lay的文件目录,在该目录下我们建立一个WordCount.scala文件,编写如下代码: 代码解释:我们先创建了一个sparkContext,基于sparkContext去读取了本地文件word.txt,然后经过一系列的RDD计算,最后打印并关闭sparkContext 注意: 1)这里setMaster("local")意思是将spark运行在本地,这样我们就不用一个独立的spark集群,直接在本地开发环境运行spark; 2)而之前我们配置了hadoop的环境变量,就不用在程序中指定hadoop的根路径了 新建一个文件夹C:\\Users\\admin\\Desktop\\word.txt,文件内容如: 然后直接运行main方法,控制台输出如: 八、window搭建spark + IDEA开发环境 标签:and 文件 java 工具包 intellij this www. get apach 原文地址:https://www.cnblogs.com/lay2017/p/10063573.html
安装scala插件
安装hadoop环境
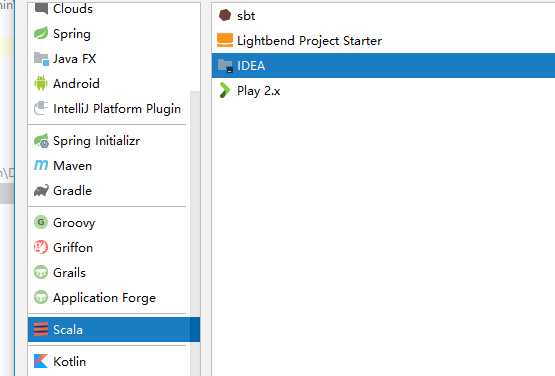
搭建scala项目
测试代码
package cn.lay
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Description 字数统计
* @Author lay
* @Date 2018/12/03 22:46
*/
object WordCount {
def main(args: Array[String]): Unit = {
// 创建SparkConf
val conf = new SparkConf().setAppName("WordCount").setMaster("local");
// 创建SparkContext
val sc = new SparkContext(conf);
// 输入文件
val input = "C:\\Users\\admin\\Desktop\\word.txt";
// 计算频次
val count = sc.textFile(input).flatMap(x => x.split(" ")).map(x => (x, 1)).reduceByKey((x, y) => x + y);
// 打印结果
count.foreach(x => println(x._1 + ":" + x._2));
// 结束
sc.stop()
}
}
this is a word count demo

上一篇:超好用的C#控制台应用模板